- Qiita Advent Calendar 2020 This is a summary of the data creation procedure used in "A Year of Corona Looking Back at TF-IDF" on the 22nd day of "Natural Language Processing".
- There are three steps: (1) scraping, (2) cleansing, and (3) morphological analysis.
** ⑴ Data acquisition by scraping **
** 1. Collect URLs for each news **
- For the period from January to December 2020 (12/20), we will collect the URLs of news articles related to Corona reported during this period.
- As a resource, the archive of the multilingual information transmission site "nippon.com" "[New Coronavirus](https://www.nippon.com/ja/tag /% E6% 96% B0% E5% 9E% 8B% E3% 82% B3% E3" % 83% AD% E3% 83% 8A% E3% 82% A6% E3% 82% A4% E3% 83% AB% E3% 82% B9 /? Pnum = 1) ”. In addition, the period before that (before 3/13) is also extracted from the news archive of nippon.com from the viewpoint of corona-related.
- All URLs are in the format
https://www.nippon.com/ja/ + hoge/hoge012345/, so the following is a list of the following, for example, June. I will show you, but I will only post a part in consideration of copyright.
# covid-19_2020-06
pagepath = ["japan-topics/bg900175/",
"in-depth/d00592/",
"news/p01506/",
"news/p01505/",
"news/p01501/",
#Omission
"news/fnn2020060147804/",
"news/fnn2020060147795/",
"news/fnn2020060147790/"]
** 2. Get HTML data, extract necessary parts **
import requests
from bs4 import BeautifulSoup
requests is Python's HTTP communication library that sends requests to the URL to be scraped and ** retrieves HTML data **.BeautifulSoup is an HTML parser library that analyzes the acquired ** HTML data and extracts only the necessary parts (= parsing processing) **.- ➊
requests to get the whole HTML, ➋ Beautiful Soup to format it, determine the conditions to extract the necessary parts, and ➌ select to extract the necessary parts according to the conditions. ..
docs = []
for i in pagepath:
#➊ Get HTML data
response = requests.get("https://www.nippon.com/ja/" + str(i))
html_doc = response.text
#➋ Perspective processing
soup = BeautifulSoup(html_doc, 'html.parser')
# ➌ <div class="editArea">Directly below<p>Extract the tag part
target = soup.select('.editArea > p')
# <p>Extract only text for each sentence enclosed in tags
value = []
for t in target:
val = t.get_text()
value.append(val)
#Delete empty data in the list
value_ = filter(lambda str:str != '', value)
value_ = list(value_)
#"Full-width blank"\delete "u3000"
doc = []
for v in value_:
val = v.replace('\u3000', '')
doc.append(val)
docs.append(doc)
- The extracted required parts
docs are:

- For reference, let's take a look at the above process step by step.
First, the stage where HTML data is acquired by ➊ requests, converted to text and stored.
 ➋ Next, a BeautifulSoup object is created, and the character string is formatted and output by
➋ Next, a BeautifulSoup object is created, and the character string is formatted and output by print (soup.prettify ()). Determine the conditions for getting the required part from here.
 ➌ Next, the extraction condition is passed to
➌ Next, the extraction condition is passed to select and only the necessary part is extracted, and the result of extracting only the body text from this is docs.

** ⑵ Text cleansing **
- Define
cleansing as a function to remove characters and phrases that are noisy in analysis from the text.
** 1. Define cleansing function **
- Use the module neologdn that standardizes Japanese sentences together with the Python regular expression module
re.
!pip install neologdn===0.3.2
- Specify the conditional expression for deletion or replacement. For example, in addition to standard punctuation marks and parentheses, morphological analysis is performed for half a year from January to June on a trial basis, and is added as appropriate.
import re
import neologdn
def cleansing(text):
text = ','.join(text) #Flatten with comma delimiters
text = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+', "", text) #URL deletion
text = neologdn.normalize(text) #Alphabet / Number: Half-width, Katakana: Full-width
text = re.sub(r'[0-9]{4}Year', '', text) ##日付を削除(yyyyYear)
text = re.sub(r'[0-9]{2}Year', '', text) ##日付を削除(yyYear)
text = re.sub(r'\d+Moon', '', text) #日付を削除(何Moon)
text = re.sub(r'\d+Day', '', text) #Day付を削除(何Day)
text = re.sub(r'\d+Time', '', text) #Time間を削除(何Time)
text = re.sub(r'\d+Minutes', '', text) #時間を削除(何Minutes)
text = re.sub(r'\d+Substitute', '', text) #年Substituteを削除
text = re.sub(r'\d+Man', '', text) #Man数を削除(何Man)
text = re.sub(r'\d+Ten thousand people', '', text) #人数を削除(何Ten thousand people)
text = re.sub(r'\d+\.\d+\%', '', text) #Delete percentage (decimal)
text = re.sub(r'\d+\%', '', text) #Delete percentage (integer)
text = re.sub(r'\d+\.\d+%', '', text) #Delete percentage (decimal)
text = re.sub(r'\d+%', '', text) #Delete percentage (integer)
text = re.sub(r'\d+Months', '', text) #月数を削除(何Months)
text = re.sub(r'\【.*\】', '', text) #[] And its contents deleted
text = re.sub(r'\[.*\]', '', text) #[]And its contents deleted
text = re.sub(r'、|。', '', text) #Remove punctuation
text = re.sub(r'「|」|『|』|\(|\)|\(|\)', '', text) #Remove parentheses
text = re.sub(r':|:|=|=|/|/|~|~|・', '', text) #Remove sign
#News source
text = text.replace("Afro", "")
text = text.replace("Jiji Press", "")
text = text.replace("Current events", "")
text = text.replace("TV nishinippon", "")
text = text.replace("Kansai TV", "")
text = text.replace("Fuji Television Network, Inc", "")
text = text.replace("FNN Prime Online", "")
text = text.replace("Nippon Dotcom Editorial Department", "")
text = text.replace("unerry", "")
text = text.replace("THE PAGE", "")
text = text.replace("THE PAGE Youtube channel", "")
text = text.replace("Live News it!", "")
text = text.replace("AFP", "")
text = text.replace("KDDI", "")
text = text.replace("Pakutaso", "")
text = text.replace("PIXTA", "")
#Idioms / idiomatic phrases
text = text.replace("Banner photo", "")
text = text.replace("Photo courtesy", "")
text = text.replace("Document photo", "")
text = text.replace("Below photo", "")
text = text.replace("Banner image", "")
text = text.replace("Image courtesy", "")
text = text.replace("Photographed by the author", "")
text = text.replace("Provided by the author", "")
text = text.replace("Click here for original articles and videos", "")
text = text.replace("Click here for the original article", "")
text = text.replace("Published", "")
text = text.replace("photograph", "")
text = text.replace("source", "")
text = text.replace("Video", "")
text = text.replace("Offer", "")
text = text.replace("Newsroom", "")
#Unnecessary spaces and line breaks
text = text.rstrip() #Line breaks / spaces removed
text = text.replace("\xa0", "")
text = text.upper() #Alphabet: uppercase
text = re.sub(r'\d+', '', text) ##Remove arabic numerals
return text
** 2. Execution of cleansing process **
docs_ = []
for i in docs:
text = cleansing(i)
docs_.append(text)

** ⑶ Consideration and designation of stop words **
- Before designating the stop word, I checked what kind of idioms and phrases in the alphabet are listed just in case.
** 1. Get the alphabet phrase **
- The argument of
re.findall () is (word pattern to be searched, character string to be searched, re.ASCII), and the third argument re.ASCII is" ASCII character (half-width English). Only matches numbers, symbols, control characters, etc.) "is specified.
alphabets = []
for i in docs_:
alphabet = re.findall(r'\w+', i, re.ASCII)
if alphabet:
alphabets.append(alphabet)
print(alphabets)

** 2. Get the top 10 words of appearance frequency **
- itertools is a module that collects iterator generation functions that execute time-consuming loop processing of
for statements more efficiently.
- The
chain.from_iterable flattens all the elements contained in the multidimensional list and puts them together in one list.
- Get the number of occurrences for each word in the Python standard library
collections, and get the top 10 occurrences in collections.Counter.
import itertools
import collections
from collections import Counter
import pandas as pd
#Flattening a multidimensional array
alphabets_list = list(itertools.chain.from_iterable(alphabets))
#Get the number of appearances
cnt = Counter(alphabets_list)
#Get the top 10 words
cnt_sorted = cnt.most_common(10)
#Data frame
pd.DataFrame(cnt_sorted, columns=["English words", "Number of appearances"])
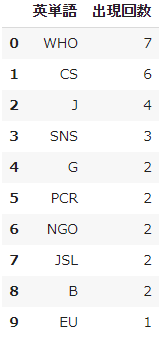
- We checked whether words that are not included in the news text, such as the credit of the news provider, are frequently mentioned.
** 3. Designation of stop word **
- Words that do not have a specific meaning by themselves are excluded as stop words.
stopwords = ["one", "two", "three", "four", "Five", "Six", "Seven", "Eight", "Nine", "〇", #Chinese numeral
"which one", "Which", "Which", "Where", "who is it", "Who", "what", "When", #Infinitive
"this", "It", "that", "Here", "there", "there", #Demonstrative
"here", "Over there", "Over there", "here", "There", "あThere",
"I", "I", "me", "you", "You", "he", "he女", #Personal pronoun
"Pieces", "Case", "Times", "Every time", "door", "surface", "Basic", "Floor", "Eaves", "Building", #Classifier
"Stand", "Sheet", "Discount", "Anniversary", "Man", "Circle", "Year", "Time", "Person", "Ten thousand",
"number", "Stool", "Eye", "Billion", "age", "Total", "point", "Period", "Day",
"of", "もof", "thing", "Yo", "Sama", "Sa", "For", "Per", #Modified noun
"Should be", "Other", "reason", "Yellowtail", "By the way", "home", "Inside", "Hmm",
"Next", "Field", "limit", "Edge", "One", "for",
"Up", "During ~", "under", "Before", "rear", "left", "right", "以Up", "以under", #Suffix
"Other than", "Within", "Or later", "Before", "To", "while", "Feeling", "Key", "Target",
"Faction", "Schizophrenia", "Around", "city", "Mr", "Big", "Decrease", "ratio", "rate",
"Around", "Tend to", "so", "Etc.", "Ra", "Mr.",
"©", "◎", "○", "●", "▼", "*"] #symbol
** ⑷ Data creation by morphological analysis **
- Using the morphological analysis engine MeCab and the dictionary mecab-ipadic-NEologd, morphological analysis is performed for each sentence, and a list of only nouns excluding stop words is created.
** 1. Install MeCab and mecab-ipadic-NEologd **
# MeCab
!apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null
!pip install mecab-python3 > /dev/null
# mecab-ipadic-NEologd
!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null
!echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1
#Error avoidance by symbolic links
!ln -s /etc/mecabrc /usr/local/etc/mecabrc
- Check the dictionary path.
!echo `mecab-config --dicdir`"/mecab-ipadic-neologd"
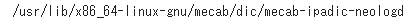
import MeCab
path = "-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd"
m_neo = MeCab.Tagger(path)
- You have created an instance with
path or mecab-ipadic-NEologd as the output mode.
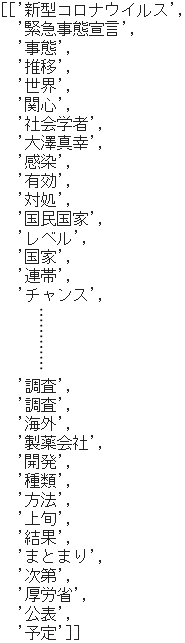
** 2. Extract nouns by morphological analysis **
- From the one-month data
docs divided into article units, process each article and store the result in noun.
noun = []
for d in docs_:
result = []
v1 = m_neo.parse(d) #Results of morphological analysis
v2 = v1.splitlines() #List divided into word units
for v in v2:
v3 = v.split("\t") #Divide the analysis result for one word into "original word" and "content part of analysis" with a blank
if len(v3) == 2: #EOS"Or" "except for
v4 = v3[1].split(',') #Content part of analysis
if (v4[0] == "noun") and (v4[6] not in stopwords):
#print(v4[6])
result.append(v4[6])
noun.append(result)
print(noun)
** 3. Format data for TF-IDF **
- Use
sum to convert a two-dimensional list to a one-dimensional list, and join to convert from comma-separated to half-width space-separated.
doc_06 = sum(noun, [])
text_06 = ' '.join(doc_06)
print(text_06)

- With the above, one month's worth of noun data for each article has been collected into one monthly document.
** 4. Download to local PC **
- Now write
text_06 to a file called'nipponcom_covd19_2020-06.txt'. The argument 'w' is the write mode specification.
with open('nipponcom_covid19_2020-06.txt', 'w') as f:
f.write(text_06)
files is a module for uploading or downloading files between Colaboratory and your local PC.
from google.colab import files
files.download('nipponcom_covid19_2020-06.txt')
- The above process was performed for 12 months, and the one that was imported to the local PC was used for the TF-IDF analysis of the article.