Qu'est-ce que xg boost (1) (pour les débutants)
En tant que data scientist, j'aimerais revenir en arrière et organiser ce que je suis venu à Gamshala. Je ne traiterai pas des données réelles, mais j'écrirai ce que j'ai appris pour produire une sortie. Tout d'abord, je veux gérer xgboost, mais dès le départ, l'apprentissage d'ensemble. (xgboost est un type d'apprentissage d'ensemble) Xgboost est une méthode polyvalente pour les tâches prédictives.
Qu'est-ce que l'apprentissage d'ensemble?
Lorsque vous souhaitez résoudre un problème de prédiction avec des données, vous pouvez combiner plusieurs appareils d'apprentissage pour améliorer la précision et créer un appareil d'apprentissage.
Plutôt que d'en créer un avec uniquement un appareil d'apprentissage, vous pouvez créer un appareil d'apprentissage en fonction des résultats, ou vous pouvez créer une combinaison de plusieurs appareils d'apprentissage, de sorte que la précision augmentera. L'idée. Il peut être grossièrement classé en trois types. Connaissances de base avant cela.
Biais et variance
Biais: moyenne des valeurs réelles et prévues Variance: degré de dispersion des valeurs prédites
④ est un état avec une bonne précision car il a un biais faible et une faible variance. ③ est un état de variance élevée. Le modèle est susceptible d'être surentraîné. Les prévisions utilisant de nouvelles données ont tendance à être inexactes. ② est un état de biais élevé. Il y a de fortes chances que les données n'aient pas été apprises en premier lieu.
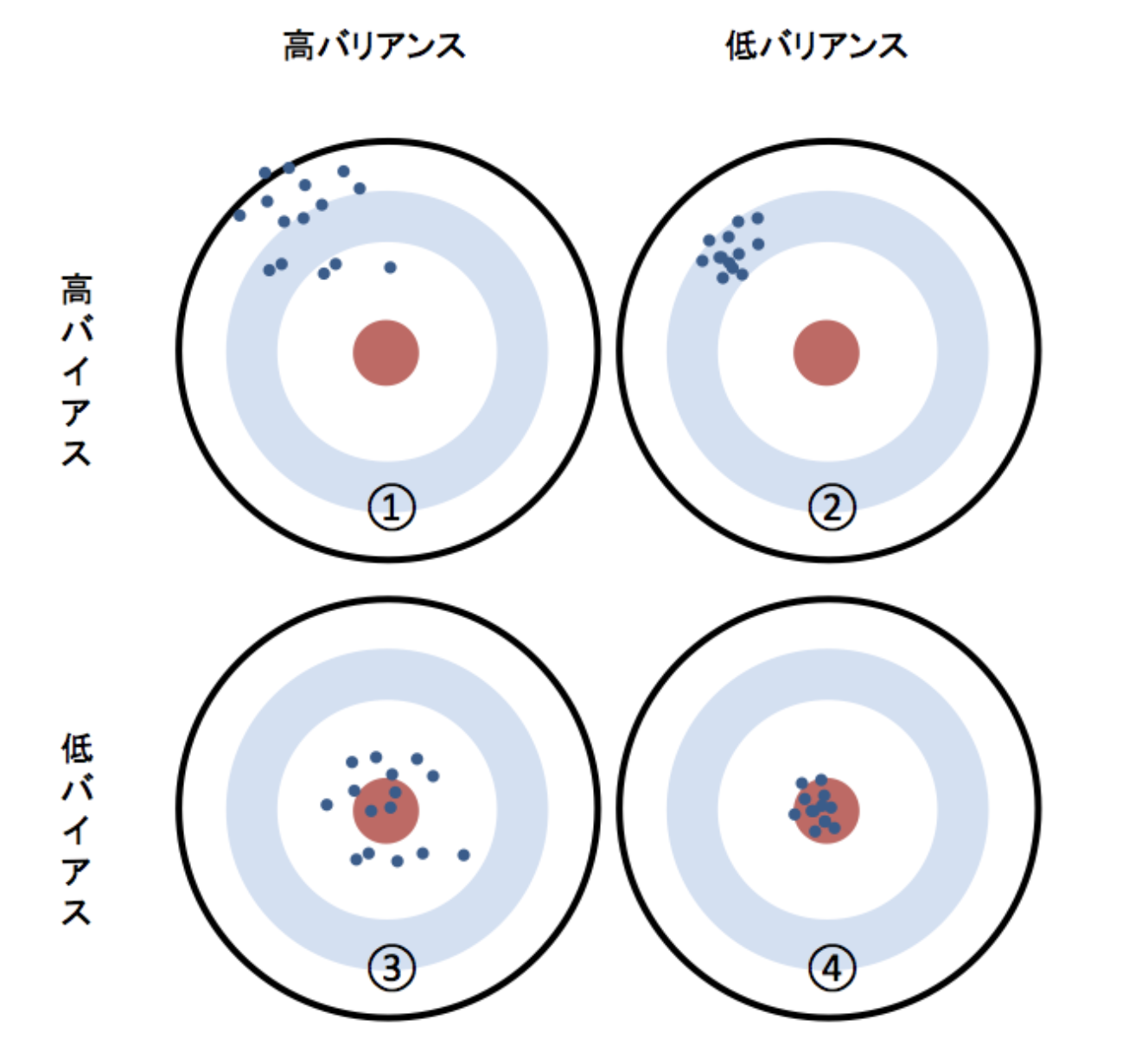 La figure est très facile à comprendre, je vais donc emprunter la figure sur la page de référence.
[Tous les apprenants avancés en machine l'utilisent-ils? !! J'expliquerai le mécanisme de l'apprentissage d'ensemble et les trois types]
(https://www.codexa.net/what-is-ensemble-learning/)
La figure est très facile à comprendre, je vais donc emprunter la figure sur la page de référence.
[Tous les apprenants avancés en machine l'utilisent-ils? !! J'expliquerai le mécanisme de l'apprentissage d'ensemble et les trois types]
(https://www.codexa.net/what-is-ensemble-learning/)
Trois méthodes
Ensachage
Généralement, il a la particularité d'abaisser la variance du résultat de prédiction du modèle. Lors de l'ensachage, les données d'entraînement sont restaurées et extraites à l'aide de la méthode de trappe accélérée pour ajouter de la diversité à l'ensemble de données. L'extraction par restauration est une méthode d'extraction dans laquelle un échantillon une fois extrait est à nouveau soumis à une extraction.
Regroupez chaque résultat pour créer un apprenant. S'il s'agit d'une régression, il est décidé par la valeur moyenne, et s'il s'agit d'un classement, il est décidé par un vote à la majorité.
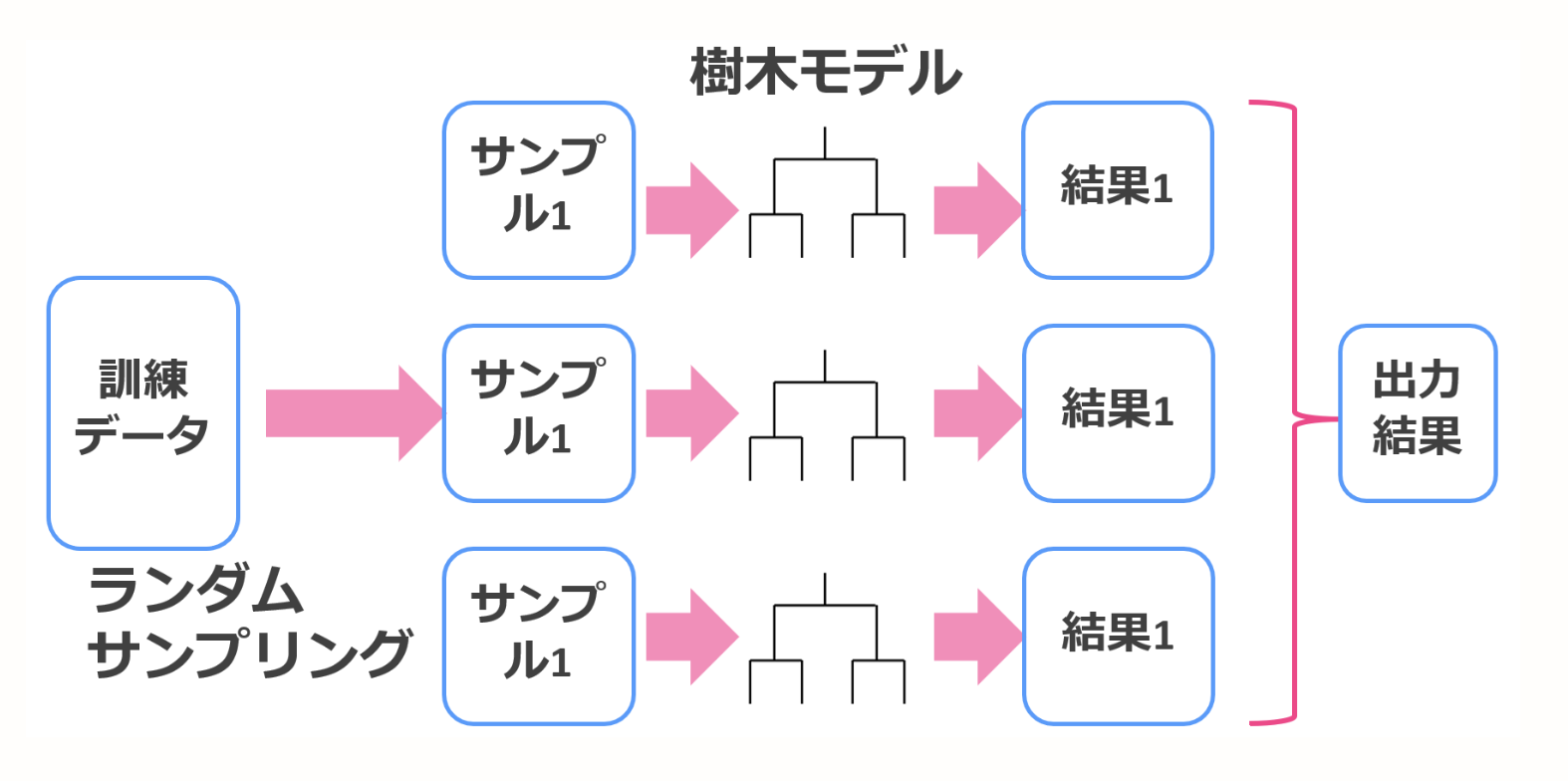 La figure est très facile à comprendre, je vais donc emprunter la figure sur la page de référence.
[Qu'est-ce que l'apprentissage d'ensemble? Différence entre ensachage et boosting](https://toukei-lab.com/ensemble)
La figure est très facile à comprendre, je vais donc emprunter la figure sur la page de référence.
[Qu'est-ce que l'apprentissage d'ensemble? Différence entre ensachage et boosting](https://toukei-lab.com/ensemble)
Booster
Généralement, il a la particularité d'abaisser le biais par rapport à la précision de prédiction du modèle. La stimulation entraîne d'abord le modèle sous-jacent pour établir une ligne de base. Le modèle de base utilisé comme base de référence est traité de manière itérative plusieurs fois pour améliorer la précision. Se concentrer sur la mauvaise prédiction du modèle de base et ajouter du «poids» pour améliorer le modèle suivant. Créez un modèle et créez un nouveau modèle avec des erreurs. Enfin rassemblez tout. xgboost est une implémentation qui utilise ce boost.
Il faut du temps pour apprendre, probablement parce que le premier modèle est pris en compte.
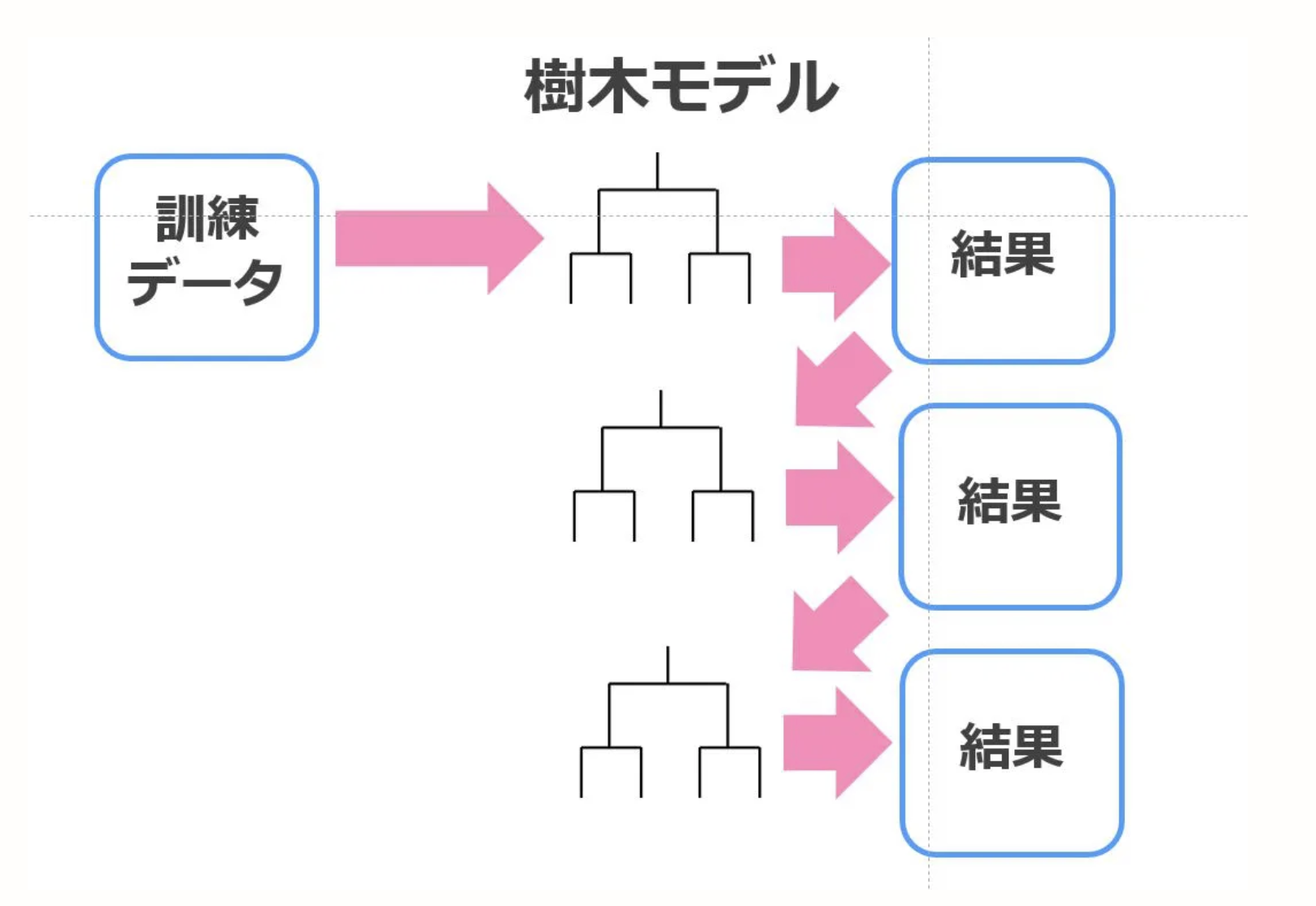 La figure est très facile à comprendre, je vais donc emprunter la figure sur la page de référence.
[Qu'est-ce que l'apprentissage d'ensemble? Différence entre ensachage et boosting](https://toukei-lab.com/ensemble)
La figure est très facile à comprendre, je vais donc emprunter la figure sur la page de référence.
[Qu'est-ce que l'apprentissage d'ensemble? Différence entre ensachage et boosting](https://toukei-lab.com/ensemble)
Empilement
Comment empiler des modèles. Il semble possible d'ajuster et d'incorporer le biais et la variance ... C'était compliqué, je vais donc l'omettre.
Augmentation du dégradé
Un modèle qui apprend en recherchant une direction qui minimise la perte lorsqu'une fonction ou une fonction de perte est définie.
Avoir une image avec une formule mathématique.
Fonction de perte
Un certain indice (= fonction) est utilisé pour juger à quel point la valeur prédite et la valeur réelle sont, et s'il y a une différence. Déplacez les paramètres du modèle afin que l'index soit minimisé.
La fonction de perte de XGBoost est la suivante.
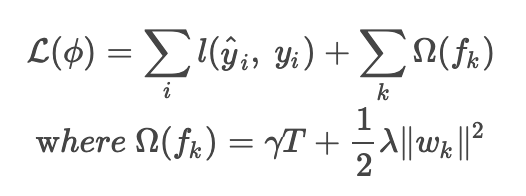 Somme des erreurs entre la valeur prédite et la valeur cible plus le terme de régularisation.
Somme des erreurs entre la valeur prédite et la valeur cible plus le terme de régularisation.
La deuxième équation représente le terme de régularisation. La présence du poids d'arbre de retour w est prise en compte par w lors de la minimisation de la fonction de perte et évite le surentraînement.
L'explication de chaque variable est la suivante.

Optimisation des fonctions
Maintenant que nous avons une fonction de perte, il ne nous reste plus qu'à optimiser la fonction de perte.
Lorsque la fonction de perte ci-dessus est transformée et différenciée par w
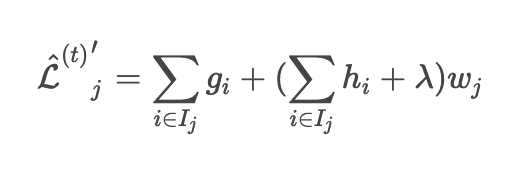 Sera.
Sera.
Lorsque cette équation est 0, w minimise la fonction de perte. (Niveau secondaire en mathématiques)
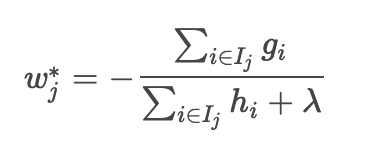 Sera.
Sera.
En substituant cela à une fonction de perte approximative, on obtient la valeur de perte minimale.
Ici, q la structure de XGBoost.  C'est la formule qui évalue xgboost.
C'est la formule qui évalue xgboost.
Déplacer l'échantillon
Utilisez un ensemble de données sur le cancer du sein.
import xgboost as xgb
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
def main():
#Chargement de l'ensemble de données sur le cancer du sein
dataset = datasets.load_breast_cancer()
X, y = dataset.data, dataset.target
#Divisé pour l'apprentissage et la vérification
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.3,
shuffle=True,
random_state=42,
stratify=y)
#Changer le format de l'ensemble de données
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
#Paramètres d'apprentissage
xgb_params = {
#Classification binaire
'objective': 'binary:logistic',
#Index d'évaluation
'eval_metric': 'logloss',
}
#Apprenez avec xgboost
bst = xgb.train(xgb_params,
dtrain,
num_boost_round=100,
)
#Calculé avec les données de vérification
y_pred_proba = bst.predict(dtest)
#Seuil 0.5 à 0,Convertir en 1
y_pred = np.where(y_pred_proba > 0.5, 1, 0)
#Voir la précision
acc = accuracy_score(y_test, y_pred)
print('Accuracy:', acc)
if __name__ == '__main__':
main()
résultat
acc: 0.96
Résumé
xgboost est un modèle qui crée et apprend un modèle en augmentant, et détermine et met à jour les paramètres avec des informations de gradient pendant l'apprentissage.
référence
Tous les apprenants avancés en machine l'utilisent-ils? !! J'expliquerai le mécanisme de l'apprentissage d'ensemble et trois types Qu'est-ce que l'apprentissage d'ensemble? Différence entre ensachage et boosting Explication de l'algorithme de XGBoost en lisant un article
Recommended Posts