Guide de l'utilisateur Pandas "fusionner et joindre et concaténer" (document officiel traduction japonaise)
Cet article est une traduction automatique de la documentation officielle de Pandas Guide de l'utilisateur - Fusion, jointure et concaténation. C'est une modification des phrases contre nature du club.
Si vous avez des erreurs de traduction, des traductions alternatives, des questions, etc., veuillez utiliser la section commentaires ou modifier la demande.
fusionner, joindre et concaténer
pandas fournit différents types d'opérations d'ensemble et différentes capacités d'indexation et de capacités algébriques relationnelles dans les opérations de jointure / fusion pour rejoindre facilement des séries ou des DataFrames.
Concaténation d'objets
concat () Fonction (existe dans l'espace de noms principal pandas) Effectue tout le travail fastidieux de l'exécution d'opérations de concaténation le long d'un axe, tout en effectuant des opérations d'ensemble arbitraires (union ou intersection) sur les index d'autres axes (le cas échéant). Notez que nous disons "s'il y en a" car la Série n'a qu'un seul axe de connexion. Avant de plonger dans les détails de Concat et de ce qu'il peut faire, voici un exemple simple.
Avant de plonger dans les détails de concat et de ce qu'il peut faire, voici un exemple simple.
In [1]: df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
...: 'B': ['B0', 'B1', 'B2', 'B3'],
...: 'C': ['C0', 'C1', 'C2', 'C3'],
...: 'D': ['D0', 'D1', 'D2', 'D3']},
...: index=[0, 1, 2, 3])
...:
In [2]: df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
...: 'B': ['B4', 'B5', 'B6', 'B7'],
...: 'C': ['C4', 'C5', 'C6', 'C7'],
...: 'D': ['D4', 'D5', 'D6', 'D7']},
...: index=[4, 5, 6, 7])
...:
In [3]: df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
...: 'B': ['B8', 'B9', 'B10', 'B11'],
...: 'C': ['C8', 'C9', 'C10', 'C11'],
...: 'D': ['D8', 'D9', 'D10', 'D11']},
...: index=[8, 9, 10, 11])
...:
In [4]: frames = [df1, df2, df3]
In [5]: result = pd.concat(frames)
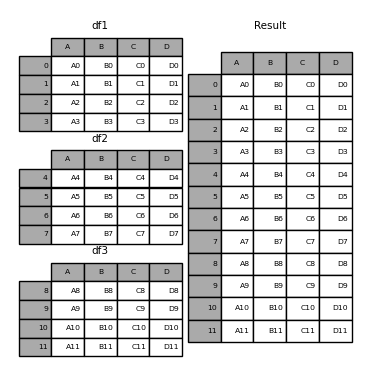
Semblable à la fonction sœur de ndarrays numpy.concatenate, pandas.concat prend une liste ou un dictionnaire d'objets similaires, ainsi qu'un traitement configurable "quoi faire avec d'autres axes". Pour concaténer.
pd.concat(objs, axis=0, join='outer', ignore_index=False, keys=None,
levels=None, names=None, verify_integrity=False, copy=True)
--ʻObjs: Séquence ou mappage d'objets "Series" ou "DataFrame". Si un dictionnaire est passé, les clés triées seront utilisées comme arguments * clés *. Sinon, la valeur est sélectionnée (voir ci-dessous). Aucun Les objets sont implicitement exclus. Si tous sont Aucun, une erreur de valeur se produira. --ʻAxis: {0, 1,…}, la valeur par défaut est 0. Spécifiez les axes à connecter.
--join: {"intérieur", "extérieur"}, la valeur par défaut est "extérieur". Comment gérer les index sur d'autres axes. L'extérieur est la somme (union) et l'intérieur est la partie commune (intersection).
--ʻIgnore_index: valeur booléenne, la valeur par défaut est False. Si True, la valeur d'index sur l'axe concaténé n'est pas utilisée. Les axes résultants sont étiquetés 0,…, n -1. Ceci est utile lors de la concaténation d'objets qui n'ont pas d'informations d'index significatives sur l'axe de concaténation. Notez que les valeurs d'index sur les autres axes continueront d'être prises en compte dans la jointure. --keys: Séquence, la valeur par défaut est Aucune. Construit un index hiérarchique en utilisant la clé transmise comme niveau le plus externe. Si plusieurs niveaux sont passés, le tapple doit être inclus. --levels: Liste des séquences, la valeur par défaut est Aucune. Le niveau spécifique (valeur unique) utilisé pour créer le MultiIndex. Si aucun, il est déduit des clés. --names: Liste, la valeur par défaut est Aucun. Le nom du niveau de l'index hiérarchique résultant. -- verify_integrity: valeur booléenne, la valeur par défaut est False. Vérifiez si le nouvel axe de connexion contient des doublons. Cela peut être très coûteux par rapport à la concaténation réelle des données. --copy`: valeur booléenne, la valeur par défaut est True. Si False, les données ne seront pas copiées inutilement.
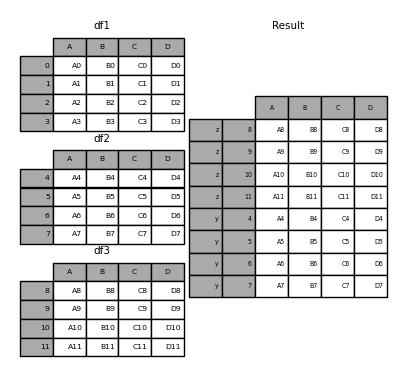
Sans quelques explications, la plupart de ces arguments peuvent ne pas avoir de sens. Regardons à nouveau l'exemple ci-dessus. Supposons que vous souhaitiez associer une clé particulière à chaque partie d'un DataFrame avant de rejoindre. Vous pouvez le faire en utilisant l'argument keys.
In [6]: result = pd.concat(frames, keys=['x', 'y', 'z'])
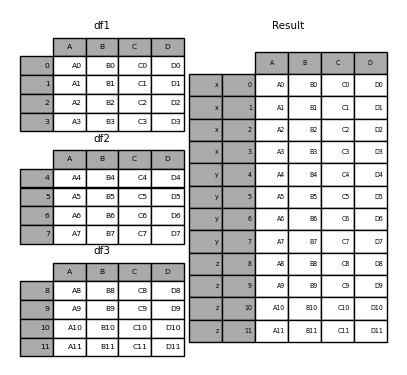
Comme vous pouvez le voir (si vous lisez le reste du document), l'index d'objet résultant a un index hiérarchique (https://qiita.com/nkay/items/63afdd4e96f21efbf62b#hierarchical). Il existe un index multi-index). Cela signifie que vous pouvez sélectionner chaque morceau par clé.
In [7]: result.loc['y']
Out[7]:
A B C D
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
Il n'est pas difficile de voir à quel point cela est utile. Voir ci-dessous pour plus d'informations sur cette fonctionnalité.
: ballot_box_with_check: ** Remarque **
concat ()(d'où ʻappend () `) sont les données Notez que faire une copie complète et réutiliser constamment cette fonction réduira considérablement les performances. Si vous devez utiliser l'opération avec plusieurs ensembles de données, utilisez la notation d'inclusion de liste.
frames = [ process_your_file(f) for f in files ]
result = pd.concat(frames)
Définir les opérations sur d'autres axes
Lorsque vous combinez plusieurs DataFrames, vous pouvez choisir comment gérer d'autres axes (autres que les axes connectés). Ceci peut être fait de deux façons:
--Si vous voulez tout joindre (somme, union), définissez join = 'external'. Il s'agit de l'option par défaut car elle n'entraîne aucune perte d'informations.
--Si vous souhaitez prendre une partie commune (intersection), définissez join = 'inner'.
Voici un exemple de chacune de ces méthodes: Tout d'abord, le comportement lorsque la valeur par défaut join = 'external' est
In [8]: df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],
...: 'D': ['D2', 'D3', 'D6', 'D7'],
...: 'F': ['F2', 'F3', 'F6', 'F7']},
...: index=[2, 3, 6, 7])
...:
In [9]: result = pd.concat([df1, df4], axis=1, sort=False)
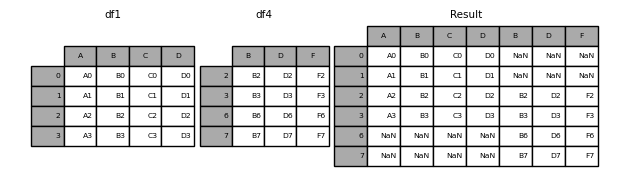
: avertissement: ** Avertissement ** _ Modifié dans la version 0.23.0 _
join = 'external'trie les autres axes (colonnes dans ce cas) par défaut. Les futures versions des pandas ne seront pas triées par défaut. Ici, nous avons spécifiésort = Falseet sélectionné le nouveau comportement.
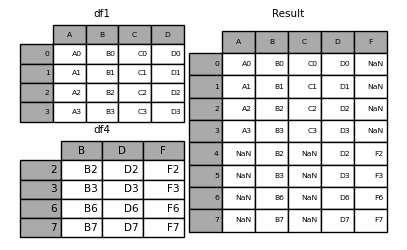
Si vous faites de même avec join = 'inner',
In [10]: result = pd.concat([df1, df4], axis=1, join='inner')

Enfin, supposons que vous souhaitiez réutiliser * l'index exact * du DataFrame d'origine.
In [11]: result = pd.concat([df1, df4], axis=1).reindex(df1.index)
De même, vous pouvez créer un index avant de rejoindre.
In [12]: pd.concat([df1, df4.reindex(df1.index)], axis=1)
Out[12]:
A B C D B D F
0 A0 B0 C0 D0 NaN NaN NaN
1 A1 B1 C1 D1 NaN NaN NaN
2 A2 B2 C2 D2 B2 D2 F2
3 A3 B3 C3 D3 B3 D3 F3

Concaténation avec ʻappend`
ʻAppend () ] de Series et DataFrame (https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.append.html#pandas.DataFrame.append) La méthode d'instance est un raccourci pratique vers [concat ()`. En réalité, ces méthodes ont précédé «concat». Ils se rejoignent sur «axe = 0», c'est-à-dire index.
In [13]: result = df1.append(df2)

Pour DataFrame, les lignes sont toujours séparées (même si elles ont la même valeur), mais les colonnes ne le sont pas.
In [14]: result = df1.append(df4, sort=False)

ʻAppend` peut également recevoir et combiner plusieurs objets.
In [15]: result = df1.append([df2, df3])

: ballot_box_with_check: ** Remarque ** La méthode de type liste ʻappend ()
ajoute un élément à la liste d'origine et renvoie None, mais ce pandas [ʻappend ()](https://pandas.pydata.org/pandas-docs) /stable/reference/api/pandas.DataFrame.append.html#pandas.DataFrame.append) renvoie une copie de «df1» ** inchangé ** et de «df2» concaténée.
Ignorer l'index de l'axe de connexion
Pour les objets DataFrame qui n'ont pas d'index significatifs, vous pouvez ignorer les index en double lorsque vous les joignez. Pour ce faire, utilisez l'argument ʻignore_index`.
In [16]: result = pd.concat([df1, df4], ignore_index=True, sort=False)
Cet argument s'applique également à DataFrame.append () valide.
In [17]: result = df1.append(df4, ignore_index=True, sort=False)

Combinaison de données avec différents nombres de dimensions
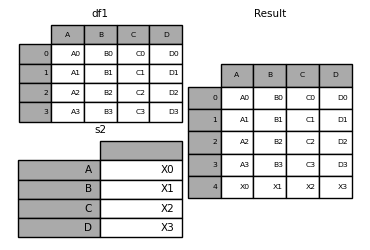
Vous pouvez également combiner un objet «Series» et un objet «DataFrame». «Series» est converti en «DataFrame» avec son nom («name») comme nom de colonne.
In [18]: s1 = pd.Series(['X0', 'X1', 'X2', 'X3'], name='X')
In [19]: result = pd.concat([df1, s1], axis=1)
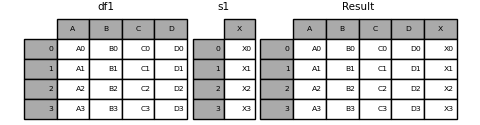
: ballot_box_with_check: ** Remarque ** Depuis que nous avons combiné
SeriesavecDataFrame, [DataFrame.assign ()](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.assign.html J'ai pu obtenir le même résultat que # pandas.DataFrame.assign). Utilisezconcatpour concaténer n'importe quel nombre d'objets pandas (DataFrameouSeries).
Si une «Série» sans nom est transmise, un numéro de série sera ajouté au nom de la colonne.
In [20]: s2 = pd.Series(['_0', '_1', '_2', '_3'])
In [21]: result = pd.concat([df1, s2, s2, s2], axis=1)
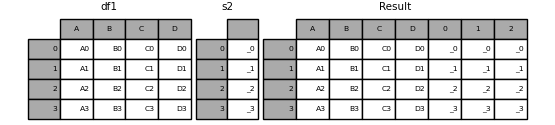
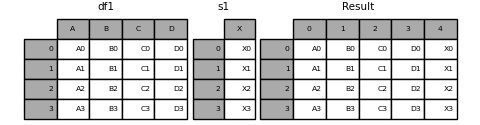
Passer ʻignore_index = True` supprime toutes les références de nom.
In [22]: result = pd.concat([df1, s1], axis=1, ignore_index=True)
Rejoindre plus en utilisant la clé de groupe
L'argument keys est souvent utilisé pour écraser les nouveaux noms de colonne lors de la création d'un nouveau DataFrame à partir d'une Series existante. Le comportement par défaut est que si la "Série" d'origine a un nom, le "DataFrame" résultant en hérite.
In [23]: s3 = pd.Series([0, 1, 2, 3], name='foo')
In [24]: s4 = pd.Series([0, 1, 2, 3])
In [25]: s5 = pd.Series([0, 1, 4, 5])
In [26]: pd.concat([s3, s4, s5], axis=1)
Out[26]:
foo 0 1
0 0 0 0
1 1 1 1
2 2 2 4
3 3 3 5
Vous pouvez remplacer un nom de colonne existant par un nouveau en utilisant l'argument keys.
In [27]: pd.concat([s3, s4, s5], axis=1, keys=['red', 'blue', 'yellow'])
Out[27]:
red blue yellow
0 0 0 0
1 1 1 1
2 2 2 4
3 3 3 5
Prenons une variante du premier exemple donné.
In [28]: result = pd.concat(frames, keys=['x', 'y', 'z'])

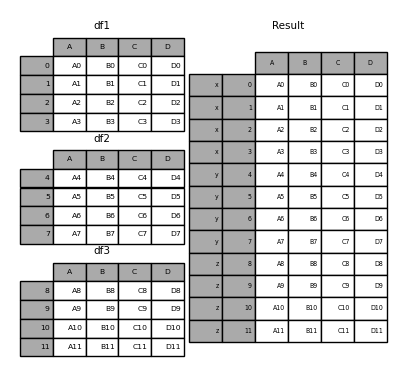
Vous pouvez également passer le dictionnaire à concat. À ce stade, la clé du dictionnaire est utilisée pour l'argument keys (sauf si aucune autre clé n'est spécifiée).
In [29]: pieces = {'x': df1, 'y': df2, 'z': df3}
In [30]: result = pd.concat(pieces)
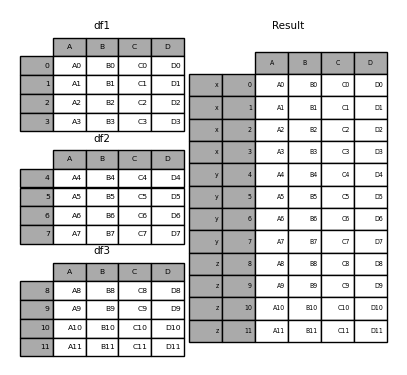
In [31]: result = pd.concat(pieces, keys=['z', 'y'])
Le MultiIndex créé a un niveau composé de la clé passée et de l'index de la pièce DataFrame.
In [32]: result.index.levels
Out[32]: FrozenList([['z', 'y'], [4, 5, 6, 7, 8, 9, 10, 11]])
Si vous souhaitez spécifier d'autres niveaux (et dans certains cas), vous pouvez les spécifier en utilisant l'argument niveaux.
In [33]: result = pd.concat(pieces, keys=['x', 'y', 'z'],
....: levels=[['z', 'y', 'x', 'w']],
....: names=['group_key'])
....:
In [34]: result.index.levels
Out[34]: FrozenList([['z', 'y', 'x', 'w'], [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]])
C'est assez ésotérique, mais c'est en fait nécessaire pour des implémentations telles que GroupBy où l'ordre des variables catégorielles a du sens.
Ajouter une ligne pour DataFrame (ajouter)
Ce n'est pas très efficace (car il crée toujours un nouvel objet), mais vous pouvez ajouter une ligne au DataFrame en passant la Series ou le dictionnaire à ʻappend. Comme mentionné au début, cela renvoie un nouveau DataFrame`.
In [35]: s2 = pd.Series(['X0', 'X1', 'X2', 'X3'], index=['A', 'B', 'C', 'D'])
In [36]: result = df1.append(s2, ignore_index=True)
Si vous voulez que cette méthode supprime l'index d'origine de DataFrame, utilisez ʻignore_index. Si vous souhaitez conserver les index, vous devez créer un DataFrame` correctement indexé et ajouter ou concaténer ces objets.
Vous pouvez également passer un dictionnaire ou une liste de séries.
In [37]: dicts = [{'A': 1, 'B': 2, 'C': 3, 'X': 4},
....: {'A': 5, 'B': 6, 'C': 7, 'Y': 8}]
....:
In [38]: result = df1.append(dicts, ignore_index=True, sort=False)

DataFrame de style de base de données ou jointure / fusion de séries nommées
pandas dispose d'une opération de jointure en mémoire ** hautes performances ** complète qui est très similaire aux bases de données relationnelles telles que SQL. Ces méthodes sont nettement meilleures que d'autres implémentations open source (telles que base :: merge.data.frame de R) (et dans certains cas même d'un ordre de grandeur mieux). La raison en est la conception minutieuse de l'algorithme et la disposition interne des données DataFrame.
Voir aussi livre de recettes pour des opérations plus avancées.
Pour les utilisateurs qui connaissent SQL mais qui ne connaissent pas les pandas, Compare with SQL Peut être utile.
pandas fournit une fonction unique merge () comme point d'entrée pour toutes les opérations de jointure de base de données standard entre les objets DataFrame ou nommés Series.
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
--left: DataFrame ou objet Series nommé.
--right: un autre objet DataFrame ou Series nommé.
--ʻOn: Le nom de la colonne ou du niveau de ligne à joindre. Doit être présent dans les objets DataFrame ou Series gauche et droit. Si vous ne le spécifiez pas et que «left_index» et «right_index» sont «False», on en déduit que la partie commune des colonnes DataFrame ou Series est la clé de jointure. --left_on: colonne DataFrame ou Série de gauche ou niveau de ligne à utiliser comme clé. Vous pouvez recevoir des noms de niveau colonne ou ligne, ou un tableau de longueur égale à la longueur (len) de votre DataFrame ou Series. --right_on: colonne de DataFrame ou de série de gauche ou niveau de ligne à utiliser comme clé. Vous pouvez recevoir des noms de niveau colonne ou ligne, ou un tableau de longueur égale à la longueur (len) de votre DataFrame ou Series. --left_index: Pour True, utilisez l'index de gauche DataFrame ou Series (étiquette de ligne) comme clé de jointure. Pour les DataFrames ou les séries avec MultiIndex (hiérarchie), le nombre de niveaux doit correspondre au nombre de clés de jointure du DataFrame ou de la série sur la droite. --right_index: La même spécification que left_index pour le DataFrame ou la série sur le côté droit. --how: l'un des `` gauche '' ・ `` droite '' ・ `` extérieur '' ・ `` intérieur ''. La valeur par défaut est "intérieure". Des détails sur chaque méthode sont donnés ci-dessous. --sort: trie le DataFrame résultant dans une expression de dictionnaire avec la clé de jointure. La valeur par défaut est «True», et le définir sur «False» améliorera souvent considérablement les performances. --suffixes: Un tuple de préfixes à appliquer aux colonnes en double. La valeur par défaut est ('x', ' y'). --copy: copie toujours les données du DataFrame passé ou de l'objet Series nommé, même si vous n'avez pas besoin de réindexer (si la valeur par défaut est True). La copie ne peut être évitée dans de nombreux cas, mais elle peut améliorer les performances de l'utilisation de la mémoire. La copie peut rarement être évitée, mais cette option est toujours offerte. --ʻIndicator: ajoute une colonne nommée _merge au DataFrame de sortie avec des informations sur la source de chaque ligne. _merge est un type catégorique, left_only si la clé de fusion n'existe que dans le "gauche" DataFrame ou Series, "right_only" s'il n'existe que dans le DataFrame ou la série "droit", s'il existe dans les deux Prend la valeur de «les deux».
--validate: Chaîne de caractères, la valeur par défaut est Aucun. Si spécifié, vérifiez si la fusion est du type spécifié.
- «One_to_one» ou «1: 1»: vérifie si la clé de fusion est unique pour les ensembles de données gauche et droit.
- «One_to_many» ou «1: m»: vérifie si la clé de fusion est unique dans l'ensemble de données de gauche.
- «Many_to_one» ou «m: 1»: vérifiez si la clé de fusion est unique dans le bon jeu de données.
- «Many_to_many» ou «m: m»: reçoit un argument, mais n'est pas confirmé.
_ À partir de la version 0.21.0 _
: ballot_box_with_check: ** Remarque ** La prise en charge de la spécification des niveaux de ligne en utilisant les arguments «on», «left_on» et «right_on» a été ajoutée dans la version 0.23.0. La prise en charge de la fusion des objets nommés «Series» a été ajoutée dans la version 0.24.0.
Le type de retour est le même que «left». Si «left» est un «DataFrame» ou un «Series» nommé et que «right» est une sous-classe de «DataFrame», le type de retour continuera à être «DataFrame».
merge est une fonction dans l'espace de noms pandas, mais vous pouvez également utiliser la méthode d'instanceDataFrame`` merge (). L'appel DataFrame est implicitement considéré comme l'objet à gauche de la jointure.
La méthode associée join () utilise merge en interne pour les jointures index-sur-index (par défaut) et colonne-sur-index. Si vous souhaitez joindre par index uniquement, vous pouvez utiliser DataFrame.join pour simplifier la saisie.
Aperçu de la méthode de fusion (algèbre relationnelle)
Les utilisateurs expérimentés de bases de données relationnelles telles que SQL sont familiers avec la terminologie utilisée pour décrire les opérations de jointure entre deux structures de type table SQL (objets DataFrame). Il y a quelques cas à considérer qui sont très importants à comprendre.
- ** Join one-to-one **: Par exemple, lors de la jonction de deux objets
DataFrameselon un index (incluant une valeur unique). - ** plusieurs-à-un ** Join: par exemple, lors de la jonction d'un index (unique) à une ou plusieurs colonnes de DataFrames différents.
- ** plusieurs à plusieurs ** Joindre: lors de la jonction de colonnes à des colonnes.
Lors de la jonction de colonnes (comme les jointures ** plusieurs à plusieurs **), tous les index de l'objet
DataFrametransmis sont ** ignorés **.
** plusieurs-à-plusieurs ** Cela vaut la peine de comprendre le résultat de la jointure. En SQL et en algèbre relationnelle standard, si une combinaison de touches apparaît plusieurs fois dans les deux tables, la table résultante contiendra un ** produit cartésien ** de données associées. Ce qui suit est un exemple très basique utilisant une combinaison de touches unique.
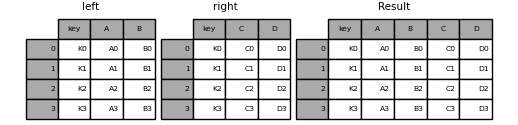
In [39]: left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
....: 'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3']})
....:
In [40]: right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
....: 'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']})
....:
In [41]: result = pd.merge(left, right, on='key')
Voici un exemple plus complexe avec plusieurs clés de jointure. Par défaut, how = 'inner', donc seules les clés communes à gauche et à droite apparaîtront dans le résultat (intersection intersection).
In [42]: left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
....: 'key2': ['K0', 'K1', 'K0', 'K1'],
....: 'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3']})
....:
In [43]: right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
....: 'key2': ['K0', 'K0', 'K0', 'K0'],
....: 'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']})
....:
In [44]: result = pd.merge(left, right, on=['key1', 'key2'])

L'argument how spécifie comment déterminer les clés contenues dans la table résultant de merge. Si la combinaison de touches ** n'existe pas ** dans la table de gauche ou de droite, la valeur de la table jointe sera «NA». Vous trouverez ci-dessous un résumé de l'option how et son nom SQL correspondant.
| méthode de fusion | Nom de SQL JOIN | mouvement |
|---|---|---|
left |
LEFT OUTER JOIN |
Utilisez uniquement la touche gauche |
right |
RIGHT OUTER JOIN |
Utilisez uniquement la bonne clé |
outer |
FULL OUTER JOIN |
Utilisez la somme des deux clés |
inner |
INNER JOIN |
Utilisez la partie commune des deux clés |
In [45]: result = pd.merge(left, right, how='left', on=['key1', 'key2'])
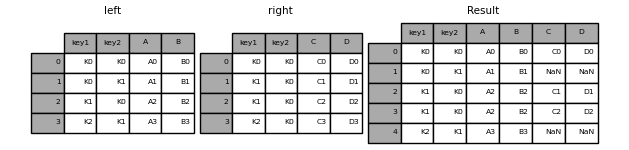
In [46]: result = pd.merge(left, right, how='right', on=['key1', 'key2'])

In [47]: result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
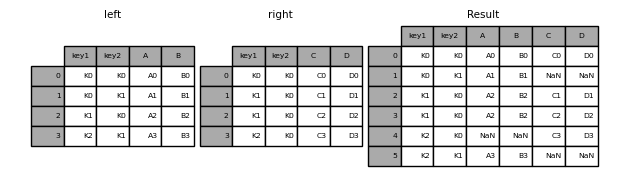
In [48]: result = pd.merge(left, right, how='inner', on=['key1', 'key2'])

L'exemple suivant concerne un DataFrame avec des clés de jointure en double.
In [49]: left = pd.DataFrame({'A': [1, 2], 'B': [2, 2]})
In [50]: right = pd.DataFrame({'A': [4, 5, 6], 'B': [2, 2, 2]})
In [51]: result = pd.merge(left, right, on='B', how='outer')
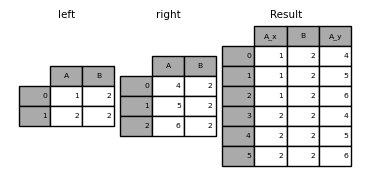
: avertissement: ** Avertissement ** La jointure / fusion avec des clés en double peut renvoyer une trame de multiplication de dimension de ligne, ce qui peut provoquer un débordement de mémoire. Les utilisateurs doivent gérer la duplication des clés avant de rejoindre de grands DataFrames.
Vérifier les clés en double
_ À partir de la version 0.21.0 _
L'utilisateur peut utiliser l'argument validate pour rechercher automatiquement les doublons inattendus dans la clé de fusion. L'unicité de la clé est vérifiée avant l'opération de jointure, ce qui évitera un débordement de mémoire. La vérification de l'unicité de la clé est également un bon moyen de s'assurer que la structure des données utilisateur est comme prévu.
Dans l'exemple suivant, la valeur «B» du «DataFrame» à droite est dupliquée. Ce n'est pas une fusion un à un spécifiée dans l'argument validate, donc une exception est levée.
In [52]: left = pd.DataFrame({'A' : [1,2], 'B' : [1, 2]})
In [53]: right = pd.DataFrame({'A' : [4,5,6], 'B': [2, 2, 2]})
In [53]: result = pd.merge(left, right, on='B', how='outer', validate="one_to_one")
...
MergeError: Merge keys are not unique in right dataset; not a one-to-one merge
Si vous savez déjà que le DataFrame sur la droite a des doublons et que vous voulez vous assurer que le DataFrame sur la gauche n'a pas de doublons, vous pouvez utiliser l'argument` validate = 'one_to_many' à la place. Cela ne soulève pas d'exception.
In [54]: pd.merge(left, right, on='B', how='outer', validate="one_to_many")
Out[54]:
A_x B A_y
0 1 1 NaN
1 2 2 4.0
2 2 2 5.0
3 2 2 6.0
indicateur de fusion
merge () prend l'argument ʻindicator`. Si «True», une colonne catégorielle de type «_merge» avec l'une des valeurs suivantes sera ajoutée à l'objet de sortie:
| Origine de l'observation | _mergeLa valeur du |
|---|---|
La clé de jointure estleftPrésent uniquement dans le cadre |
left_only |
La clé de jointure estrightPrésent uniquement dans le cadre |
right_only |
| La clé de jointure existe dans les deux cadres | both |
In [55]: df1 = pd.DataFrame({'col1': [0, 1], 'col_left': ['a', 'b']})
In [56]: df2 = pd.DataFrame({'col1': [1, 2, 2], 'col_right': [2, 2, 2]})
In [57]: pd.merge(df1, df2, on='col1', how='outer', indicator=True)
Out[57]:
col1 col_left col_right _merge
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
L'argument ʻindicator` peut également accepter une chaîne. Dans ce cas, la fonction d'indicateur utilise la valeur de la chaîne transmise comme nom de la colonne d'indicateur.
In [58]: pd.merge(df1, df2, on='col1', how='outer', indicator='indicator_column')
Out[58]:
col1 col_left col_right indicator_column
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
type de données de fusion
merge contient le type de données de la clé de fusion.
In [59]: left = pd.DataFrame({'key': [1], 'v1': [10]})
In [60]: left
Out[60]:
key v1
0 1 10
In [61]: right = pd.DataFrame({'key': [1, 2], 'v1': [20, 30]})
In [62]: right
Out[62]:
key v1
0 1 20
1 2 30
Vous pouvez maintenir la clé de jointure.
In [63]: pd.merge(left, right, how='outer')
Out[63]:
key v1
0 1 10
1 1 20
2 2 30
In [64]: pd.merge(left, right, how='outer').dtypes
Out[64]:
key int64
v1 int64
dtype: object
Bien sûr, s'il y a des valeurs manquantes, le type de données résultant sera upcast.
In [65]: pd.merge(left, right, how='outer', on='key')
Out[65]:
key v1_x v1_y
0 1 10.0 20
1 2 NaN 30
In [66]: pd.merge(left, right, how='outer', on='key').dtypes
Out[66]:
key int64
v1_x float64
v1_y int64
dtype: object
merge conserve le type de données d'origine category. Voir également la section sur les catégories (https://dev.pandas.io/docs/user_guide/categorical.html#categorical-merge).
Cadre gauche.
In [67]: from pandas.api.types import CategoricalDtype
In [68]: X = pd.Series(np.random.choice(['foo', 'bar'], size=(10,)))
In [69]: X = X.astype(CategoricalDtype(categories=['foo', 'bar']))
In [70]: left = pd.DataFrame({'X': X,
....: 'Y': np.random.choice(['one', 'two', 'three'],
....: size=(10,))})
....:
In [71]: left
Out[71]:
X Y
0 bar one
1 foo one
2 foo three
3 bar three
4 foo one
5 bar one
6 bar three
7 bar three
8 bar three
9 foo three
In [72]: left.dtypes
Out[72]:
X category
Y object
dtype: object
Cadre droit.
In [73]: right = pd.DataFrame({'X': pd.Series(['foo', 'bar'],
....: dtype=CategoricalDtype(['foo', 'bar'])),
....: 'Z': [1, 2]})
....:
In [74]: right
Out[74]:
X Z
0 foo 1
1 bar 2
In [75]: right.dtypes
Out[75]:
X category
Z int64
dtype: object
Le résultat combiné.
In [76]: result = pd.merge(left, right, how='outer')
In [77]: result
Out[77]:
X Y Z
0 bar one 2
1 bar three 2
2 bar one 2
3 bar three 2
4 bar three 2
5 bar three 2
6 foo one 1
7 foo three 1
8 foo one 1
9 foo three 1
In [78]: result.dtypes
Out[78]:
X category
Y object
Z int64
dtype: object
: ballot_box_with_check: ** Remarque ** Les types de catégories doivent avoir les mêmes attributs de catégorie et d'ordre et être * exactement * identiques. Sinon, le résultat sera écrasé par le type de données de l'élément de catégorie.
: ballot_box_with_check: ** Remarque ** Rejoindre les mêmes types de données
categorypeut très bien fonctionner par rapport à la fusion de types de données ʻobject`.
Jointure basée sur un index
DataFrame.join () peut avoir différents index C'est une méthode pratique pour combiner deux colonnes "DataFrame" possibles en un "DataFrame". L'exemple suivant est un exemple très basique.
In [79]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
....: 'B': ['B0', 'B1', 'B2']},
....: index=['K0', 'K1', 'K2'])
....:
In [80]: right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
....: 'D': ['D0', 'D2', 'D3']},
....: index=['K0', 'K2', 'K3'])
....:
In [81]: result = left.join(right)
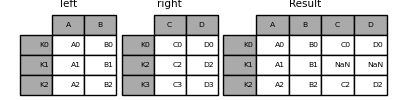
In [82]: result = left.join(right, how='outer')
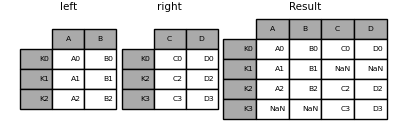
Similaire à ce qui précède, en utilisant how = 'inner',
In [83]: result = left.join(right, how='inner')
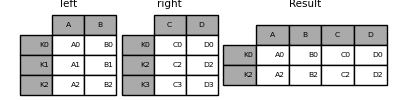
L'alignement des données ici est basé sur l'index (étiquette de ligne). Pour faire de même avec merge, transmettez un argument supplémentaire qui vous indique d'utiliser l'index.
In [84]: result = pd.merge(left, right, left_index=True, right_index=True, how='outer')

In [85]: result = pd.merge(left, right, left_index=True, right_index=True, how='inner')

Joindre la colonne clé à l'index
join () est un argument optionnel ʻon` , Reçoit une colonne ou plusieurs noms de colonnes. Le «DataFrame» passé sera joint le long de cette colonne dans le «DataFrame». Les deux appels de fonction suivants sont exactement équivalents.
left.join(right, on=key_or_keys)
pd.merge(left, right, left_on=key_or_keys, right_index=True,
how='left', sort=False)
De toute évidence, vous pouvez choisir un format plus pratique. Pour les jointures plusieurs-à-un (si l'un des DataFrames est déjà indexé par la clé de jointure), il peut être plus pratique d'utiliser join. Voici un exemple simple.
In [86]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3'],
....: 'key': ['K0', 'K1', 'K0', 'K1']})
....:
In [87]: right = pd.DataFrame({'C': ['C0', 'C1'],
....: 'D': ['D0', 'D1']},
....: index=['K0', 'K1'])
....:
In [88]: result = left.join(right, on='key')
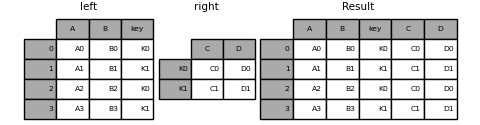
In [89]: result = pd.merge(left, right, left_on='key', right_index=True,
....: how='left', sort=False);
....:
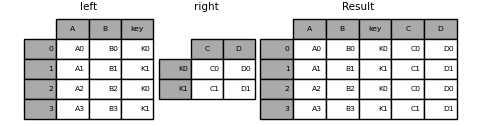
Pour joindre plusieurs clés, le DataFrame passé doit avoir «MultiIndex».
In [90]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3'],
....: 'key1': ['K0', 'K0', 'K1', 'K2'],
....: 'key2': ['K0', 'K1', 'K0', 'K1']})
....:
In [91]: index = pd.MultiIndex.from_tuples([('K0', 'K0'), ('K1', 'K0'),
....: ('K2', 'K0'), ('K2', 'K1')])
....:
In [92]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']},
....: index=index)
....:
Cela peut être combiné en passant deux noms de colonnes clés.
In [93]: result = left.join(right, on=['key1', 'key2'])
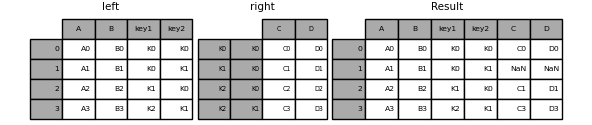
La valeur par défaut pour DataFrame.join est d'effectuer une jointure gauche (essentiellement une opération" RECHERCHEV "pour les utilisateurs d'Excel) qui utilise uniquement les clés trouvées dans le DataFrame appelant. D'autres types de jointure, tels que les jointures internes, sont tout aussi faciles à exécuter.
In [94]: result = left.join(right, on=['key1', 'key2'], how='inner')
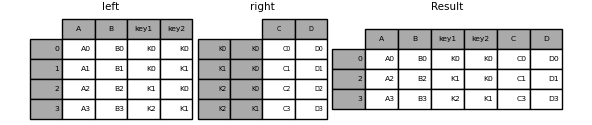
Comme ci-dessus, cela supprimera les lignes sans correspondance.
Joindre un seul index à plusieurs index
Vous pouvez combiner un seul index DataFrame à un niveau de DataFrame avec un MultiIndex. Dans le nom de niveau d'une image avec MultiIndex, le niveau correspond au nom d'index d'une seule image d'index.
In [95]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
....: 'B': ['B0', 'B1', 'B2']},
....: index=pd.Index(['K0', 'K1', 'K2'], name='key'))
....:
In [96]: index = pd.MultiIndex.from_tuples([('K0', 'Y0'), ('K1', 'Y1'),
....: ('K2', 'Y2'), ('K2', 'Y3')],
....: names=['key', 'Y'])
....:
In [97]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']},
....: index=index)
....:
In [98]: result = left.join(right, how='inner')
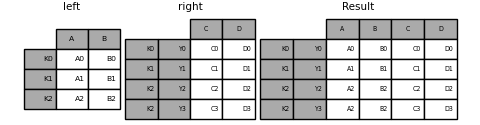
L'exemple suivant est équivalent, mais moins redondant, plus efficace en mémoire et plus rapide.
In [99]: result = pd.merge(left.reset_index(), right.reset_index(),
....: on=['key'], how='inner').set_index(['key','Y'])
....:

Combinez deux multi-index
Cette méthode ne peut être utilisée que si l'index de l'argument de droite est entièrement utilisé dans la jointure et est un sous-ensemble de l'index de l'argument de gauche, comme dans l'exemple suivant.
In [100]: leftindex = pd.MultiIndex.from_product([list('abc'), list('xy'), [1, 2]],
.....: names=['abc', 'xy', 'num'])
.....:
In [101]: left = pd.DataFrame({'v1': range(12)}, index=leftindex)
In [102]: left
Out[102]:
v1
abc xy num
a x 1 0
2 1
y 1 2
2 3
b x 1 4
2 5
y 1 6
2 7
c x 1 8
2 9
y 1 10
2 11
In [103]: rightindex = pd.MultiIndex.from_product([list('abc'), list('xy')],
.....: names=['abc', 'xy'])
.....:
In [104]: right = pd.DataFrame({'v2': [100 * i for i in range(1, 7)]}, index=rightindex)
In [105]: right
Out[105]:
v2
abc xy
a x 100
y 200
b x 300
y 400
c x 500
y 600
In [106]: left.join(right, on=['abc', 'xy'], how='inner')
Out[106]:
v1 v2
abc xy num
a x 1 0 100
2 1 100
y 1 2 200
2 3 200
b x 1 4 300
2 5 300
y 1 6 400
2 7 400
c x 1 8 500
2 9 500
y 1 10 600
2 11 600
Si cette condition n'est pas remplie, vous pouvez utiliser le code suivant pour effectuer une jointure de deux multi-index.
In [107]: leftindex = pd.MultiIndex.from_tuples([('K0', 'X0'), ('K0', 'X1'),
.....: ('K1', 'X2')],
.....: names=['key', 'X'])
.....:
In [108]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
.....: 'B': ['B0', 'B1', 'B2']},
.....: index=leftindex)
.....:
In [109]: rightindex = pd.MultiIndex.from_tuples([('K0', 'Y0'), ('K1', 'Y1'),
.....: ('K2', 'Y2'), ('K2', 'Y3')],
.....: names=['key', 'Y'])
.....:
In [110]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
.....: 'D': ['D0', 'D1', 'D2', 'D3']},
.....: index=rightindex)
.....:
In [111]: result = pd.merge(left.reset_index(), right.reset_index(),
.....: on=['key'], how='inner').set_index(['key', 'X', 'Y'])
.....:
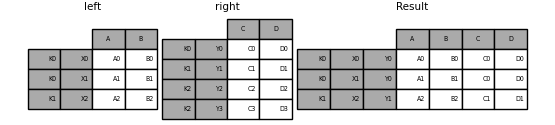
Fusionner avec une combinaison de colonne et de niveau d'index
_ À partir de la version 0.23 _
La chaîne passée en tant que paramètre ʻon·left_on · right_onpeut faire référence à un nom de colonne ou à un nom de niveau d'index. Cela vous permet de fusionner des instancesDataFrame` avec une combinaison de niveaux d'index et de colonnes sans réinitialiser l'index.
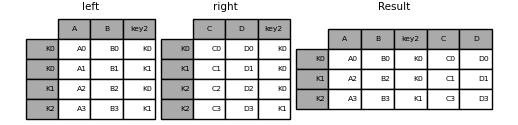
In [112]: left_index = pd.Index(['K0', 'K0', 'K1', 'K2'], name='key1')
In [113]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
.....: 'B': ['B0', 'B1', 'B2', 'B3'],
.....: 'key2': ['K0', 'K1', 'K0', 'K1']},
.....: index=left_index)
.....:
In [114]: right_index = pd.Index(['K0', 'K1', 'K2', 'K2'], name='key1')
In [115]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
.....: 'D': ['D0', 'D1', 'D2', 'D3'],
.....: 'key2': ['K0', 'K0', 'K0', 'K1']},
.....: index=right_index)
.....:
In [116]: result = left.merge(right, on=['key1', 'key2'])
: ballot_box_with_check: ** Remarque ** Si vous fusionnez un DataFrame avec une chaîne qui correspond au niveau d'index des deux cadres, le niveau d'index sera conservé comme niveau d'index du DataFrame résultant.
: ballot_box_with_check: ** Remarque ** Si vous fusionnez un DataFrame en utilisant uniquement certains niveaux de * MultiIndex *, les niveaux supplémentaires seront supprimés des résultats fusionnés. Pour conserver ces niveaux, utilisez
reset_indexdans leur nom de niveau pour les déplacer vers la colonne avant d'effectuer la fusion.
: ballot_box_with_check: ** Remarque ** Si la chaîne correspond à la fois au nom de la colonne et au nom du niveau d'index, un avertissement est déclenché et la colonne est prioritaire. Cela peut provoquer des erreurs ambiguës dans les versions futures.
Colonnes avec des valeurs en double
L'argument «suffixes» de la fusion prend un tuple de chaînes à ajouter au nom de colonne en double dans l'entrée «DataFrame» pour clarifier la colonne résultante.
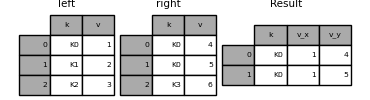
In [117]: left = pd.DataFrame({'k': ['K0', 'K1', 'K2'], 'v': [1, 2, 3]})
In [118]: right = pd.DataFrame({'k': ['K0', 'K0', 'K3'], 'v': [4, 5, 6]})
In [119]: result = pd.merge(left, right, on='k')
In [120]: result = pd.merge(left, right, on='k', suffixes=['_l', '_r'])
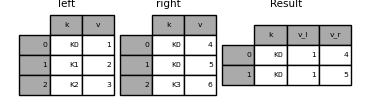
Fonctionne de la même manière pour DataFrame.join () Il y a des arguments lsuffix et rsuffix à faire.
In [121]: left = left.set_index('k')
In [122]: right = right.set_index('k')
In [123]: result = left.join(right, lsuffix='_l', rsuffix='_r')

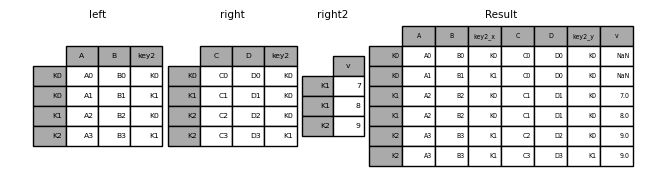
Rejoindre plusieurs DataFrames
Ajoutez une liste ou taple de DataFrame à join () Vous pouvez également les transmettre et les rejoindre par index.
In [124]: right2 = pd.DataFrame({'v': [7, 8, 9]}, index=['K1', 'K1', 'K2'])
In [125]: result = left.join([right, right2])
Combiner des valeurs dans une colonne Series ou DataFrame
Une autre situation assez courante est d'avoir deux objets «Series» ou «DataFrame» indexés de manière similaire (ou indexés de manière similaire) qui correspondent à la valeur d'un objet avec l'index de l'autre. Vous voulez "patcher" à partir de la valeur. Un exemple est présenté ci-dessous.
In [126]: df1 = pd.DataFrame([[np.nan, 3., 5.], [-4.6, np.nan, np.nan],
.....: [np.nan, 7., np.nan]])
.....:
In [127]: df2 = pd.DataFrame([[-42.6, np.nan, -8.2], [-5., 1.6, 4]],
.....: index=[1, 2])
.....:
Pour ce faire, utilisez la méthode combine_first (). Je vais.
In [128]: result = df1.combine_first(df2)
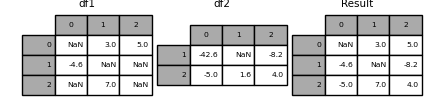
Notez que cette méthode obtient la valeur de la droite DataFrame uniquement si la gauche DataFrame n'a pas de valeur. La méthode associée ʻupdate () ` n'est pas NA. Changez la valeur.
In [129]: df1.update(df2)

Rejoindre pour les données de séries chronologiques
Rejoindre des données commandées
La fonction merge_ordered () permet de classer les séries chronologiques et autres Vous pouvez combiner les données. Il comporte un argument optionnel fill_method pour remplir et interpoler les données manquantes.
In [130]: left = pd.DataFrame({'k': ['K0', 'K1', 'K1', 'K2'],
.....: 'lv': [1, 2, 3, 4],
.....: 's': ['a', 'b', 'c', 'd']})
.....:
In [131]: right = pd.DataFrame({'k': ['K1', 'K2', 'K4'],
.....: 'rv': [1, 2, 3]})
.....:
In [132]: pd.merge_ordered(left, right, fill_method='ffill', left_by='s')
Out[132]:
k lv s rv
0 K0 1.0 a NaN
1 K1 1.0 a 1.0
2 K2 1.0 a 2.0
3 K4 1.0 a 3.0
4 K1 2.0 b 1.0
5 K2 2.0 b 2.0
6 K4 2.0 b 3.0
7 K1 3.0 c 1.0
8 K2 3.0 c 2.0
9 K4 3.0 c 3.0
10 K1 NaN d 1.0
11 K2 4.0 d 2.0
12 K4 4.0 d 3.0
dès la fusion
merge_asof () est similaire à une jointure gauche ordonnée , Correspond à la clé la plus proche au lieu de la clé à nombre égal. Pour chaque ligne de «DataFrame gauche», sélectionnez la dernière ligne de «DataFrame droit» où la touche «on» est inférieure à la touche gauche. Les deux DataFrames doivent être triés par clé.
En option, asof merge peut effectuer des fusions basées sur des groupes. Il s'agit d'une correspondance étroite pour la clé ʻon, plus une correspondance exacte pour la clé by`.
Par exemple, si vous avez des «métiers» et des «quotes», fusionnez-les.
In [133]: trades = pd.DataFrame({
.....: 'time': pd.to_datetime(['20160525 13:30:00.023',
.....: '20160525 13:30:00.038',
.....: '20160525 13:30:00.048',
.....: '20160525 13:30:00.048',
.....: '20160525 13:30:00.048']),
.....: 'ticker': ['MSFT', 'MSFT',
.....: 'GOOG', 'GOOG', 'AAPL'],
.....: 'price': [51.95, 51.95,
.....: 720.77, 720.92, 98.00],
.....: 'quantity': [75, 155,
.....: 100, 100, 100]},
.....: columns=['time', 'ticker', 'price', 'quantity'])
.....:
In [134]: quotes = pd.DataFrame({
.....: 'time': pd.to_datetime(['20160525 13:30:00.023',
.....: '20160525 13:30:00.023',
.....: '20160525 13:30:00.030',
.....: '20160525 13:30:00.041',
.....: '20160525 13:30:00.048',
.....: '20160525 13:30:00.049',
.....: '20160525 13:30:00.072',
.....: '20160525 13:30:00.075']),
.....: 'ticker': ['GOOG', 'MSFT', 'MSFT',
.....: 'MSFT', 'GOOG', 'AAPL', 'GOOG',
.....: 'MSFT'],
.....: 'bid': [720.50, 51.95, 51.97, 51.99,
.....: 720.50, 97.99, 720.50, 52.01],
.....: 'ask': [720.93, 51.96, 51.98, 52.00,
.....: 720.93, 98.01, 720.88, 52.03]},
.....: columns=['time', 'ticker', 'bid', 'ask'])
.....:
In [135]: trades
Out[135]:
time ticker price quantity
0 2016-05-25 13:30:00.023 MSFT 51.95 75
1 2016-05-25 13:30:00.038 MSFT 51.95 155
2 2016-05-25 13:30:00.048 GOOG 720.77 100
3 2016-05-25 13:30:00.048 GOOG 720.92 100
4 2016-05-25 13:30:00.048 AAPL 98.00 100
In [136]: quotes
Out[136]:
time ticker bid ask
0 2016-05-25 13:30:00.023 GOOG 720.50 720.93
1 2016-05-25 13:30:00.023 MSFT 51.95 51.96
2 2016-05-25 13:30:00.030 MSFT 51.97 51.98
3 2016-05-25 13:30:00.041 MSFT 51.99 52.00
4 2016-05-25 13:30:00.048 GOOG 720.50 720.93
5 2016-05-25 13:30:00.049 AAPL 97.99 98.01
6 2016-05-25 13:30:00.072 GOOG 720.50 720.88
7 2016-05-25 13:30:00.075 MSFT 52.01 52.03
Par défaut, appliquez les guillemets dès.
In [137]: pd.merge_asof(trades, quotes,
.....: on='time',
.....: by='ticker')
.....:
Out[137]:
time ticker price quantity bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 51.95 51.96
1 2016-05-25 13:30:00.038 MSFT 51.95 155 51.97 51.98
2 2016-05-25 13:30:00.048 GOOG 720.77 100 720.50 720.93
3 2016-05-25 13:30:00.048 GOOG 720.92 100 720.50 720.93
4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
Gardez le temps entre l'heure de cotation et l'heure de négociation dans un délai de «2 ms».
In [138]: pd.merge_asof(trades, quotes,
.....: on='time',
.....: by='ticker',
.....: tolerance=pd.Timedelta('2ms'))
.....:
Out[138]:
time ticker price quantity bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 51.95 51.96
1 2016-05-25 13:30:00.038 MSFT 51.95 155 NaN NaN
2 2016-05-25 13:30:00.048 GOOG 720.77 100 720.50 720.93
3 2016-05-25 13:30:00.048 GOOG 720.92 100 720.50 720.93
4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
Gardez le temps entre les cours et les échanges dans un délai de «10 ms» et excluez les correspondances exactes à l'heure. Excluez les correspondances exactes (des guillemets), mais notez que les citations précédentes * se propagent * jusqu'à ce point.
In [139]: pd.merge_asof(trades, quotes,
.....: on='time',
.....: by='ticker',
.....: tolerance=pd.Timedelta('10ms'),
.....: allow_exact_matches=False)
.....:
Out[139]:
time ticker price quantity bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 NaN NaN
1 2016-05-25 13:30:00.038 MSFT 51.95 155 51.97 51.98
2 2016-05-25 13:30:00.048 GOOG 720.77 100 NaN NaN
3 2016-05-25 13:30:00.048 GOOG 720.92 100 NaN NaN
4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
Recommended Posts