Estimer la probabilité qu'une pièce apparaisse en utilisant MCMC
Estimer la probabilité qu'une pièce apparaisse en utilisant MCMC
Aperçu
Pour étudier MCMC. Comme exemple le plus simple, j'ai essayé de trouver la distribution postérieure des paramètres dans le processus de Bernoulli en utilisant MCMC et distribution bêta.
Présentation du MCMC
Méthode MCMC (Markov Chain Monte Carlo) en statistique bayésienne Est une méthode pour trouver la distribution postérieure en utilisant des nombres aléatoires.
La distribution postérieure utilise le théorème de Bayes
Distribution postérieure = (probabilité * distribution antérieure) / (probabilité d'obtenir des données)
Peut être obtenu par. Le problème ici est que la probabilité p (D) à laquelle les données du dénominateur du côté droit peuvent être obtenues peut être obtenue en intégrant et en éliminant à l'aide du paramètre $ \ theta $. Cependant, à mesure que le nombre de dimensions du paramètre augmente, plusieurs intégrations multiples doivent être effectuées. Il est possible d'obtenir une valeur intégrée approximative en utilisant la méthode statique de Monte Carlo, mais la précision diminue à mesure que le nombre de dimensions augmente. Par conséquent, MCMC a renoncé à calculer la probabilité d'obtenir des données et n'a estimé la distribution postérieure qu'à partir de la probabilité et de la distribution antérieure.
MCMC vous permet d'obtenir un échantillon proportionnel à la valeur de la fonction. Par conséquent, si la distribution a priori de vraisemblance * est échantillonnée par MCMC et normalisée de sorte que la valeur intégrée devienne 1, elle devient la distribution a posteriori.
Cette fois, nous trouverons la fonction de densité de probabilité que la pièce apparaît à partir des données obtenues en lançant la pièce plusieurs fois, ce qui est le cas le plus simple à étudier.
Responsabilité
Laissez la probabilité que les pièces apparaissent comme $ \ mu $ Supposons que Cointos obtienne un {0,1} ensemble D dans une tentative indépendante.
À ce moment, la probabilité est
Distribution antérieure
La distribution antérieure prend une valeur uniforme car elle ne dispose d'aucune information préalable sur la pièce. Soit p ($ \ mu $) = 1.
Distribution ex post
Utiliser MCMC
L'échantillonnage est effectué en bouclant un nombre prédéterminé de fois selon la procédure suivante.
- Sélectionnez la valeur initiale du paramètre $ \ mu $
- Déplacez au hasard $ \ mu $ un petit montant pour obtenir $ \ mu_ {new} $
- Si (probabilité * distribution antérieure) devient grande suite au déplacement, mettez à jour $ \ mu $ en $ \ mu_ {new} $ pour la valeur déplacée → passez à 2.
- (Responsabilité*Distribution antérieure)Si devient plus petit(P(D|
\mu_{new} )P(\mu_{new} )/(P(D|\mu )P(\mu )Avec une probabilité de\mu Mettre à jour → 2.Quoi
L'histogramme de l'échantillon obtenu est intégré et normalisé à 1 pour obtenir la distribution postérieure.
Rechercher analytiquement
Puisque ce modèle est un processus de Bernoulli, en supposant que la distribution bêta est une distribution a priori, La distribution postérieure peut être obtenue simplement en mettant à jour les paramètres de distribution bêta.
Soit m le nombre de fois où le recto de la pièce apparaît, l le nombre de fois où le verso apparaît, et soit a et b des paramètres prédéterminés.
$p(\mu|m,l,a,b) = beta(m+a,l+b) $
Sera. Si la distribution antérieure est une distribution antérieure sans information, définissez a = b = 1.
programme
Je l'ai écrit en python. Je pense que cela fonctionnera si l'anaconda est inclus. Ce n'est pas du tout rapide car il met l'accent sur la lisibilité.
# coding:utf-8
from scipy.stats import beta
import matplotlib.pyplot as plt
import numpy as np
def priorDistribution(mu):
if 0 < mu < 1:
return 1
else:
return 10 ** -9
def logLikelihood(mu, D):
if 0 < mu < 1:
return np.sum(D * np.log(mu) + (1 - D) * np.log(1 - mu))
else:
return -np.inf
np.random.seed(0)
sample = 0.5
sample_list = []
burnin_ratio = 0.1
N = 10
# make data
D = np.array([1, 0, 1, 1, 0, 1, 0, 1, 0, 0])
l = logLikelihood(sample, D) + np.log(priorDistribution(sample))
# Start MCMC
for i in range(10 ** 6):
# make candidate sample
sample_candidate = np.random.normal(sample, 10 ** -2)
l_new = logLikelihood(sample_candidate, D) + \
np.log(priorDistribution(sample_candidate))
# decide accept
if min(1, np.exp(l_new - l)) > np.random.random():
sample = sample_candidate
l = l_new
sample_list.append(sample)
sample_list = np.array(sample_list)
sample_list = sample_list[int(burnin_ratio * N):]
# calc beta
x = np.linspace(0, 1, 1000)
y = beta.pdf(x, sum(D) + 1, N - sum(D) + 1)
plt.plot(x, y, linewidth=3)
plt.hist(sample_list, normed=True, bins=100)
plt.show()
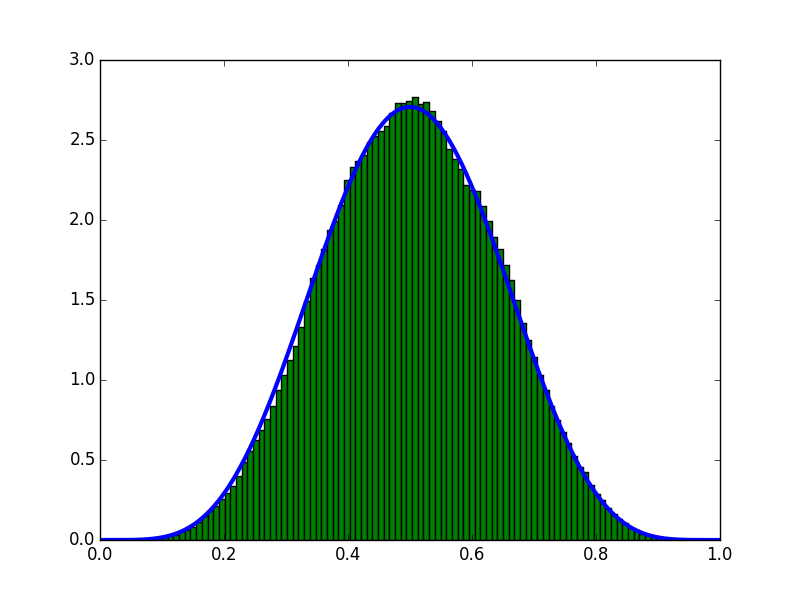
Résultat d'exécution
Estimé à la condition que 10 échantillons (5 à l'avant et 5 à l'arrière) aient été obtenus.
La ligne bleue est le graphique obtenu analytiquement et l'histogramme est le graphique obtenu par MCMC.
Si vous regardez le graphique, vous pouvez voir qu'il est bien estimé.
Résumé
Cette fois, j'ai trouvé les paramètres de la distribution de Bernoulli en écrivant à la main en python et en utilisant MCMC, qui est une méthode très inefficace. C'était un paramètre problématique qui ne pouvait pas bénéficier du MCMC sans distribution préalable d'information et une variable avec une zone de définition de [0,1], mais si la vraisemblance (modèle) peut être définie, la distribution postérieure peut être envoyée à un ordinateur personnel. J'ai pu imaginer que je pouvais l'obtenir.
Lorsque vous utilisez réellement MCMC, il est judicieux d'utiliser une bibliothèque optimisée telle que Stan ou PyMC.
En jouant avec différentes distributions et paramètres antérieurs, vous pourrez peut-être comprendre les propriétés uniques de l'estimation bayésienne, telles que plus le nombre de données observées est grand, plus la largeur de la distribution est petite et moins l'effet de la distribution antérieure est faible.
Les références
Introduction à la modélisation statistique pour l'analyse des données http://hosho.ees.hokudai.ac.jp/~kubo/stat/2013/ou3/kubostat2013ou3.pdf http://tjo.hatenablog.com/entry/2014/02/08/173324