Basic Linear Algebra Learned in Python (Part 1)
We will implement linear algebra in python.
Since I have just studied, there are some parts that I have not yet understood, but I would like to do it.
First, a simple understanding of vectors and matrices
First of all, we will import the library to be used this time.
import numpy as np
import scipy as sp
import sympy as sy
About scalars and vectors
A scalar is one that has only a size. For example, real numbers such as 5 and -10, which are used casually, correspond to this.
Next is the vector, which is the one that adds the orientation in addition to the size of the scalar. It is often represented by the letters a and b.
About the norm
A norm is a vector (eg a))Refers to the size of||a||Can be expressed as.
About inverse vector, zero vector, and unit vector
A vector can be multiplied by k from its original value using a variable, such as a real number. For example, use the letter k and put k = 5. Then put the original vector as a. You can multiply this original a vector by a scalar (k). Using this, when k = -1, multiplying by a scalar gives -a. This vector is called the inverse vector ** of ** a.
If you set k = 0 and multiply it by a scalar in the same way, it becomes 0, which is called ** zero vector **.
The normalization of a vector of a certain magnitude is called a ** unit vector **. What it means is a vector whose magnitude is converted to 1. The unit vector can be expressed as follows.
For example, suppose you have a vector of magnitude 4. If you apply it to the above formula, it will be 1 properly.
Let's do it with python immediately.
a = np.array([1, 2, 3])
k = [4, 1.5, -1, 0]
print(a * k[0]) #[4, 8, 12]
print(a * k[1]) #[1.5, 3, 4.5]
print(a * k[2]) #[-1, -2, -3]Inverse vector
print(a * k[3]) # [0, 0, 0]Zero vector
Now let's implement the norm. This time I have imported the norm from scipy, but since it is also in numpy, I can implement it there as well.
from scipy.linalg import norm
a = np.array([3, 4])
n = linalg.norm(a)
print(n)## 5
What happened with the above program is as follows. Each value is squared to take the square root. This is the norm. In fact, machine learning is used to adjust parameters such as neural networks. (For example, L1 norm or L2 norm)
Now let's implement the identity matrix. As I confirmed earlier, the unit vector is to normalize a vector that keeps its original orientation to a vector with a length of 1. Let's implement it based on the a vector implemented earlier.
a = np.array([3, 4])
n = norm(a)
b = a / n
print(n) # [0.6, 0.8]
inner product
Next, let's take the inner product of the vectors. ** Inner product ** is the multiplication of two vectors (a, b). Now, let's define each vector of a and b as follows. Let's implement it in python. You can find it using the dot in numpy.
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
c = np.dot(a, b)
print(c)#32
What's happening with this program? The following is happening.
Each ingredient is added together. This is the inner product.
Also, let's actually find the angle generated by each vector. In high school textbooks, it was expressed by the following formula. Let's actually ask for it.
def get_cos(a, b):
inner_product = np.dot(a, b)
a_norm = norm(a)
b_norm = norm(b)
cos_theta = inner_product / (a_norm * b_norm)
return cos_theta
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
get_cos(a,b)#0.6220084679281461
I was able to ask. It's a decimal number and it's kind of hard to understand. Here comes ** SymPy **. SymPy is a library that performs computer algebra with python. Even if I say that, I don't think it will come into focus, so I will actually touch it. If you use Sympy, it will be returned in a beautiful state as shown below. It's written a little differently from numpy, but it's mostly the same, so try using it.
import sympy as np
a = sy.Matrix([[1, 2, 3]])
print(a.shape)
display(a)
#(1, 3)
#numpy returns:
array([[1, 2, 3]])
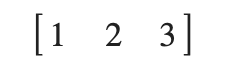
It's a little off, but let's use this to actually find the angle.
def get_angle(a, b):
a_v = sy.Matrix(a)
b_v = sy.Matrix(b)
norm_a = a_v.norm(ord=2)
norm_b = b_v.norm(ord=2)
inner_product = a_v.dot(b_v)
return inner_product / (norm_a * norm_b)
a = [5, 2, 5]
b = [4 ,1, 1]
The answer is:
Converting this to an angle gives 30 °.
By asking for this cosine, you can find what is called ** orthographic projection **. Orthogonal projection is the shadow that b casts on a when two vectors are given as follows, and when light shines perpendicular to a. The normal projection can be calculated by the following formula.
queue
Next, let's look at the matrix. I think those who have touched python often use it. The following is called a matrix. The part composed of the combination of 1 and 2 and the combination of 3 and 4 is called the ** line ** and is called the first line and the second line. The part consisting of 1,3 and 2,4 is called ** column **. In total, the following matrix is expressed as a 2-by-2 matrix. And the numbers and letters included in the following matrix are called components. For example, the number 3 is located in the second row and first column. This case is called ** (2, 1) component **. To give another example, the component of (2,2) can be regarded as 4, and the component of (1,1) can be regarded as 1.
A =
\left(
\begin{matrix}
1 & 2\\\
3 & 4
\end{matrix}
\right)
As I mentioned a little earlier, let's use python to generate a matrix. You can generate a beautiful matrix by using sympy. (It seems that sympy is not displayed in Google Colaboratory?)
a = np.array([[1, 2,
3, 4]])
print(a.shape)#(2, 2):Meaning a 2-by-2 matrix
print(a)
a = sy.Matrix([[1, 2,
3, 4]])
Zero matrix and identity matrix
Next, we will introduce ** zero matrix ** and ** identity matrix **. I also introduced the vector part briefly. ** A zero matrix is a matrix with all components zero **. An identity matrix is a matrix with all 1 diagonal components **. Let's implement it with python immediately.
O = np.zeros((2, 2))
print(O.shape)
print(O)
#(2, 2)
[[0. 0.]
[0. 0.]]
E = np.eye(2, 2)
print(E.shape)
print(E)
#(2, 2)
[[1. 0.]
[0. 1.]]
O = sy.zeros(2, 2)
print(O.shape)
O
E = sy.eye(2, 2)
print(E.shape)
E
O =
\left(
\begin{matrix}
0 & 0\\\
0 & 0
\end{matrix}
\right)
E =
\left(
\begin{matrix}
1 & 0\\\
0 & 1
\end{matrix}
\right)
Inverse matrix
The following is the ** inverse matrix **. The matrix that satisfies AB = BA = E is called the ** inverse matrix ** of A. The inverse matrix is expressed as follows.
But it doesn't look like this:
When the A matrix is expressed as follows, the inverse matrix can be expressed as follows.
If ** ad-bc = 0, the inverse matrix does not exist **. By using this inverse matrix, you can ** easily solve simultaneous equations **. (Not dealt with this time)
Cayley-Hamilton's theorem
Next, I would like to introduce ** Cayley-Hamilton's theorem **. Given the matrix as follows, Cayley-Hamilton's theorem can be expressed as:
Primary conversion
The next thing to deal with is ** primary conversion **. You can move points, straight lines, etc. by multiplying the matrix. So the typical point I will introduce the movement of.
There are four ways to move points. ・ Move symmetrically with respect to the x-axis ・ Move symmetrically with respect to the y-axis ・ Move symmetrically with respect to the origin ・ Symmetrically move with respect to y = x
Move symmetrically with respect to the x-axis
Move symmetrically with respect to the y-axis
Move symmetrically with respect to the origin
Move symmetrically with respect to y = x
Point movement is possible by multiplying the above matrix by the original matrix. This time is over. I will implement it with python.
def x_axis(x):
transformed = np.dot(x, np.array([[1, 0], [0, -1]]))
return transformed
def y_axis(x):
transformed = np.dot(x, np.array([[-1, 0]], [0, 1]))
return transformed
def origin(x):
transformed = np.dot(x, np.array([[-1, 0], [0, -1]]))
return transformed
def y_x(x):
transformed = np.dot(x, np.array([[0, 1], [1, 0]]))
return transformed
x = np.array([2, 3])
x_axis(x)#array([ 2, -3])
a = np.array([2, -3])
y_x(a)#array([-3, 2])
It's done. Next time, I will continue to do the basics of linear algebra.
Reference material
・
Recommended Posts