Make a Discord Bot that you can search for and paste images
I made a bot that can search images, so I will write the knowledge at that time.
What I made
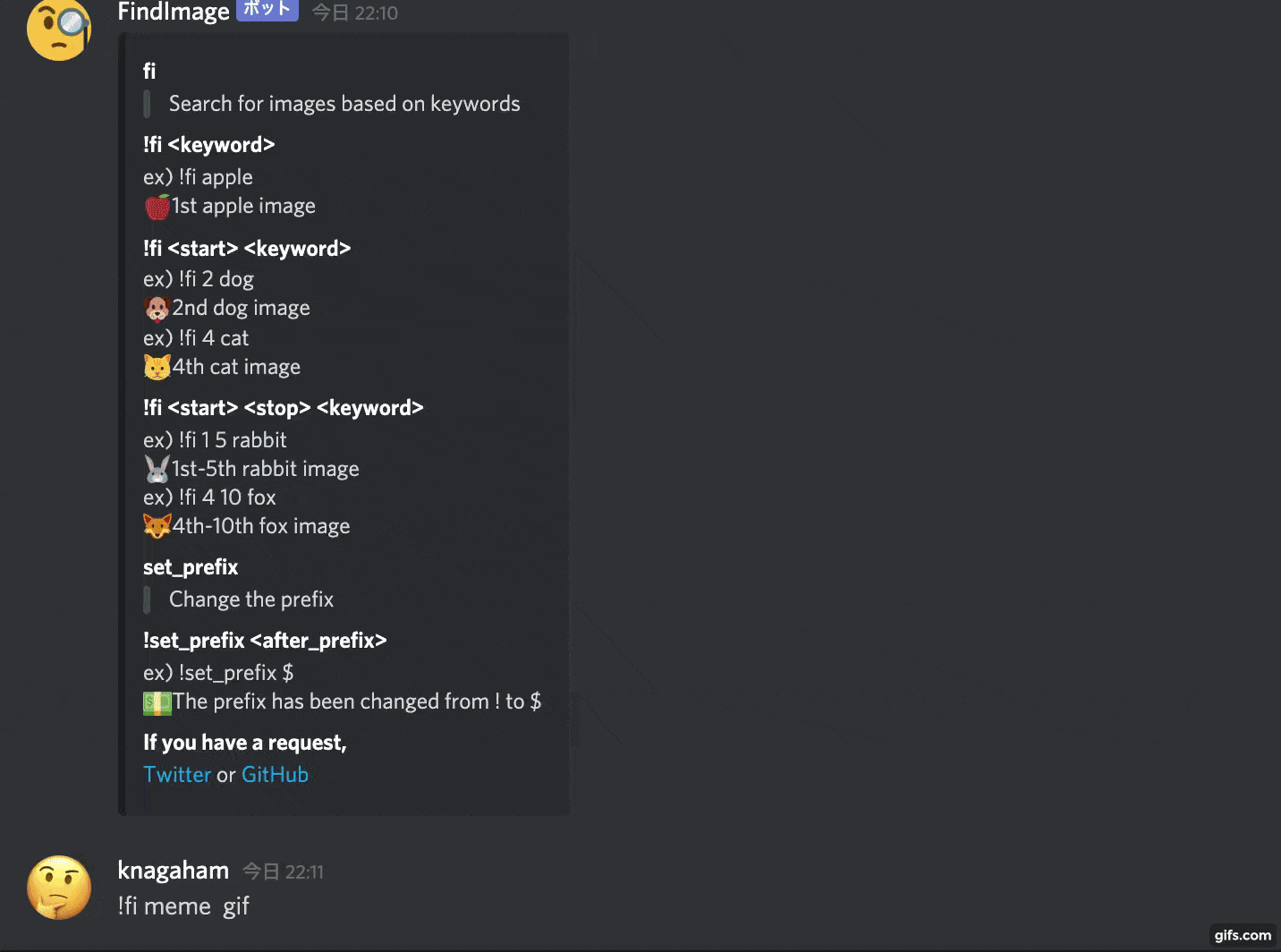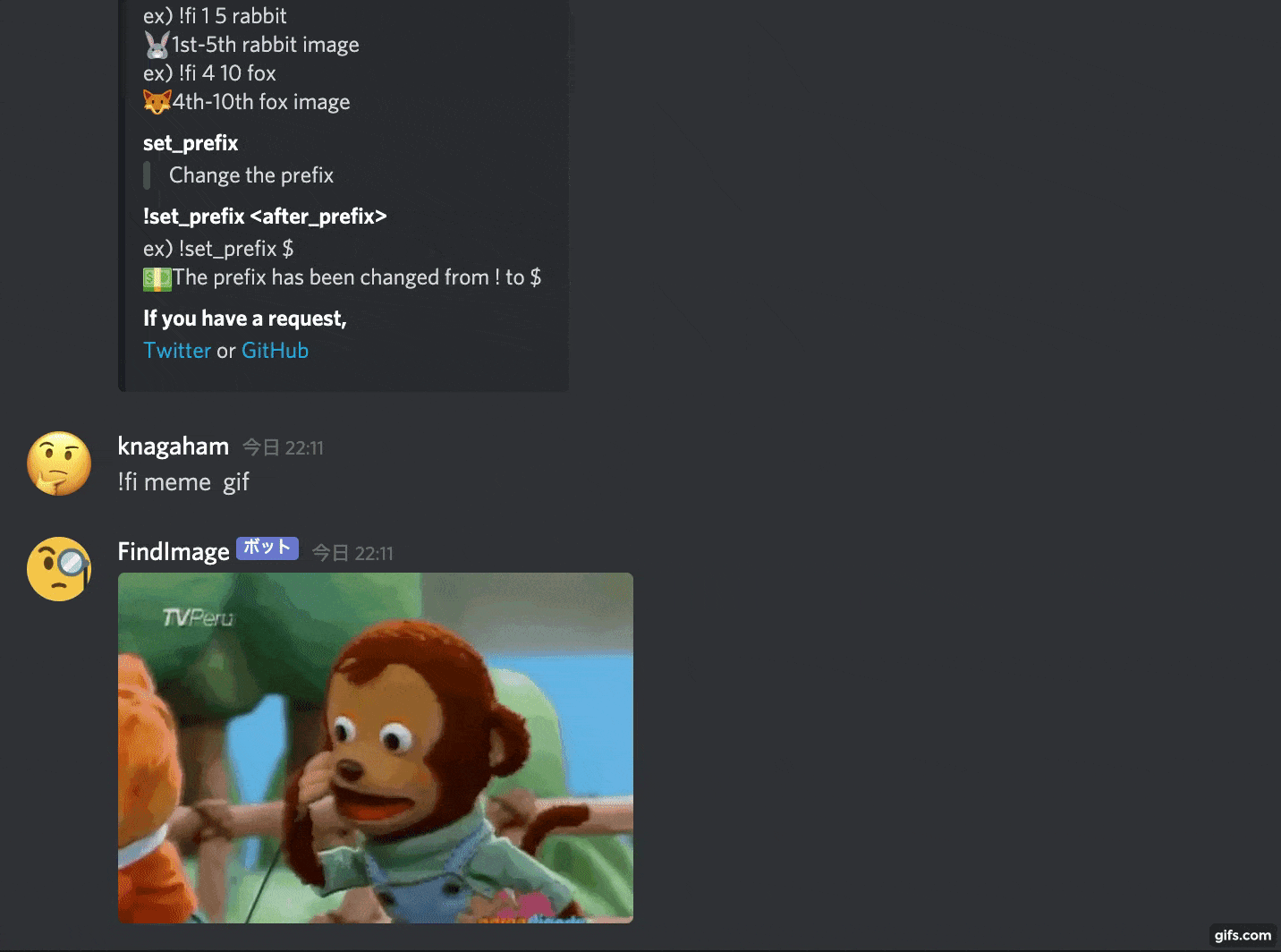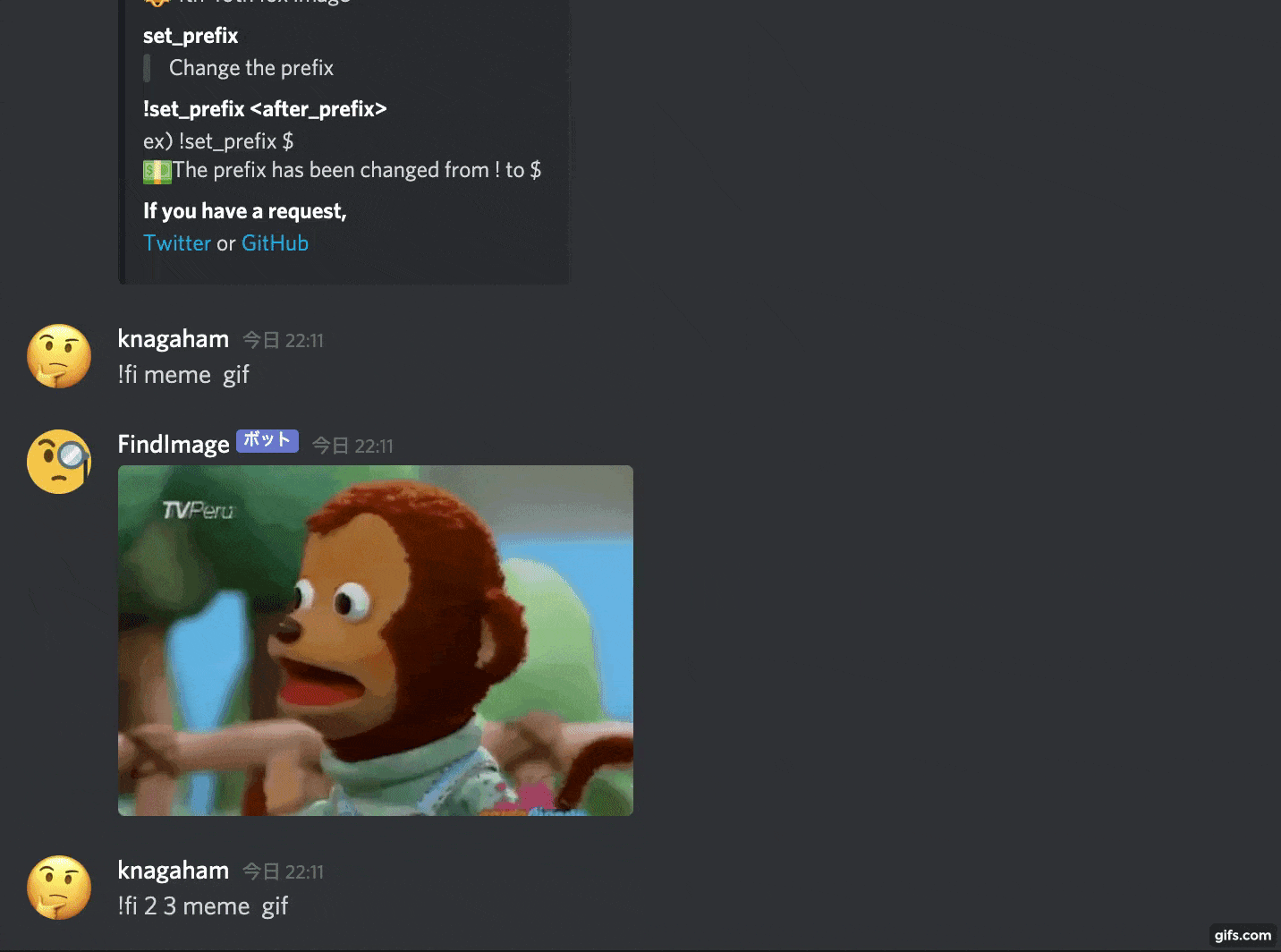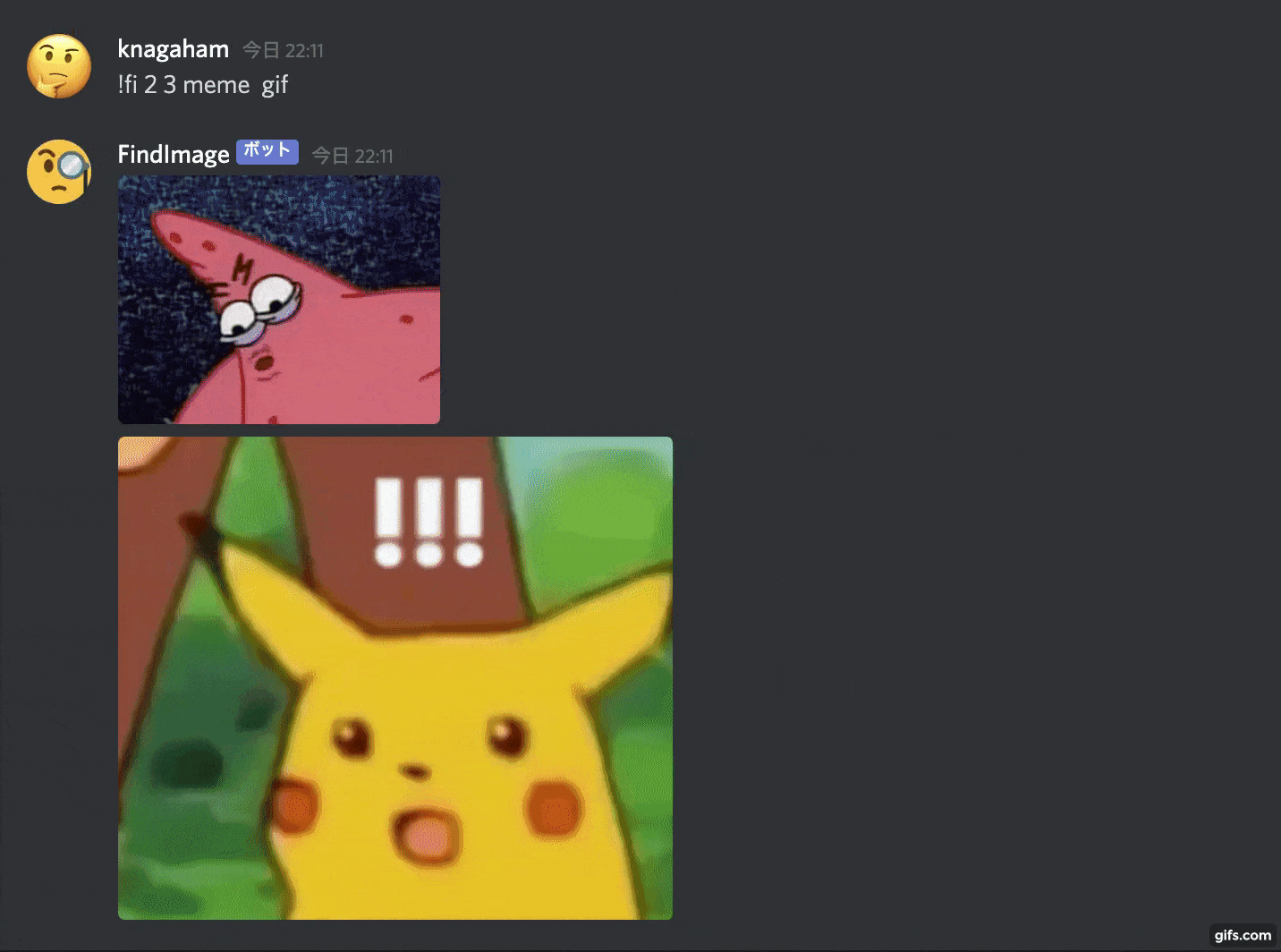
With this kind of feeling, it will search for an image from the given keyword and paste it.
Installation can be done from here, so please do not hesitate to contact us
Source code (github)
environment
- python 3.7.9
- discord.py 1.5.1
- bs4 0.0.1
- psycopg2 2.8.6
- urllib3 1.25.11
How to use Discord.py
Created with reference to this article did. If you haven't touched Discord.py, we recommend reading this first.
Search for images and get url
Get image search results
Use urllib to search for the image and get the html. At this time, the content of html will change, so be sure to specify User-Agent.
find_image.py
from urllib import request as req
from urllib import parse
def find_image(keyword):
urlKeyword = parse.quote(keyword)
url = 'https://www.google.com/search?hl=jp&q=' + urlKeyword + '&btnG=Google+Search&tbs=0&safe=off&tbm=isch'
headers = {"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0",}
request = req.Request(url=url, headers=headers)
page = req.urlopen(request)
html = page.read()
page.close()
return html
Get image url
Normally, when you get an image by scraping, you can get it from the img tag, but in the case of Google image search, you can only get a compressed image. So, in order to get the original image, you have to click to get it like this article on Selenium etc. , I am taking another method this time considering the load and speed. As an advertisement, I wrote an article about the tips for speeding up Beautiful Soup, so please refer to here if you like.
When User-Agent is specified in the browser, the method call is implemented in the sctipt tag as shown below, so use it.
python
<script nonce>
AF_initDataCallback({
key: 'ds:1',
isError: false,
hash: '2',
data: [null, [
[
["g_1", [
["Fresh cream", ["https://encrypted-tbn0.gstatic.com/images?q\u003dtbn%3AANd9GcR_QK2ghJ5WWcj-Tcf9znnP6_rZwe7f2MCwWUERoVqVLNRFsj4D\u0026usqp\u003dCAU", null, null, true, [null, 0], false, false], "/search?q\u003d%E3%83%97%E3%83%AA%E3%83%B3\u0026tbm\u003disch\u0026chips\u003dq:%E3%83%97%E3%83%AA%E3%83%B3,g_1:%E7%94%9F+%E3%82%AF%E3%83%AA%E3%83%BC%E3%83%A0:FuBfrMHhliU%3D", null, null, [null, null, null, null, "q:Pudding,g_1:Fresh cream:FuBfrMHhliU\u003d"], 0],
["convenience store", ["https://encrypted-tbn0.gstatic.com/images?q\u003dtbn%3AANd9GcThveHaG9uvSFj6QwXIVDoJPs9P3KjNdnl-I35Wf0WzAKNffK_m\u0026usqp\u003dCAU", null, null, true, [null, 0], false, false], "/search?q\u003d%E3%83%97%E3%83%AA%E3%83%B3\u0026tbm\u003disch\u0026chips\u003dq:%E3%83%97%E3%83%AA%E3%83%B3,g_1:%E3%82%B3%E3%83%B3%E3%83%93%E3%83%8B:tHwRIJyFAco%3D", null, null, [null, null, null, null, "q:Pudding,g_1:convenience store:tHwRIJyFAco\u003d"], 1],
.......
However, since this is a songwriter and the location when searching differs depending on the keyword, it can not be acquired with xpath or css selector, it can not be narrowed down because there is no attribute specified, and after expanding the variable Because it is in json format, it cannot be easily converted to json data. So I pushed ** Gori **. First, get all the script tags, find the content starting with AF_initDataCallback, and forcibly format it so that json can read it. However, since the structure is not a dictionary type but an array, the index is fixed and acquired. To be honest, the method of slekiping is below, but I compromised with this implementation because speed is required like this bot.
find_image.py
import bs4
def scrap_image_urls(html, start = 0, stop = 1)):
soup = bs4.BeautifulSoup(html, 'html.parser', from_encoding='utf8')
soup = soup.find_all('script')
data = [c for s in soup for c in s.contents if c.startswith('AF_initDataCallback')][1]
data = data[data.find('data:') + 5:data.find('sideChannel') - 2]
data = json.loads(data)
data = data[31][0][12][2]
image_urls= [x[1][3][0] for x in data if x[1]]
image_urls= [url for url in image_urls if not is_exception_url(url)][start:stop]
return image_urls
However, sites that take measures against scraping such as Instagram are playing because they cannot get the url.
find_image.py
exception_urls = [
'.cdninstagram.com',
'www.instagram.com'
]
def is_exception_url(str):
return any([x in str for x in exception_urls])
Dynamically change the Prefix
Implemented the function to convert prefix (prefix added at the beginning of command). There are many ways to do this, but this time I'm using Heroku Postgres. At first, I managed it with a json file, but since heroku is reset every day, the data was blown away. .. .. The flow of deploying to heroku is [First introduced article](https://qiita.com/1ntegrale9/items/9d570ef8175cf178468f#%E3%81%AF%E3%81%98%E3%82%81%E3% Please refer to 81% AB) for details. ** You need to install the psql command. ** **
Add Heroku Postgres add-on
Add add-ons with the free plan hobby-dev. The maximum number of record lines is 10K.
$ heroku addons:create heroku-postgresql:hobby-dev -a [APP_NAME]
Access to database
First, check the created database name. See the Add-on line
heroku pg:info -a discordbot-findimage
Then access the database. Please use the database name you got earlier
heroku pg:psql [DATABASE_NAME] -a [APP_NAME]
Now that you can execute the SQL, create a table.
create table guilds (
id varchar(255) not null,
prefix varchar(255) not null,
PRIMARY KEY (id)
);
Access PostgreSQL from Python
This time, I am using psycopg2. The url of the database is defined in the environment variable at the time of creation, so use it.
find_image.py
import psycopg2
db_url = os.environ['DATABASE_URL']
conn = psycopg2.connect(db_url)
Dynamically apply prefix for each Discord server
Since discord.Client can pass a method in the constructor, pass it when instantiating. The example uses ** discord.ext.commands.Bot **, which is a child class of discord.Client.
find_image.py
from discord.ext import commands
import psycopg2
defalut_prefix = '!'
table_name = 'guilds'
async def get_prefix(bot, message):
return get_prefix_sql(str(message.guild.id))
def get_prefix_sql(key):
with conn.cursor() as cur:
cur.execute(f'SELECT * FROM {table_name} WHERE id=%s', (key, ))
d = cur.fetchone()
return d[1] if d else defalut_prefix
bot = commands.Bot(command_prefix=get_prefix)
Set Prefix for each Discord server
In this case, the UPSERT query runs when the set_prefix command is executed.
find_image.py
from discord.ext import commands
import psycopg2
table_name = 'guilds'
def set_prefix_sql(key, prefix):
with conn.cursor() as cur:
cur.execute(f'INSERT INTO {table_name} VALUES (%s,%s) ON CONFLICT ON CONSTRAINT guilds_pkey DO UPDATE SET prefix=%s', (key, prefix, prefix))
conn.commit()
@bot.command()
async def set_prefix(ctx, prefix):
set_prefix_sql(str(ctx.guild.id), prefix)
await ctx.send(f'The prefix has been changed from {ctx.prefix} to {prefix}')
Finally
Thank you for reading this far! I hope it will be helpful when creating and scraping Discord Bot!
Recommended Posts