Faites de l'art ASCII avec l'apprentissage en profondeur
Ravi de vous rencontrer. L'activité principale s'appelle Oscii Art, un artisan d'art ASCII (AA) (pas l'activité principale). En regardant le match entre AlphaGo et Lee Sedol, je me suis dit: "** Je veux aussi vaincre l'artisan de Dieu AA avec un apprentissage en profondeur! **", donc j'installerai python et écrirai les résultats d'un an seulement.
Le code est ici. https://github.com/OsciiArt/DeepAA
Quel est l'art ASCII traité ici?
Qu'est-ce que AA utilise ici?
C'est ... ↓
 Pas comme ça ... ↓
Pas comme ça ... ↓
 Pas comme ça ... ↓
Pas comme ça ... ↓
 C'est un peu différent, comme ça …… ↓
C'est un peu différent, comme ça …… ↓
 Mais bien sûr, c'est comme ça. ↓
Mais bien sûr, c'est comme ça. ↓

Ici, nous allons traiter un type d'AA appelé "** Trace AA **" qui reproduit un dessin au trait en créant des caractères. Voir la section "Polices proportionnelles" de la page "Ascii Art" sur wikipedia pour plus d'informations.
[wikipedia: polices ASCII Art-Proportional](https://ja.wikipedia.org/wiki/%E3%82%A2%E3%82%B9%E3%82%AD%E3%83%BC%E3%82% A2% E3% 83% BC% E3% 83% 88 # .E3.83.97.E3.83.AD.E3.83.9D.E3.83.BC.E3.82.B7.E3.83.A7.E3. 83.8A.E3.83.AB.E3.83.95.E3.82.A9.E3.83.B3.E3.83.88.E3.81.AE.E3.82.82.E3.81.AE)
Les conditions telles que les polices sont des spécifications de 2 canaux,
--MS P Gothique --Taille 16 pixels --2 pixels entre les lignes
Est largement adopté.
Bon ou mauvais de l'art ASCII
Il y a beaucoup de malentendus, mais comme prémisse, AA est essentiellement ** manuscrit **. (Un exemple de malentendu: Yahoo Chiebukuro: je vois l'art AA ASCII dans 2 canaux, comment puis-je le faire?)
Il existe des logiciels qui créent automatiquement AA, mais la situation actuelle est qu'il est loin de l'écriture humaine. Une chose à garder à l'esprit pour décider si AA est bon ou mauvais est la ** taille **. Si vous le rendez infiniment grand, un caractère peut représenter un pixel et l'image originale peut être complètement reproduite (même avec un logiciel). Au lieu de cela, AA qui exprime plus de lignes avec un caractère et garde la petite taille est un bon AA.
En d'autres termes, le bien ou le mal des AA
** Reproductibilité de l'image originale ÷ Taille **
Peut être défini comme.
Données d'entraînement
L'apprentissage en profondeur nécessite un grand nombre d'images originales et de paires AA. Cependant, AA n'est fondamentalement pas annoncé comme une paire avec l'image originale. Par conséquent, la collecte de données est difficile. De plus, AA déforme souvent les lignes de l'image originale de manière significative, et même si une paire est obtenue, on s'attend à ce que l'apprentissage soit difficile. Par conséquent, cette fois, nous avons généré ce qui semble être l'image originale d'AA et l'avons utilisée comme données d'entraînement. L'approche dans ce domaine était basée sur la recherche de Simocera Edgar et al. (Dessin au trait automatique d'un croquis approximatif). ..
procédure
- Image AA.
 2. Ceci est loin du dessin au trait réel, utilisez donc le service Web Dessin au trait automatique d'un croquis approximatif de Simocera Edgar et al. Faites-le ressembler à un dessin au trait.
2. Ceci est loin du dessin au trait réel, utilisez donc le service Web Dessin au trait automatique d'un croquis approximatif de Simocera Edgar et al. Faites-le ressembler à un dessin au trait.
 3. Découpez l'image en 64 x 64 pixels et utilisez les caractères correspondant à la zone centrale 16 x 16 comme étiquette correcte.
3. Découpez l'image en 64 x 64 pixels et utilisez les caractères correspondant à la zone centrale 16 x 16 comme étiquette correcte.
 4. Ce processus a été réalisé sur environ 200 AA et utilisé comme données de formation.
4. Ce processus a été réalisé sur environ 200 AA et utilisé comme données de formation.
Apprentissage
Le framework utilisé était Keras (backend: TensorFlow). Pour le réseau, nous avons utilisé un réseau neuronal convolutif standard pour la classification. Le code est indiqué ci-dessous.
def DeepAA(num_label=615, drop_out=0.5, weight_decay=0.001, input_shape = [64, 64]):
"""
Build Deep Neural Network.
:param num_label: int, number of classes, equal to candidates of characters
:param drop_out: float
:param weight_decay: float
:return:
"""
reg = l2(weight_decay)
imageInput = Input(shape=input_shape)
x = Reshape([input_shape[0], input_shape[1], 1])(imageInput)
x = GaussianNoise(0.1)(x)
x = Convolution2D(16, 3, 3, border_mode='same', W_regularizer=reg, b_regularizer=reg, init=normal)(x)
x = BatchNormalization(axis=-3)(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2), border_mode='same')(x)
x = Dropout(drop_out)(x)
x = Convolution2D(32, 3, 3, border_mode='same', W_regularizer=reg, b_regularizer=reg, init=normal)(x)
x = BatchNormalization(axis=-3)(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2), border_mode='same')(x)
x = Dropout(drop_out)(x)
x = Convolution2D(64, 3, 3, border_mode='same', W_regularizer=reg, b_regularizer=reg, init=normal)(x)
x = BatchNormalization(axis=-3)(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2), border_mode='same')(x)
x = Dropout(drop_out)(x)
x = Convolution2D(128, 3, 3, border_mode='same', W_regularizer=reg, b_regularizer=reg, init=normal)(x)
x = BatchNormalization(axis=-3)(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2), border_mode='same')(x)
x = Flatten()(x)
x = Dropout(drop_out)(x)
y = Dense(num_label, activation='softmax')(x)
model = Model(input=imageInput, output=y)
return model
Conditions d'apprentissage
--Nombre de données: 484654
- Taille du lot: 128 --Nombre d'apprentissage: 20000 lots --Fonction de perte: entropie croisée --Fonction d'optimisation: Adam
Avec les paramètres ci-dessus, je me suis entraîné sur une machine sans GPU pendant environ 2 jours.
résultat
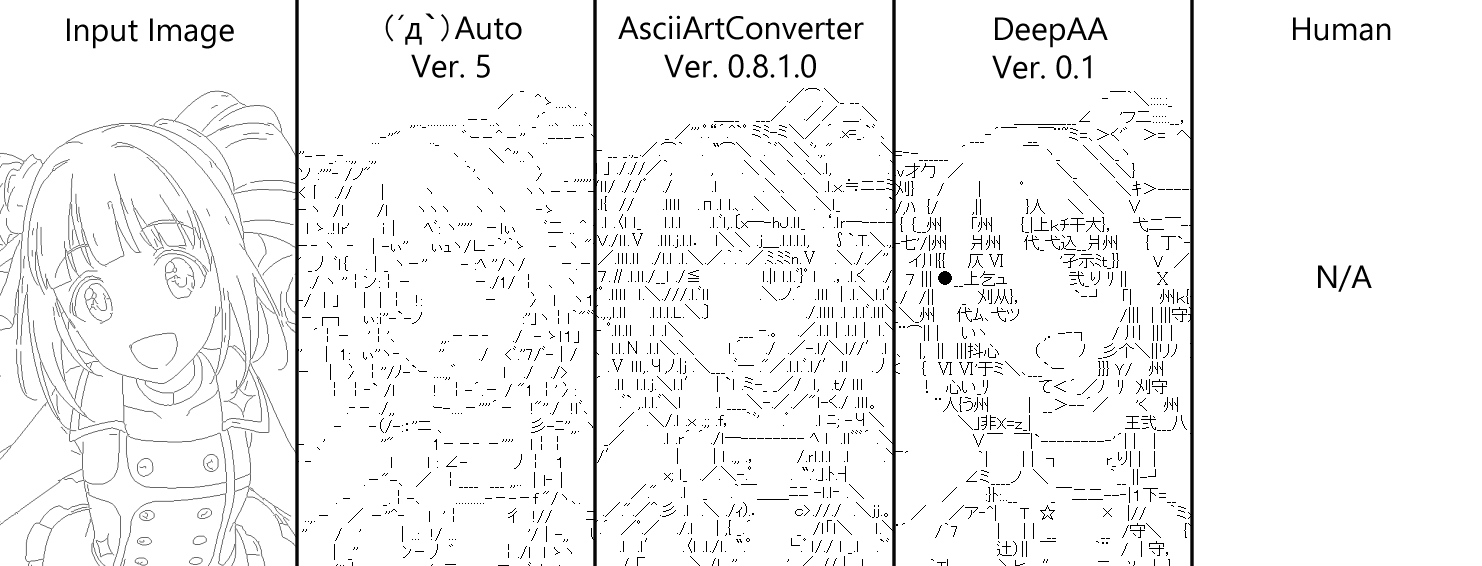
Voici une comparaison avec d'autres logiciels de création automatique AA ↓

- Image d'entrée: Image d'origine
- (´д `) Auto: Creator --kuronowish, où l'obtenir - (´д `) Edit Saitama Sales Office Evacuation Center --AsciiArtConverter: Creator --M. Uryu P, Où l'obtenir-- test --DeepAA: méthode proposée de cet article (ci-après dénommée DeepAA) --Humain: AA manuscrit
Le réglage de la taille est unifié avec celui sélectionné au moment de l'écriture manuscrite. La conversion est le paramètre par défaut pour tous les logiciels. Tous les logiciels sont un peu côte à côte par défaut car c'est une question d'essais et d'erreurs pour améliorer les paramètres. Je pense que la méthode proposée est un peu supérieure dans la possibilité de sélectionner des caractères qui s'intègrent parfaitement dans la partie où la ligne est compliquée.
Un autre point de comparaison ↓
 Ceci est unifié avec la taille qui a été bien sortie par la méthode proposée. C'est donc une comparaison du favoritisme.
Cependant, DeepAA est particulièrement doué pour faire des yeux, et je pense qu'il est possible de sélectionner des personnages aussi bons que les humains.
Ceci est unifié avec la taille qui a été bien sortie par la méthode proposée. C'est donc une comparaison du favoritisme.
Cependant, DeepAA est particulièrement doué pour faire des yeux, et je pense qu'il est possible de sélectionner des personnages aussi bons que les humains.
Je posterai quelques exemples ci-dessous.
 En règle générale, il est plus facile d'obtenir de meilleurs résultats si le dessin au trait est plus fin.
En règle générale, il est plus facile d'obtenir de meilleurs résultats si le dessin au trait est plus fin.
 Même si vous osez sortir le solide tel quel sans le diluer, vous obtiendrez des résultats intéressants.
Même si vous osez sortir le solide tel quel sans le diluer, vous obtiendrez des résultats intéressants.
 Qu'est-ce que tu penses.
Qu'est-ce que tu penses.
Tâche
Je pense que la précision était plus élevée que celle du logiciel de création automatique d'AA existant, mais le résultat était encore loin de l'exactitude des AA manuscrits. Les problèmes d'amélioration sont décrits ci-dessous.
Désalignement
À l'heure actuelle, je pense que la plus grande faiblesse de DeepAA par rapport à l'écriture manuscrite est l'écart. Contrairement aux polices iso-largeurs, qui ont une largeur de caractère constante, nous avons affaire à des polices proportionnelles dans lesquelles la largeur de caractère est différente pour chaque caractère. Pour les polices de même largeur, où les caractères s'inscrivent dans l'image est déterminé de manière unique, mais pour les polices proportionnelles, la position peut être ajustée en combinant les caractères.
Par exemple, dans l'exemple de ↓, la ligne DeepAA vibre dans la partie entourée de bleu, mais si une personne la modifie, elle peut être alignée comme indiqué à droite. (Ajuster par une combinaison d'espace pleine largeur (largeur 11 pixels), espace demi-largeur (largeur 5 pixels), période (largeur 3 pixels).)
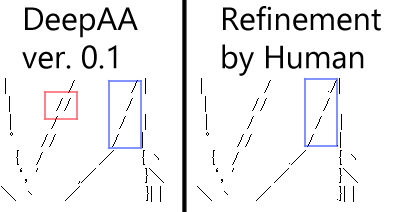 De plus, dans la zone entourée de rouge, le "/" est appliqué deux fois, mais la bonne réponse est clairement d'appliquer un "/" dans la position entre les deux "/".
Le problème est qu'au stade des données d'apprentissage, il est décidé où appliquer les caractères à "** où ", puis seuls les caractères à appliquer à " quoi **" sont entraînés. Cependant, honnêtement, je ne peux pas penser à comment apprendre «où».
De plus, dans la zone entourée de rouge, le "/" est appliqué deux fois, mais la bonne réponse est clairement d'appliquer un "/" dans la position entre les deux "/".
Le problème est qu'au stade des données d'apprentissage, il est décidé où appliquer les caractères à "** où ", puis seuls les caractères à appliquer à " quoi **" sont entraînés. Cependant, honnêtement, je ne peux pas penser à comment apprendre «où».
Dessin au trait
Puisque j'utilise un service Web pour créer des dessins au trait d'images AA, c'est un goulot d'étranglement lorsque je gagne beaucoup de données, alors j'aimerais envisager une alternative.
Nombre d'apprentissage
Jusqu'à présent, je m'entraînais uniquement avec le CPU, mais depuis que j'ai récemment préparé un environnement GPU, j'aimerais essayer de m'entraîner plus de fois avec un modèle plus compliqué.
Recommended Posts