Configurons un modèle de prédiction de survie pour les passagers du Titanic
introduction
Cet article est un article sur le ** 24e jour ** du Calendrier de l'Avent Gizumo Engineer 2015.
Je suis @suzumi, ingénieur en application Web chez Gizumo Co., Ltd., une jeune entreprise qui existe depuis six mois. Ceci est le deuxième article sur le calendrier de l'Avent. Le premier article est "IoT-I a essayé de contrôler à distance le climatiseur à partir du Web en utilisant node.js". Veuillez voir ensemble si vous le souhaitez.
thème
Tout d'abord, faisons la connaissance de Kaggle.
Qu'est-ce que Kaggle?
Kaggle est une plateforme de modélisation prédictive et de méthodes analytiques et sa société d'exploitation où les entreprises et les chercheurs publient des données et les statisticiens et les analystes de données du monde entier se disputent le modèle optimal. --De WikiPedia
Comme vous pouvez le voir dans le devis, c'est un site où les entreprises et autres publient des données, les analysent et les modélisent, et se disputent une modélisation optimale. Pour les entreprises qui publient des données et organisent des concours, il peut être utilisé pour recruter d'excellents data scientists. Les personnes qui participent au concours sont devenues une plateforme qui a des mérites des deux côtés, comme essayer d'améliorer leurs capacités et étudier. De plus, certains concours ont des prix et certains concours ont un prix de 3 millions de dollars (350 millions de yens). Le Classement des utilisateurs est également ouvert au public, et s'il est répertorié ici, il attirera l'attention du monde entier en tant qu'excellent data scientist. Tout comme le nombre d'étoiles sur GitHub est le statut, je pense que les classements sont le statut des data scientists.
Recruit décide d'organiser le "RECRUIT Challenge --Coupon Purchase Prediction", le premier concours de prédiction de données coparrainé par "Kaggle" et une société japonaise C'est devenu un sujet brûlant dans l'actualité cet été, et je pense que la popularité de Kaggle a également augmenté de façon spectaculaire au Japon. J'ai aussi appris Kaggle à partir de cette nouvelle (Tehe)
Récemment, j'ai entendu des mots tels que «science des données», «apprentissage automatique» et «intelligence artificielle» partout où je marche. Bien sûr, je ne peux pas me taire parce que j'aime les choses à la mode.
Donc, cette fois, je voudrais défier l'une des compétitions de type tutoriel dans Kaggle, "Prédiction de survie du Titanic".
À propos, l'environnement d'exécution est le suivant. Il était difficile de mettre dans diverses bibliothèques de calcul numérique, donc j'ai mis Anaconda.
- Python3.5
- iPython notebook
Préparation des données
Tout d'abord, préparons les données. Tout d'abord, accédez à la Page du concours. Téléchargez les données depuis "data" sur le tableau de bord à gauche. Je ne suis pas sûr pour le moment, je vais donc télécharger le csv suivant qui lui ressemble.
- train.csv (59.76 kb)
- test.csv (27.96 kb)
En regardant le contenu, train.csv a une liste de passagers pour environ 900 personnes (avec des résultats de survie), et test.csv a une liste de passagers pour environ 400 personnes (résultats de survie inconnus).
Comme vous pouvez le deviner d'après son nom, il s'agit d'un flux pour créer un modèle de prédiction à partir de train.csv et tester réellement la liste des passagers de test.csv et faire une prédiction. .. Je me souviens avoir entendu quelque part qu'un modèle de prédiction a été créé à partir d'environ 70% des données et testé avec les 30% restants des données, c'est donc exactement ce que c'est. Je suis reconnaissant que les données soient séparées depuis le début.
Forêt aléatoire
Puisque le titre du concours dit de prédire en utilisant une forêt aléatoire, dois-je utiliser une forêt aléatoire? Qu'est-ce qu'une forêt aléatoire en premier lieu? Alors je l'ai recherché sur le Wiki.
Proposé par Leo Breiman en 2001 [1] Un algorithme d'apprentissage automatique utilisé pour la classification, la régression et le clustering. Il s'agit d'un algorithme d'apprentissage de groupe qui utilise un arbre de décision comme un apprenant faible, et son nom est basé sur l'utilisation d'un grand nombre d'arbres de décision appris à partir de données de formation échantillonnées au hasard. Selon le sujet, il est également plus efficace que la stimulation par l'apprentissage en groupe.
- [WikiPedia](https://ja.wikipedia.org/wiki/%E3%83%A9%E3%83%B3%E3%83%80%E3%83%A0%E3%83%95%E3 À partir de% 82% A9% E3% 83% AC% E3% 82% B9% E3% 83% 88)
Qu'est-ce qu'un arbre de décision en premier lieu?
L'arbre de décision est l'un des algorithmes d'apprentissage, et il est complété par la pose d'une question, le branchement avec Oui et Non et la création d'une structure arborescente. L'algorithme dit: «Branchez jusqu'à ce que vous obteniez une réponse complète, et si vous ne pouvez plus créer de branche, arrêtez-vous là.

En d'autres termes, il semble s'agir d'un modèle d'apprentissage de groupe qui améliore la précision en effectuant un apprentissage de groupe (apprentissage d'ensemble) avec un grand nombre d'arbres de décision. Et comment créer un arbre de décision semble être au cœur du modèle d'apprentissage.
Jetez un œil aux données
Ouvrez train.csv et jetez un œil.

J'ai d'abord examiné la signification des variables.
--PassengerID: ID du passager --Survivé: résultat de survie (1: survie, 2: mort) --Pclass: la classe de passagers 1 semble être la plus élevée --Nom: nom du passager --Sex: Genre -Age: Âge --SibSp Nombre de frères et de conjoints. --Parque: nombre de parents et d'enfants.
- Numéro de billet.
- Frais d'embarquement.
- Numéro de la cabine --Embarqué Il existe trois types de ports à bord: Cherbourg, Queenstown et Southampton.
Chargons csv pour le moment. Nous utilisons des pandas, ce qui est bon pour le traitement et l'agrégation des données. Le sexe est difficile à gérer en tant qu'homme, femme, donc homme: l'homme est traité comme 0, femme: la femme est traitée comme 1.
import pandas as pd
import matplotlib.pyplot as plt
df= pd.read_csv("train.csv").replace("male",0).replace("female",1)
Traitement des valeurs manquantes
Il y a des enregistrements manquants dans Age. Il semble qu'il soit nécessaire de renseigner une valeur dans la partie manquante, mais si vous la remplissez avec 0 pour le moment, cela affectera le modèle de prédiction plus tard. Dans ce cas, la fourchette n'est pas si large, donc l'âge moyen de tous les passagers est correct, mais dans ce cas, il est prudent d'utiliser la médiane, donc j'appliquerai la médiane là où elle est manquante. ..
df["Age"].fillna(df.Age.median(), inplace=True)
Sortons un histogramme pour chaque classe de pièce.
split_data = []
for survived in [0,1]:
split_data.append(df[df.Survived==survived])
temp = [i["Pclass"].dropna() for i in split_data]
plt.hist(temp, histtype="barstacked", bins=3)
De gauche, dans les salles de 1re, 2e et 3e classe, la personne qui a survécu à la couleur verte et la personne décédée à la couleur bleue. Il semble que plus de la moitié des passagers des chambres de première classe survivent. En revanche, il semble que seulement 1/5 des passagers des chambres d'hôtes de troisième classe aient survécu. Peut-être que les passagers des chambres de première classe ont eu la priorité et sont montés à bord du bateau de sauvetage.

Ensuite, sortons un histogramme pour chaque âge.
temp = [i["Age"].dropna() for i in split_data]
plt.hist(temp, histtype="barstacked", bins=16)
 Seul le centre dépasse. ..
C'est parce que j'ai mis la valeur médiane dans la valeur manquante à la place.
Si vous n'avez pas l'âge, omettez-le et essayez à nouveau de sortir l'histogramme.
Seul le centre dépasse. ..
C'est parce que j'ai mis la valeur médiane dans la valeur manquante à la place.
Si vous n'avez pas l'âge, omettez-le et essayez à nouveau de sortir l'histogramme.
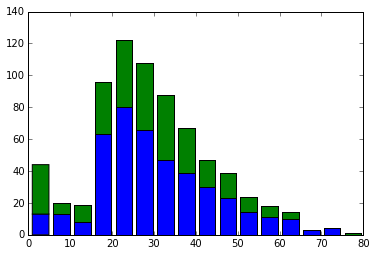
Il a une belle forme. Quand je le regarde, les personnes âgées sont mortes de façon inattendue. Au contraire, les nourrissons ont un taux de survie assez élevé. De là, il semble que les personnes avec des bébés aient eu la priorité pour monter sur le canot de sauvetage.
Mise en forme des données
En regardant les données, je pensais que les familles nombreuses de 5 personnes ou plus avaient un faible taux de survie. En regardant le numéro de billet, il semble que certaines personnes ne sont pas uniques et obtiennent le numéro. Je ne sais pas s'ils étaient dans la même pièce ou s'ils avaient été achetés ensemble, ils auraient le même numéro. Par exemple, est-ce que toutes les personnes avec le numéro de billet «347082» sont des noms de famille? Est le même que "Andersson". En regardant l'âge, cela ressemble à une famille de sept personnes. Puisque la note est de 3, je me demande si c'était une pièce à l'étage inférieur, ils sont tous morts. Ajoutez une variable pour "Nombre de membres de la famille". Supprimez ensuite les variables inutiles.
df["FamilySize"] = df["SibSp"] + df["Parch"] + 1
df2 = df.drop(["Name", "SibSp", "Parch", "Ticket", "Fare", "Cabin", "Embarked"], axis=1)

Il semble que la trame de données des pandas ne puisse pas être passée à scicit-learn car cela est dû à la différence de type, alors vérifions le type.
df2.dtypes
#Résultat de sortie
PassengerId int64
Survived int64
Pclass int64
Sex int64
Age float64
FamilySize int64
dtype: object
Il semble que vous puissiez le passer sans aucun problème.
Apprenons réellement
scikit-learn est une bibliothèque d'apprentissage automatique pour python. Utilisez RandomForestClassifier pour créer et prédire un arbre de décision.
Cependant, comme les variables requises pour les données d'apprentissage sont Pclass et versions ultérieures, elles sont séparées. PassengerId n'est pas nécessaire car il s'agit d'un ID attribué par kaggle. Survived, qui est le résultat de survie, sont les données de réponse correctes.
train_data = df2.values
xs = train_data[:, 2:] #Variables après Pclass
y = train_data[:, 1] #Corriger les données de réponse
Entraînons-nous et créons un modèle de prédiction. Le nombre d'arbres déterminés est défini sur 100 en fonction du Site de référence. Et le contenu de test.csv formate également les données de la même manière que train.csv.
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators = 100)
#Apprentissage
forest = forest.fit(xs, y)
test_df= pd.read_csv("test.csv").replace("male",0).replace("female",1)
#Achèvement de la valeur manquante
test_df["Age"].fillna(df.Age.median(), inplace=True)
test_df["FamilySize"] = test_df["SibSp"] + test_df["Parch"] + 1
test_df2 = test_df.drop(["Name", "SibSp", "Parch", "Ticket", "Fare", "Cabin", "Embarked"], axis=1)
Demandez-leur de faire une prédiction basée sur le modèle de prédiction.
test_data = test_df2.values
xs_test = test_data[:, 1:]
output = forest.predict(xs_test)
print(len(test_data[:,0]), len(output))
zip_data = zip(test_data[:,0].astype(int), output.astype(int))
predict_data = list(zip_data)
Si vous regardez le contenu de predict_data, les résultats prédits sont répertoriés.

Et enfin, écrivons la liste en csv. Vous devriez avoir predict_result_data.csv dans votre répertoire actuel.
import csv
with open("predict_result_data.csv", "w") as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerow(["PassengerId", "Survived"])
for pid, survived in zip(test_data[:,0].astype(int), output.astype(int)):
writer.writerow([pid, survived])
Soumettre à Kaggle
Nous avons créé un csv qui prédit réellement la survie en établissant un modèle de prédiction. Envoyons ça à Kaggle. Allez sur la page du concours Titanic et téléchargez et envoyez à partir de «Mes soumissions» → «Faire une soumission» dans la colonne de gauche. Ensuite, le score sera affiché et vous serez classé.

Le score était de 0,69856. Le score de base est de 0,76555, ce qui n'est pas suffisant. .. Lol
Cette fois, la mission était de mettre en place un modèle de prédiction et de l'envoyer à Kaggle, alors faisons-le. ..
Résumé
Au début, j'ai acheté et lu un livre sur les algorithmes d'apprentissage automatique, mais j'ai pensé qu'il serait préférable de l'essayer en utilisant une bibliothèque. Il existe un joli site appelé Kaggle, donc ce serait peut-être une bonne idée de tester vos compétences ici ou d'étudier en regardant des scripts écrits par d'autres. Pourquoi ne commencez-vous pas votre vie d'apprentissage automatique?
Site de référence
Kaggle 2nd Titanic Survivor Prediction premier défi kaggle: j'ai essayé de prédire le taux de survie avec une forêt aléatoire à partir du profil des passagers du Titanic Prédiction du survivant du Titanic par apprentissage automatique avec Python
Recommended Posts