Visualisez vos fichiers d'argent de poche avec Dash, le framework Web Python
Préface
Il est souvent nécessaire de visualiser rapidement vos fichiers. Dans un environnement aussi rapide, les non-programmeurs peuvent également utiliser les données, et le monde de l'intuition et des tripes sans fondement peut être transformé en monde de l'intuition et des tripes basées sur les données.
Cette fois, à titre d'exemple familier, j'ai créé une application Dash (pic1) qui peut télécharger les fichiers d'argent de poche affiliés suivants. La colonne de date contient la date, la colonne variable contient le poste de dépense et la colonne de valeur contient le montant. Malheureusement, je n'ai pas de livre de poche, j'utilise donc les données des enquêtes japonaises auprès des ménages.

L'application finale que vous avez créée ressemble à ceci: Vous pouvez sélectionner un fichier en cliquant sur l'outil de téléchargement de fichier, et s'il s'agit de données d'argent de poche avec les trois éléments ci-dessus, un graphique sera créé et vous pouvez également sélectionner et dessiner l'élément.
Vous devez écrire beaucoup de code pour créer quelque chose comme ça! Vous pourriez penser cela. Cependant, la longueur du code de l'application elle-même est de 92 lignes, formatées en noir.
URL de l'application actuelle: https://okodukai.herokuapp.com/ (cela prend un peu de temps pour démarrer car il fonctionne gratuitement) Fichier utilisé: https://github.com/mazarimono/okodukai_upload/blob/master/data/kakei_chosa_long.csv
Environnement de création
L'environnement de création est le suivant.
Windows10 Python 3.8.3 dash 1.13.4 plotly 4.8.2 pandas 1.0.4
Comment faire
Consultez l'article précédent sur la création d'une application Dash.
https://qiita.com/OgawaHideyuki/items/6df65fbbc688f52eb82c
Dash lui-même est un package comme le wrapper Python de React, et l'une de ses fonctionnalités est qu'il facilite la visualisation des données à l'aide d'un package graphique appelé Plotly.
Combinez les composants pour créer une mise en page et utilisez des rappels pour que ces composants fonctionnent de manière interactive.
Composants importants de cette application
Il y a deux points importants dans l'application de téléchargement d'argent de poche.
--Où télécharger les fichiers --La conservation des données
Cela utilise respectivement le composant Upload et le composant Store.
Télécharger le composant
Le composant Upload est un composant permettant de télécharger des fichiers et s'affiche sur l'application comme suit.

Le code ressemble à ceci:
upload.py
dcc.Upload(
id="my_okodukai",
children=html.Div(["Fichier d'argent de poche", html.A("Veuillez utiliser csv ou excel!")]),
style=upload_style,
),
Composant de magasin
Le composant Store n'apparaît pas dans la mise en page, mais il est utilisé pour contenir les données téléchargées. Lorsque l'application télécharge un fichier, il est transmis au composant Store, qui est rappelé pour mettre à jour la sélection d'éléments d'affichage dans la liste déroulante et le graphique est mis à jour.
** Lorsque l'application démarre **

** Téléchargez le fichier **

Rappeler
Les rappels connectent chaque composant et font que chacun fonctionne de manière dynamique. Dans le cas de cette application, nous utiliserons les deux rappels suivants.
- Si les données téléchargées vers le composant de téléchargement sont un fichier CSV ou un fichier Excel, ce sera un bloc de données. Profitez-en pour créer des options de liste déroulante. Puis déposez les données dans le composant Store (1)
- En utilisant les données lues à partir du composant Store, créez les données selon la sélection déroulante et dessinez-les sur le graphique (2)
Le code de rappel pour (1) est le suivant. prevent_initial_call empêche le rappel d'être déclenché au démarrage. Cela ne déclenchera ce rappel que lorsque le fichier sera téléchargé.
@app.callback(
[
Output("my_dropdown", "options"),
Output("my_dropdown", "value"),
Output("tin_man", "data"),
],
[Input("my_okodukai", "contents")],
[State("my_okodukai", "filename")],
prevent_initial_call=True,
)
def update_dropdown(contents, filename):
df = parse_content(contents, filename)
options = [{"label": name, "value": name} for name in df["variable"].unique()]
select_value = df["variable"].unique()[0]
df_dict = df.to_dict("records")
return options, [select_value], df_dict
La fonction parse_content ressemble à ceci: En bref, si le nom du fichier se termine par .csv, il sera lu comme un fichier CSV, et si xls est inclus, il sera lu comme un fichier Excel. Seul utf-8 est pris en charge. En outre, il semble qu'il y ait xls et xlsx dans le fichier Excel, alors je l'ai fait comme ça.
def parse_content(contents, filename):
content_type, content_string = contents.split(",")
decoded = base64.b64decode(content_string)
try:
if filename.endswith(".csv"):
df = pd.read_csv(io.StringIO(decoded.decode("utf-8")))
elif "xls" in filename:
df = pd.read_excel(io.BytesIO(decoded))
except Exception as e:
print(e)
return html.Div(["Une erreur s'est produite lors de la lecture du fichier"])
return df
Le rappel de (2) est le suivant. Cela empêche également le rappel d'être déclenché lorsque l'application est lancée et lorsque la liste déroulante est mise à jour, elle appelle les données et met à jour le graphique.
@app.callback(
Output("my_okodukai_graph", "figure"),
[Input("my_dropdown", "value")],
[State("tin_man", "data")],
prevent_initial_call=True,
)
def update_graph(selected_values, data):
df = pd.DataFrame(data)
df_selected = df[df["variable"].isin(selected_values)]
return px.line(df_selected, x="date", y="value", color="variable")
Regardez une petite enquête sur les ménages japonais
Cela peut finir comme ça, alors jetons un coup d'œil à l'enquête sur les ménages japonais. Pour le moment, les données remontent à mai.
Premièrement, si l'on considère les dépenses de consommation, qui représentent la consommation globale, elles ont fortement baissé en avril et mai.

Non, quand j'ai encouragé la consommation de lait, j'ai vu que c'était efficace, merci, mais quand j'ai regardé comment c'était, ça semblait être vrai. Je suis retourné dans mon enfance et j'ai bu beaucoup de lait. Du lait sans alcool! !! !!

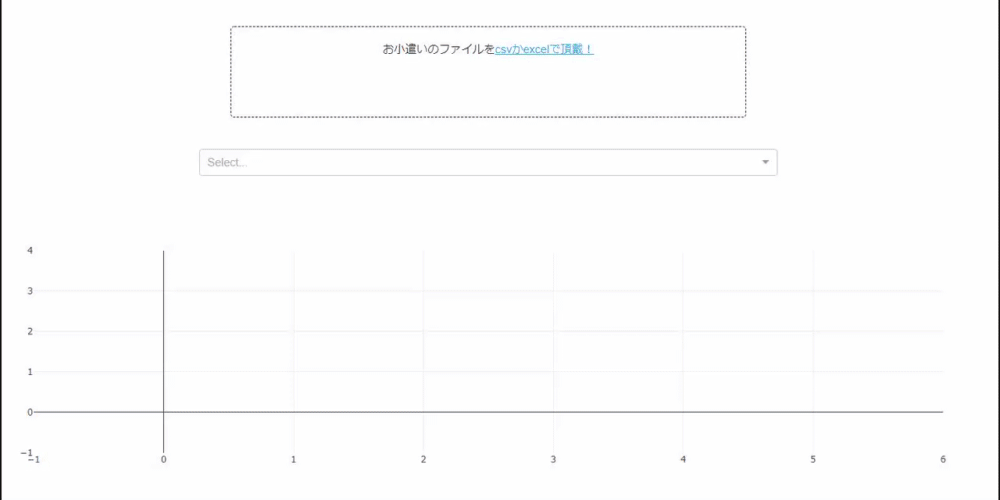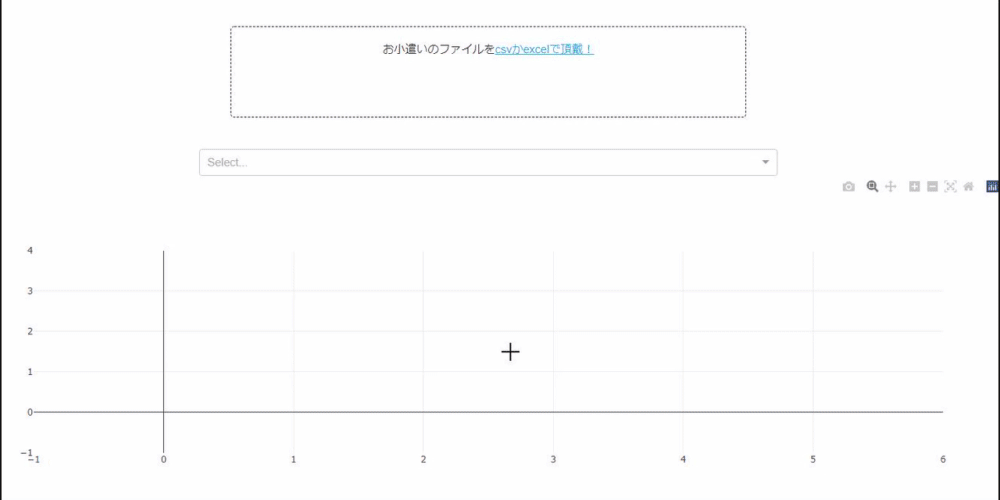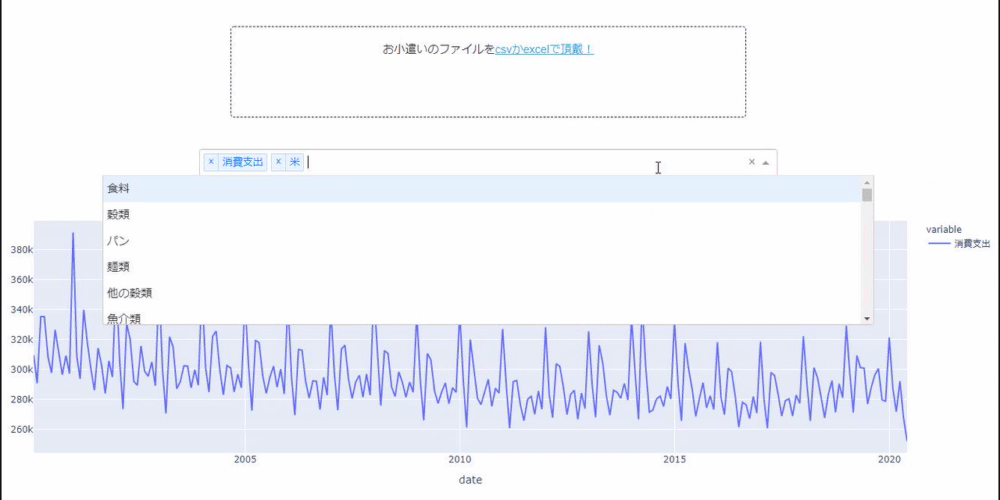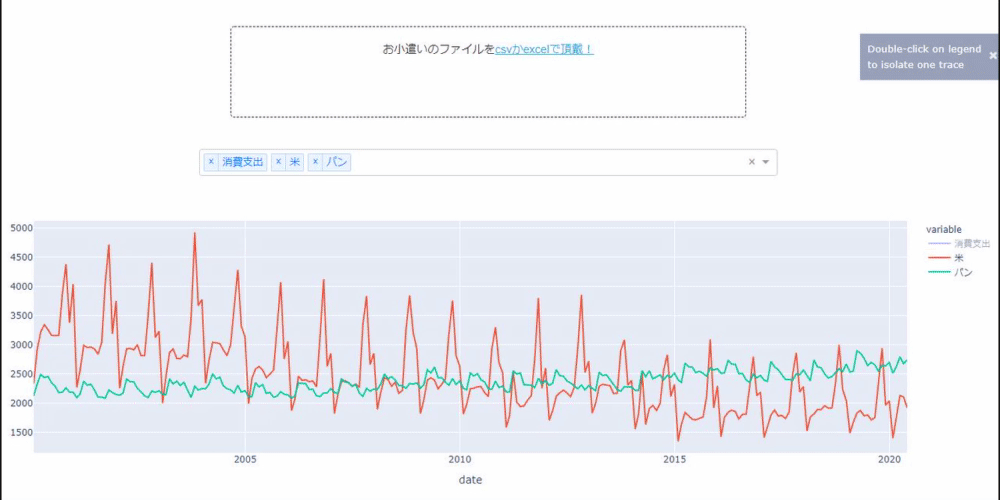
Eh bien, si vous avez des tendances intéressantes à propos de Corona, je vous serais reconnaissant de la laisser dans les commentaires. C'est un peu lent, probablement parce que c'est un cadre libre, mais soyez patient. Je m'intéressais au riz ou au pain pour lequel je dépensais de l'argent. Je suis définitivement américaine, mais mes filles ne mangent que du pain. Je me demandais pourquoi ...

Il semble que c'est moi qui ai été laissé pour compte. Il y a plus de poisson et de viande comme ça, mais je comprends ce sentiment parce que je suis une secte de la viande.
Résumé
Avec la sensation ci-dessus, vous pouvez facilement créer un outil qui visualise immédiatement les fichiers standard que vous avez. Il y a également des demandes de soutien supplémentaire, mais je me demande s'il est nécessaire de faire des coupes dans ce domaine du point de vue du stockage des données.
DX votre propre vie! !! C'est comme ça?
URL de l'application: https://okodukai.herokuapp.com/ github: https://github.com/mazarimono/okodukai_upload
Le code sur github est ce que app_heroku.py donne à Herok.
Code d'application
app.py
import base64
import io
import dash
import dash_core_components as dcc
import dash_html_components as html
import pandas as pd
import plotly.express as px
from dash.dependencies import Input, Output, State
upload_style = {
"width": "50%",
"height": "120px",
"lineHeight": "60px",
"borderWidth": "1px",
"borderStyle": "dashed",
"borderRadius": "5px",
"textAlign": "center",
"margin": "10px",
"margin": "3% auto",
}
external_stylesheets = ["https://codepen.io/chriddyp/pen/bWLwgP.css"]
app = dash.Dash(__name__, external_stylesheets=external_stylesheets)
app.config.suppress_callback_exceptions = True
app.layout = html.Div(
[
dcc.Upload(
id="my_okodukai",
children=html.Div(["Fichier d'argent de poche", html.A("Veuillez utiliser csv ou excel!")]),
style=upload_style,
),
dcc.Dropdown(
id="my_dropdown", multi=True, style={"width": "75%", "margin": "auto"}
),
dcc.Graph(id="my_okodukai_graph"),
dcc.Store(id="tin_man", storage_type="memory"),
]
)
def parse_content(contents, filename):
content_type, content_string = contents.split(",")
decoded = base64.b64decode(content_string)
try:
if filename.endswith(".csv"):
df = pd.read_csv(io.StringIO(decoded.decode("utf-8")))
elif "xls" in filename:
df = pd.read_excel(io.BytesIO(decoded))
except Exception as e:
print(e)
return html.Div(["Une erreur s'est produite lors de la lecture du fichier"])
return df
@app.callback(
[
Output("my_dropdown", "options"),
Output("my_dropdown", "value"),
Output("tin_man", "data"),
],
[Input("my_okodukai", "contents")],
[State("my_okodukai", "filename")],
prevent_initial_call=True,
)
def update_dropdown(contents, filename):
df = parse_content(contents, filename)
options = [{"label": name, "value": name} for name in df["variable"].unique()]
select_value = df["variable"].unique()[0]
df_dict = df.to_dict("records")
return options, [select_value], df_dict