Commencer l'apprentissage en profondeur
Oui, faisons du Deep Learning. Ceci est un article de commentaire à vous envoyer. En disant cela, j'écris tout en étudiant moi-même, il peut donc y avoir des erreurs et des malentendus. Si vous en trouvez un, veuillez nous contacter.
Qu'est-ce que le Deep Learning?
Cette diapositive est très bien organisée.
Après tout, je pense que la caractéristique du Deep Learning est qu'il en extrait même les caractéristiques. Par exemple, si vous souhaitez créer un modèle pour juger de la lutte sumo, vous définissez généralement des caractéristiques telles que «tour de taille», «présence ou absence de mage» et «si vous portez ou non des vêtements japonais» et créez un modèle basé sur cela. C'est comme décider de l'argument d'une fonction.
Cependant, dans le Deep Learning, cette extraction de fonctionnalités est également effectuée par le modèle. Ou plutôt, c'est pourquoi il est multicouche ou profond. Plus précisément, apprenons les caractéristiques autour de la tête, les caractéristiques autour de la taille et les caractéristiques du haut du corps qui les combinent, etc. en parallèle et en plusieurs couches, et faisons un jugement avec. C'est l'idée de base (ci-dessous, image).

Comme le montre la figure, l'apprentissage en profondeur peut diviser les éléments techniques qui le composent comme suit.
- Répartition des données Comment diviser les données utilisées pour le jugement. Dans le cas du jugement d'image, combien de pixels l'image doit-elle être divisée par combien de pixels?
- Extraction de caractéristiques
- Modèle utilisé pour l'extraction de caractéristiques Le modèle utilisé pour extraire les fonctionnalités. Des exemples typiques sont les machines Autoencoder et Boltzmann restreintes. Chacun de ces modèles est généralement pré-formé (pré-formation).
- Méthode de propagation des caractéristiques extraites Vers quel nœud et comment transmettre les entités extraites. Par exemple, si toutes les entités extraites sont transmises au nœud suivant, l'erreur se propagera également, donc ajustez cela.
- Jugement: faites un jugement final à partir des fonctionnalités extraites En fait, ce n'est plus un réseau neuronal, mais un classificateur général tel que SVM peut être utilisé.
Ce qui suit expliquera chaque élément.
Répartition des données
Les données à analyser, telles que les données et l'audio, contiennent diverses caractéristiques. Le plus idéal est de diviser sous la forme de 1 donnée et 1 fonctionnalité, mais il est difficile de le faire sans savoir quelle est la fonctionnalité, il est donc important de diviser les données pour ne pas perdre la fonctionnalité autant que possible. Devenir.
Par exemple, si le facteur le plus important dans la détermination de la lutte sumo est la présence ou l'absence d'un "mage", il est très important que ce "mage" tienne dans l'image divisée. En effet, si le mage est à la limite de l'image divisée, il ne sera pas possible de juger.
Une approche courante consiste à couvrir (chevaucher) les données dans une certaine mesure plutôt que de simplement les diviser. L'unité qui divise une image s'appelle une fenêtre, et l'image est que cette fenêtre est progressivement décalée. En termes de chaînes de caractères, si les données sont ABCDE, la taille de la fenêtre est de 3 et la largeur de mouvement est de 1, les données seront considérées comme "ABC", "BCD" et "CDE".
- Cela ne se limite pas à l'apprentissage en profondeur.
Extraction de fonctionnalités
La principale caractéristique de l'apprentissage profond est qu'il peut extraire les fonctionnalités elles-mêmes. Alors, comment cela se fait-il?
Modèle utilisé pour l'extraction de caractéristiques
L'idée de base est un Autoencoder. Ce qui suit est une explication facile à comprendre sur Autoencoder. C'est une image qui crée un modèle avec la même entrée et sortie et l'entraîne de sorte que l'entrée puisse être reproduite avec des fonctionnalités limitées.
Parallèlement à cela, la machine Boltzmann restreinte est souvent utilisée. En gros, il s'agit d'un modèle probabiliste qui estime la distribution de probabilité à l'origine des données d'entrée. L'explication est facile à comprendre ici.
2012-12-12 Yurufuwa Restricted Boltzmann Machine
Les deux sont essentiellement les mêmes en ce sens qu'ils «recherchent des paramètres qui peuvent bien expliquer les données données» (Référence 1. -machine-different-from-an-autoencoder-Arent-both-of-them-learning-high-level-features-in-an-unsupervised-way-Similairement-comment-est-un-Deep-Belief-Network-different -from-a-network-of-stacked-Autoencoders), Référence 2) ..
En Deep Learning, ceux-ci sont formés individuellement (pré-formation) et combinés. La première couche est pour chaque personne et la deuxième couche est destinée à l'apprentissage après avoir fixé les paramètres de la première couche. L'image est similaire à un test unitaire utilisant des stubs. Ce pré-apprentissage surmonte la faiblesse des réseaux de neurones multicouches, où la propagation des erreurs ne fonctionne pas bien à mesure que les couches deviennent plus profondes (elle se propage à partir des couches supérieures, ce qui rend difficile d'atteindre les couches inférieures).
Méthode de propagation des entités extraites
La question suivante est de savoir comment atteindre la couche suivante. Ici, comme mentionné ci-dessus, il y a un compromis entre la propagation des informations et la propagation des erreurs. (Dans ce qui suit, chaque modèle d'apprentissage sera appelé un nœud).
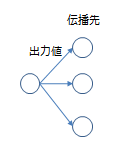
Valeur de sortie (fonction d'activation)
Tout d'abord, déterminez comment calculer la valeur à propager à la couche suivante (nœud). Semblables aux réseaux neuronaux généraux, les fonctions sigmoïdes sont souvent utilisées, mais il semble que les unités linéaires rectifixées soient également utilisées de nos jours. De plus, maxout et Lp Pooling sont également utilisés. Celles-ci déterminent la valeur en combinant plusieurs sorties, maxout est la valeur maximale comme son nom l'indique, Lp Pooling est ... Il délivre une valeur sympa qui ne peut être dite en un mot. Veuillez consulter [Lp pooling](http://ceromondo.blogspot.jp/2012/10/lp- Covoiturage.html) pour cela. Les bords fins d'une image ont moins de nœuds qui peuvent les détecter, ce qui rend difficile la propagation des informations, mais ce sont des techniques pour empêcher la fuite d'informations aussi minuscules (grosso modo).
Méthode de propagation
La manière de définir la destination de propagation est également une considération. Le moyen le plus simple est de le propager à tous les nœuds de la couche suivante, tout comme un réseau de neurones. Cependant, si tel est le cas, une propagation d'erreur se produira naturellement et un surapprentissage peut se produire. Pour résoudre ce problème, des méthodes telles qu'un système réceptif local qui limite les nœuds de connexion et un abandon qui détermine les nœuds qui ne se propagent pas au hasard ont été conçues.
En les décidant et en connectant chaque nœud, le "modèle d'extraction de caractéristiques pré-appris" (nœud) est finalement assemblé en couches. Le jugement final sera rendu en utilisant les caractéristiques extraites par celui-ci.
Jugement
Le jugement final sera rendu, et la formation pour ce jugement final s'appelle la formation fine. Naturellement, il s'agit d'une étude supervisée. Vous pouvez le construire avec un réseau de neurones jusqu'à la fin et l'ajuster par la méthode de propagation d'erreur, ou attacher SVM au sommet et l'entraîner.
Ce qui précède est l'explication du mécanisme de l'apprentissage profond.
Utilisez l'apprentissage en profondeur
Comme certains d'entre vous l'ont peut-être remarqué, le Deep Learning n'est pas vraiment une nouvelle technologie, c'est une bonne combinaison de réseaux de neurones existants. Par conséquent, si vous voulez l'implémenter, vous pouvez le faire vous-même ... mais c'est vraiment difficile, donc je pense qu'il vaut mieux avoir une bibliothèque.
Bibliothèque
La mise en œuvre est ici très bien organisée. Mise en œuvre Deep Learning
Les bibliothèques typiques sont les suivantes.
- TensorFlow
- Chainer
- Caffe
- Basé sur Theano
- Lasagne
- Keras * Fonctionne avec la base TensorFlow
- Blocks * Depuis décembre 2015, il est toujours en cours de développement.
- pylearn2 * Développement arrêté
Google a annoncé TensorFlow, et j'ai le sentiment qu'il se concentrera sur cela. Keras prend en charge TensorFlow, et un wrapper qui peut être utilisé comme scikit-learn (skflow) est apparu, et le développement périphérique est également actif. Dans l'image, Caffe était la sagesse précédente, mais dans Chainer, un modèle formé avec le modèle de Caffe (Model Zoo) est publié. L'avantage dans ce domaine peut disparaître, tel que La fonction d'importation est implémentée. Caffe peut ne pas être facile à installer (de nombreux problèmes sont liés à l'installation) et aux conditions périphériques telles que la prise en charge non-Python 3, de sorte que la migration peut se poursuivre au fur et à mesure que la fonction d'importation de modèle et la distribution des modèles formés dans d'autres bibliothèques progressent. Je pense que le sexe est élevé.
De plus, le support Python3 qui vous intéresse est le suivant.
- Pris en charge depuis TensorFlow: 0.6.0 (Ajout de la prise en charge de Python 3.x). Veuillez noter que TensorFlow ne fonctionne pas sous Windows (Actuellement pris en charge).
- Chainer: Pris en charge à partir de la version 1.1.0
- Caffe: Aucun plan de support. Cependant, je m'en soucie, [Cela ne fonctionne pas](https://github.com/BVLC/ ressemble à caffe / pull / 1966)
- Theano: la prise en charge de la base de code unique est terminée au moins en juin 2015 (Document d'installation python3)
- pylearn2: [Merge Python3 compatible code] le 15/11/2014 (https://github.com/lisa-lab/pylearn2/issues/948)
Je n'ai pas examiné les autres, mais de nombreuses bibliothèques le font. Étant donné que le problème qui a pris la tête de TensorFlow était compatible avec Python3, je ne pense pas que Python2 ne se répandra que dans le futur.
Si vous souhaitez l'implémenter vous-même au lieu d'une bibliothèque, de nombreuses bibliothèques sont basées sur Theano et [Machines Boltzmann restreintes] Je pense que scikit-learn avec (http://scikit-learn.org/stable/modules/neural_networks.html) aidera. yusugomori / DeepLearning est un référentiel qui implémente l'apprentissage en profondeur dans diverses langues, et je pense que ce code source sera également utile.
Données d'entraînement
L'endroit où apporter les données de formation est également l'un des problèmes de l'apprentissage automatique. Il est difficile d'obtenir des dizaines de milliers de données par vous-même, et il est décourageant de les étiqueter pour un apprentissage supervisé. C'est pourquoi il existe des sites qui fournissent des données d'apprentissage, alors merci de les utiliser.
-
Cependant, si vous souhaitez l'utiliser dans votre application, vous devez souvent préparer vous-même les données, ce qui entraîne un travail régulier et trouble.
-
MNIST
Il s'agit d'exemples de données de caractères manuscrits. -
CIFAR-10
Une collection d'images labellisées en 10 classes (avion, automobile, etc.). Il existe également une étiquette plus détaillée appelée CIFAR-100. -
The Oxford-IIIT Pet Dataset
Comme CIFAR-10, des données étiquetées. Comme son nom l'indique, c'est un système animal. -
kaggle
Site de concours d'analyse de données. Vous pouvez rivaliser pour la précision du modèle et les données sont également fournies. Vous pouvez désormais rechercher et publier des données dans Kaggle Datasets. -
Microsoft Azure Marketplace
Diverses données telles que les résultats des matchs NFL et les données démographiques sont fournies (certaines sont payantes, mais beaucoup sont gratuites). -
UC Irvine Machine Learning Repository
Un site qui collecte des ensembles de données pour l'apprentissage automatique. -
Harvard Dataverse
Un ensemble de données publié par l'Université de Harvard. Il est publié à l'aide d'un logiciel appelé Dataverse, et vous pouvez voir que ce site publie également des données à l'aide de ce logiciel. -
COCO
Ensemble de données tel que la reconnaissance d'image et les légendes des images publiées par Microsoft (ceci est utilisé dans Neuraltalk2 qui ajoute des légendes aux images) -
nico-opendata
Nous fournissons des données telles que des commentaires sur des images fixes souriantes et des vidéos pour les chercheurs. -
DATA GO JP
Un site de catalogue de données ouvertes publié par le gouvernement japonais. Ici recueille également les données publiées par chaque gouvernement local. -
Data.gov
Site original du catalogue américain des données ouvertes -
ShapeNet
Jeu de données de modèle 3D. Il existe différents types de modèles, du mobilier aux avions. -
DCASE
Les données d'apprentissage et d'évaluation sont ouvertes au public pour des tâches de classification des sons naturels (sons de parc, sons de bureau, etc.).
En outre, diverses données sont introduites dans Dataset du site d'information Deeplearning. Le système d'images est bien résumé dans Resource --List of Interesting Very Large Datasets of Images.
Les systèmes de langage naturel utilisent souvent le grattage, mais gardez à l'esprit les problèmes éthiques (Précautions de raclage Web. c5e827e1827e7cb29011)).
Entraine toi
Cette fois, j'utiliserai pylearn2 qui est un des principaux. Pour Windows, comme d'habitude, l'installation est une porte de l'enfer, donc veuillez vous référer à ici (j'ai pensé un instant que je ne pourrais pas sortir de cet enfer cette fois).
Maintenant que pylearn2 est prêt, déplaçons le tutoriel sans cupidité.
Dans Quick-start se trouve un modèle appelé grbm_smd, qui est une machine Boltzmann restreinte qui constitue le Deep Learning. Cela correspond à Machine).
- «grbm» signifie «RBM avec unités gaussiennes». Dans RBM, la valeur qu'un nœud peut généralement prendre est une valeur binaire de 0 ou 1, mais ce n'est pas expressif, il s'agit donc d'un modèle étendu à une fonction linéaire (unité gaussienne) avec une variance indépendante. Voir ici pour plus d'informations (A Practical Guide to Training Restricted Boltzmann Machines section 13.2). Ce document fournit également un bon résumé des autres techniques de travail avec la GAR.
- «smd» signifie «correspondance de score de débruitage», qui est une méthode de données d'entrée manquantes intentionnellement (ajout de bruit) et d'utilisation de la façon dont elles ont été restaurées comme un index (= fonction objectif) du modèle. (Auto-encodeur de débruitage). En incorporant ces couches de rôles dans l'apprentissage en profondeur, vous pouvez améliorer votre réactivité, par exemple, lorsque les caractères manuscrits sont pâles au milieu.
Voici un diagramme du modèle réel. Dans pylearn2, le modèle normal est défini dans un fichier au format YAML (dans ce tutoriel, cifar_grbm_smd.yaml cifar_grbm_smd.yaml)), veuillez également y jeter un œil.

Essayons-le réellement. La procédure est écrite en README, vous pouvez donc la retracer.
- Télécharger les données CIFAR-10
Définissez la variable d'environnement
PYLEARN2_DATA_PATHqui représente le répertoire qui stocke les données utilisées par pylearn2 à l'avance, puis à partir du shell Git.pylearn2/scripts/datasets/download_cifar10.sh
Éxécuter. - Exécutez make_dataset.py
Allez dans le dossier
pylearn2 / scripts / tutorials / grbm_smdet exécutez le script de création de données (n'oubliez pas d'activer l'environnement virtuel).python make_dataset.py - Exécutez train.py
Maintenant que les données sont prêtes, nous allons commencer à apprendre (en fait, nous mettons pylearn2 / scripts dans le chemin, mais c'est gênant, donc nous l'exécutons avec un chemin relatif).
../../train.py cifar_grbm_smd.yaml - Confirmation du résultat de l'exécution
Maintenant que vous avez un modèle entraîné, jetons un coup d'œil à son contenu. matplotlib est utilisé, mais cela ne fonctionnait que si je l'ai installé avec conda (comme l'affichage de l'interface graphique Tcl / Tck et autour de PIL).
../../show_weights.py cifar_grbm_smd.pkl

C'est un mystère ce que cela devrait être, mais au moins cela reflète la taille du poids, et étant donné que les défauts sont saisis au hasard, les couleurs et l'obscurité affichées sont difficiles à restaurer / Indique qu'il s'agit d'un lieu? (Parce que les pondérations ne devraient pas être nécessaires s'il n'est pas nécessaire de les compléter). De plus, vous pouvez facilement vérifier la situation où le taux d'erreur diminue en raison de l'apprentissage avec la commande suivante (spécifiezb, L, Mcomme cible du tracé).../../plot_monitor.py cifar_grbm_smd.pkl

C'est tout pour Quick Start. Il comprenait un contenu difficile, mais je pense qu'au moins le concept du modèle et de l'environnement d'exécution ont été obtenus à ce stade. L'apprentissage profond est littéralement un monde profond, mais j'espère que cet article vous aidera à le comprendre.
Matériel de référence
Deep learning Hello Autoencoder 2012-12-12 Yurufuwa Restricted Boltzmann Machine Lp pooling Neural Net Counterattack Deep Learning Technology Now Mise en œuvre Deep Learning Traitement des chats et des images, partie 3 - Identifier les races de chats grâce au Deep Learning Convolutional Neural Network Convolution Neural Network for speech recognition Building High-level Features Using Large Scale Unsupervised Learning
Recommended Posts