3. Natural language processing with Python 5-5. Emotion value analysis of Japanese sentences [Japanese evaluation polarity dictionary (words)]
- This is the third trial of the Japanese emotion value dictionary.
- Continuing from the previous "Japanese Evaluation Polar Dictionary (Noun Edition)", in this article, I will use ** "Japanese Evaluation Polar Dictionary (Verb Edition)" **. ** A word is a word to be used, that is, a kind of verb, adjective, and adjective verb **.
- In other words, there are some difficult uses for sentence-based sentiment analysis, but we will try to deepen our consideration of the dictionary while following the previous processing procedure.
(1) Acquisition and preprocessing of "Japanese Evaluation Polar Dictionary (Terms)"
1. Load dictionary data onto Colab
import pandas as pd
#Control the misalignment of column names and values in consideration of double-byte characters
pd.set_option("display.unicode.east_asian_width", True)
#Reading the emotion value dictionary
pndic_1 = pd.read_csv(r"http://www.cl.ecei.tohoku.ac.jp/resources/sent_lex/wago.121808.pn",
names=["judge_type_word"])
print(pndic_1)

- The total number of recorded words is 5,280, but it can be seen that there are multiple lines depending on the variation of conjugation.
- Since the text to be analyzed becomes a list of the original forms of words by morphological analysis, it is necessary to preprocess the dictionary in advance so that it becomes a set of "Dashing: Positive" in the above example.
2. Expand the data frame with a delimiter
- First, with
\ tas the delimiter, divide it into the emotion value part including positive/negative and the word part including conjugation and expand it into two columns.
pndic_2 = pndic_1["judge_type_word"].str.split('\t', expand=True)
print(pndic_2)

3. Delete unnecessary parts of emotion value positive/negative
- Check how the data is in the emotion value column, including positive/negative.
judge = pd.Series(pndic_2[0])
judge.value_counts()

- The dictionary uses four patterns that combine "positive/negative" and "evaluation/experience" as emotion value judgments.
- Since only "Positive/Negative" is required for sentiment analysis of sentences, the part in () that indicates the distinction between "Evaluation/Experience" is deleted.
pndic_2[0] = pndic_2[0].str.replace(r"\(.*\)", "", regex=True)
print(pndic_2)

4. Confirm the registered contents of the wording part
- Information such as utilization is included in the word part of the second column, but in order to use it as a reference source for acquiring emotional values, it is necessary to converge them in the original form of the word.
- Prior to that, in order to grasp the status of the data, expand it into multiple columns using a half-width space as a delimiter.
df_temp = pndic_2[1].str.split(" ", expand=True)
print(df_temp)
- You can see that there are up to 9 words in the column. Then check the number of non-None records for each expanded column.
df_temp.info()
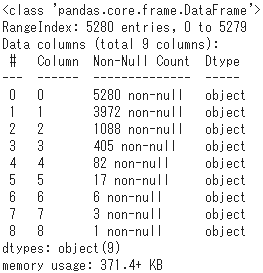
- 75% of all 5,280 words, or 3,972 words, have at least one conjugation that follows the stem.
- As an attempt, let's take a look at the contents of 3 records that have inflected parts of 7 words or more. First, get the three words in column [7].
v = pd.Series(df_temp[7])
v.value_counts()
- Next, all these registration details are output.
print(df_temp[df_temp[7] == "painful"])
print(df_temp[df_temp[7] == "Nu"])
print(df_temp[df_temp[7] == "Is"])

- Although only a few examples, the reality is that these phrases are given positive/negative emotional values as one record.
- For example, it is not possible to give [Positive] as an emotional value to each word of "eye/no/middle/to/put/te/mo/pain/not", but it corresponds to the stem. Nor can the "eyes" be used to represent the meaning of this phrase.
- Alternatively, some phrases may have some positive/negative combinations.
- Therefore, although it is a painstaking measure, ➀ those with three or more inflected parts are excluded, and ➁ only the stem is used as a reference destination based on the morphological analysis result.
5. Screening of dictionary data
- Join the emotion value positive/negative column to the data frame
temp_dfof the word part.
pndic_3 = pd.concat([df_temp, pndic_2[0]], axis=1)
print(pndic_3)

- Excludes those that have 3 or more inflection parts, so the number of records is 4,875 as a result of leaving records with column [3] of None and deleting the others.
pndic_4 = pndic_3[pndic_3[3].isnull()]
print(pndic_4)

- Get two columns, "Stem" and "Positive/Negative", that is, delete the other columns.
pndic_5 = pndic_4[0]
print(pndic_5)

- Duplicate records are the variations of utilization that have the same stem, so convert them to unique data without duplication.
pndic_6 = pndic_5.drop_duplicates(keep='first')
pndic_6.columns = ["word", "judge"]
print(pndic_6)

6. Convert dictionary data to dict type
- Replace the emotion value "Positive/Negative" with the number [Positive: +1, Negative: -1].
pndic_6["judge"] = pndic_6["judge"].replace({"Positive":1, "negative":-1})
print(pndic_6)

- Use
dict ()to convert the column"word"to the key and the column"judge"to the dictionary type, and use it as the reference source to get the emotion value.
import numpy as np
keys = pndic_6["word"].tolist()
values = pndic_6["judge"].tolist()
dic = dict(zip(keys, values))
print(dic)

⑵ Preprocessing of the text to be analyzed
- Starting with the text to be analyzed, the subsequent processing follows the previous and previous "Word Emotion Polarity Value Correspondence Table" and "Japanese Evaluation Polarity Dictionary (Noun Edition)". To do.
1. Specify the text
text = 'The nationwide import volume of spaghetti reached a record high by October, and customs suspects that the background is the so-called "needing demand" that has increased due to the spread of the new coronavirus infection. According to Yokohama Customs, the amount of spaghetti imported from ports and airports nationwide was approximately 142,000 tons as of the end of October. This was a record high, exceeding the import volume of one year three years ago by about 4000 tons. In addition, macaroni also had an import volume of more than 11,000 tons by October, which is almost the same as the import volume of one year four years ago, which was the highest ever.'
lines = text.split("。")

2. Create an instance of morphological analysis
- Install MeCab.
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.7
- Import MeCab and instantiate it with output mode
'-Ochasen'. - Although it is not related to a series of processing, the morphological analysis result on the first line is shown as an example.
import MeCab
mecab = MeCab.Tagger('-Ochasen')
#Illustrate the results of morphological analysis on the first line
print(mecab.parse(lines[0]))

3. List by sentence based on morphological analysis
#Extract words based on morphological analysis
word_list = []
for l in lines:
temp = []
for v in mecab.parse(l).splitlines():
if len(v.split()) >= 3:
if v.split()[3][:2] in ['noun','adjective','verb','adverb']:
temp.append(v.split()[2])
word_list.append(temp)
#Remove empty element
word_list = [x for x in word_list if x != []]

(3) Positive / negative judgment of sentences based on emotional polarity value
- Get the word and its ** emotion polarity value ** for each sentence and output it to the data frame.
result = []
#Sentence-based processing
for sentence in word_list:
temp = []
#Word-based processing
for word in sentence:
word_score = []
score = dic.get(word)
word_score = (word, score)
temp.append(word_score)
result.append(temp)
#Display as a data frame for each sentence
for i in range(len(result)):
df_ = pd.DataFrame(result[i], columns=["word", "score"])
print(lines[i], '\n', df_.where(df_.notnull(), None), '\n')

- The results of all 4 rows are shown in the table below in order from the left.
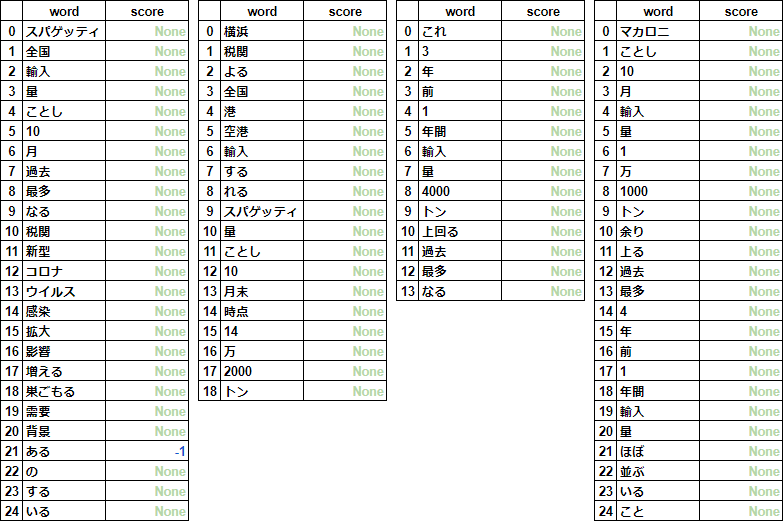
- Almost all of them are None, and many words are unregistered because it is a dictionary limited to words.
- Since it is not necessary to calculate the average value for each sentence, the subsequent processing is limited to checking the positive/negative composition ratio of the dictionary, and as a conclusion, consider the requirements desired for the emotion value dictionary.
⑷ Positive/negative composition ratio of "Japanese Evaluation Polar Dictionary (Words)"
#Number of positive words
keys_pos = [k for k, v in dic.items() if float(v) == 1]
cnt_pos = len(keys_pos)
#Number of negative words
keys_neg = [k for k, v in dic.items() if float(v) == -1]
cnt_neg = len(keys_neg)
print("Percentage of positives:", ('{:.3f}'.format(cnt_pos / len(dic))), "(", cnt_pos, "word)")
print("Percentage of negatives:", ('{:.3f}'.format(cnt_neg / len(dic))), "(", cnt_neg, "word)")

⑸ Requirements for sentiment value dictionary and sentiment analysis tool [Discussion]
- So far, we have looked at emotion value dictionaries and emotion value analysis tools for English and Japanese. The table below summarizes the basic specifications and features of each.
| supported language | name | Type | Number of recorded words | Contents recorded | Emotional polarity value | Notices |
|---|---|---|---|---|---|---|
| English | AFFIN-111 | Emotion value dictionary | 2,477 | Nouns, adjectives, verbs, adverbs, exclamations, etc. | INTEGER [-4, +4] | Positive:negative= 3.5 : 6.5, neutral 1 word only |
| English | VADER | Emotion value analysis tool | 7,520 | Nouns, adjectives, verbs, adverbs, exclamations, slang, emoticons, etc. | FLOAT [-1, +1] | Inversion of polarity by negation, amplification processing of polarity value |
| Japanese | Word emotion polarity value correspondence table | Emotion value dictionary | 55,125 | Nouns, verbs, adverbs, adjectives, auxiliary verbs | FLOAT [-1, +1] | Positive:negative= 1 :Significant negative bias at 9 |
| Japanese | Japanese評価極性辞書(noun編) | Emotion value dictionary | 13,314 | noun | STRING [p, n, e] | Positive/Negative ratio almost equilibrium, including very few overlaps |
| Japanese | Japanese評価極性辞書(Words編) | Emotion value dictionary | 5,280 | Words | STRING [Positive,negative] | Overall 3/About 4 is "stem"+Has the form of "conjugated words" |
- There are three specifications of the dictionary used for sentiment analysis.
- ** Unique surname **: Headwords must be unique and unique .
- ** Original word form **: Since Japanese sentences target the original form (termination form) of the word obtained by morphological analysis, the word form of the headword is the original form (termination form). Must be unified to .
- ** Positive/negative composition ratio **: If there is a significant bias in the positive/negative ratio in the dictionary, that tendency may be reflected in the analysis results, so the number of recorded vocabularies Positive/Negative ratios are balanced .
- Sentiment analysis should be judged after understanding what the sentence says and how it means, that is, the meaning and context. Therefore, the following two processes are required to capture the meaning in the context while complementing the dictionary that defines positive and negative.
- ** Invert polarity **: Invert polarity with infinitives and conjunctions.
- ** Amplification of polarity value **: Amplification of polarity value by "adverb" indicating the degree of positive negative, "exclamation mark" indicating the strength of positive negative, and the number of them. >.
- Note that ** emoticons ** also represent emotions and their strength. By the way, in VADER's dictionary, for example, smile ":) 2.0" ":> 2.1", laughter ": -D 2.3" "XD 2.7", frowning ": (-1.9" ": [-2.0", anger ":" More than 250 words such as @ -2.5 "">: (-2.7", surprise ">: O -1.2" ": O -0.4", crying ":'(-2.2", joyful crying ":') 2.3" The emoticons of are recorded.
Recommended Posts