[DOCKER] Parallel learning of deep learning by Keras and Kubernetes
Parallel learning of deep learning by Keras and Kubernetes
I wrote earlier that Keras supports CNTK.
Run Keras with CNTK backend from CentOS
Keras can now use different frameworks in the same program with Theano, TensorFlow and CNTK as backends. I think the advantage of increasing the Keras backend is that you can change the framework and learn by simply changing the environment variables. If you change the framework, the neural network model itself will (probably) not change if the program is the same, but the accuracy and speed will change slightly. Alternatively, you can ensemble and infer the models learned in each framework. I came up with an ensemble of multiple frameworks, so I actually tried it.
The program and Kubernetes yml can be found below. https://github.com/shibuiwilliam/keras_multibackend
Learn multiple Keras backends in parallel
It's boring to try multiple deep learning frameworks sequentially from Keras with the same program, so I tried to train each framework in parallel using Kubernetes. The image is as follows.
It's boring just to learn sequentially.

Let's learn in parallel.
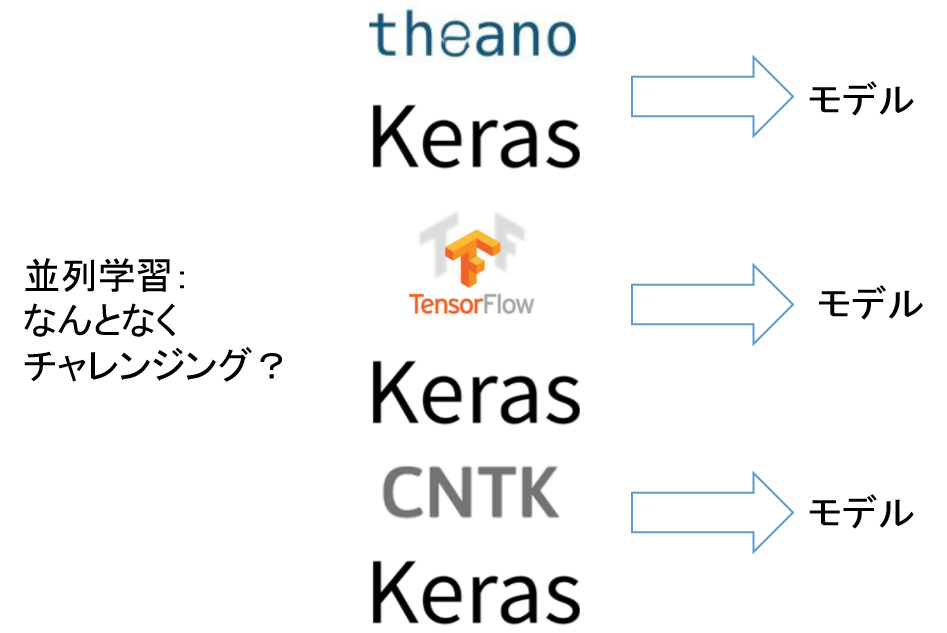
Overall picture
Let Kubernetes learn deep learning in parallel on a Docker container. The overall picture is as follows.

Both platform and program configurations are required.
platform
Prepare 3 virtual machines. This time it is CentOS 7.3. Make VM1 an NFS server and mount the shared directories on VM2 and VM3. Place the Keras learning and inference programs in the shared directory. VM1,2,3 will all be able to access Keras learning and inference programs.
Form a Kubernetes cluster with VM1,2,3. Build VM1,2,3 with Keras, Theano, TensorFlow, CNTK, and other installed Docker images.
The Dockerfile used this time is below.
https://github.com/shibuiwilliam/keras_multibackend
Kubernetes performs Cifar 10 CNN learning by each framework as a job. We will prepare 3 types of Job yml. Define the values of each environment variable KERAS_BACKEND as Theano, TensorFlow, and CNTK.
The Job definition yml of Kubernetes is as follows. First of all, it is for learning. Although CNTK is illustrated, Tensorflow and Theano only change the value of Keras_Backend.
apiVersion: batch/v1
kind: Job
metadata:
name: kerascntk
spec:
template:
spec:
restartPolicy: Never
volumes:
- name: nfstest
nfs:
server: 10.249.20.65
path: "/tmp/nfstest/"
containers:
- name: kerascntk
image: jupyter:1.52
volumeMounts:
- name: nfstest
mountPath: "/tmp/nfstest/"
env:
- name: KERAS_BACKEND
value: "cntk"
command: ["python"]
args: ["/tmp/nfstest/cifar_train.py"]
For inference. Inference is summed with 3 backend inferences in Python, so you only need one below.
apiVersion: batch/v1
kind: Job
metadata:
name: pred
spec:
template:
spec:
restartPolicy: Never
volumes:
- name: nfstest
nfs:
server: 10.249.20.65
path: "/tmp/nfstest/"
containers:
- name: pred
image: jupyter:1.52
volumeMounts:
- name: nfstest
mountPath: "/tmp/nfstest/"
command: ["python"]
args: ["/tmp/nfstest/cifar_pred.py"]
program
Prepare a Keras learning program and an inference program. It is not necessary to create each framework separately. Since the environment variable KERAS_BACKEND is defined and divided in the Kubernetes Job yml, there is one program for learning and one for inference.
Each program is as follows. First of all, it is for learning. I haven't made any special efforts. It's an ordinary VGG-like CNN. The number of epochs is 50, but since Early Stopping is also set, it is supposed to end in about 20 epochs. Also, 100 images of test data are excluded from Evaluation for use in inference.
#For learning
# see its environment variable
import os
kerasBKED = os.environ["KERAS_BACKEND"]
print(kerasBKED)
# imports
import keras
from keras.models import load_model
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.callbacks import EarlyStopping, ModelCheckpoint
import pickle
import numpy as np
# variables
batch_size = 32
num_classes = 10
epochs = 50
# loading and reshaping cifar10 data
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
# leave out 100 images for prediction
x_test1 = x_test[100:,:]
x_test2 = x_test[:100,:]
y_test1 = y_test[100:,:]
y_test2 = y_test[:100,:]
print(x_test1.shape, x_test2.shape, y_test1.shape, y_test2.shape)
# only test1 data is used for validation
# VGG-like neural network model
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
opt = keras.optimizers.adam()
model.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
# Add checkpoint and earlystopping
chkpt = '/tmp/nfstest/cifar_weights/' + kerasBKED + '_weights.{epoch:02d}-{loss:.2f}-{val_loss:.2f}.hdf5'
cp_cb = ModelCheckpoint(filepath = chkpt, monitor='val_loss', verbose=1, save_best_only=True, mode='auto')
es_cb = EarlyStopping(monitor='val_loss', patience=1, verbose=1, mode='auto')
# fit the model
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test1, y_test1),
callbacks=[cp_cb, es_cb],
shuffle=True)
# score and save the model
score = model.evaluate(x_test1, y_test1, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
saveDir = "/tmp/nfstest/cifar_model/"
if not os.path.isdir(saveDir):
os.makedirs(saveDir)
modelName = "{0}_{1}_model.hdf5".format(kerasBKED, score[1])
model_path = os.path.join(saveDir, modelName)
model.save(model_path)
At the end of training, save the model to an NFS directory. As a result, three types of models are stored in the NFS directory. Inference uses these three models. For inference, use 100 images extracted from the test data. Infer by calling the three types of model files (Theano, Tensorflow, CNTK) created by learning. Since there is a difference in the accuracy of learning in each model, the inference is multiplied by the accuracy and finally divided by the sum of the accuracy. It looks like an ensemble model, but it doesn't have any theoretical backing.
#For reasoning
# import
import keras
from keras.models import load_model
from keras.datasets import cifar10
import os
# variables
batch_size = 32
num_classes = 10
# load and reshape data
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
x_test1 = x_test[100:,:]
x_test2 = x_test[:100,:]
y_test1 = y_test[100:,:]
y_test2 = y_test[:100,:]
# test2 data is used for prediction
# get a list of model files
backList = ["cntk", "tensorflow", "theano"]
saveDir = "/tmp/nfstest/cifar_model/"
files = os.listdir(saveDir)
filesList = [f for f in files if os.path.isfile(os.path.join(saveDir, f))]
filesList
# predict using each model
prediction = 0
sumAcc = 0
for bk in backList:
os.environ["KERAS_BACKEND"] = bk
kerasBKED = os.environ["KERAS_BACKEND"]
modelName = [m for m in filesList if bk in m][0]
modelAcc = float(modelName.split("_")[1])
print("MODELNAME {0} \t for BACKEND {1} \t with ACCURACY {2}".format(modelName, kerasBKED, modelAcc))
model = load_model(os.path.join(saveDir, modelName))
prediction += model.predict(x_test2, batch_size=batch_size, verbose=0) * modelAcc
sumAcc += modelAcc
prediction = prediction / sumAcc
print(prediction)
# output predictions to csv
import csv
with open("/tmp/nfstest/cifar_model/preds.csv", 'w') as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerows(prediction)
predlist = []
for i in prediction:
pred = max(enumerate(i), key=lambda x: x[1])[0]
predlist.append([pred, i[pred]])
print(predlist)
# output overall summary to csv
import csv
with open("/tmp/nfstest/cifar_model/pred.csv", 'w') as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerow(predlist)
The result of trying
In learning, all three frameworks settled on almost the same Accuracy.
| Backend | Accuracy | Loss |
|---|---|---|
| Theano | 0.785 | 0.62 |
| TensorFlow | 0.772 | 0.63 |
| CNTK | 0.771 | 0.67 |
It is natural because we are learning with the same neural network.
However, when it comes to inference, there is a slight difference in the back end. Below is a list of 10 test data inferred by each backend. (In the above program, we infer from 100 image data, but since it is too much, we will limit it to 10.) For the first image data, CNTK infers 4 to be 49.498%, while Tensorflow and Theano infer 3 to 55.225% and 67.820%, respectively. Multiplying each backend's inference and Accuracy and dividing it by the Accuracy's total results in inferring 3 to 57.855%. The correct answer for each image data is listed as answer to the left of ensemble.
\frac{0.49498 * 0.771 + 0.55225 * 0.772 + 0.67820 * 0.785}{0.771 + 0.772 + 0.785} \\
= 0.57855
The second image data is 8 for CNTK, Tensorflow, and Theano. However, in the third data, CNTK is 0 at 41.421%, Tensorflow is 8 at 72.917%, and Theano is 1 at 52.288%.
| data | backends | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | cntk | 0.039% | 0.053% | 2.518% | 11.623% | 49.498% | 6.068% | 4.404% | 2.736% | 0.075% | 0.108% |
| tensorflow | 0.049% | 0.002% | 0.289% | 55.225% | 0.055% | 20.520% | 0.399% | 0.143% | 0.495% | 0.015% | |
| theano | 0.002% | 0.005% | 0.028% | 67.820% | 0.068% | 3.543% | 6.598% | 0.017% | 0.027% | 0.347% | |
| answer:3 | ensemble | 0.039% | 0.026% | 1.218% | 57.855% | 21.318% | 12.945% | 4.898% | 1.244% | 0.257% | 0.202% |
| 2 | cntk | 19.015% | 6.447% | 0.027% | 0.125% | 0.007% | 0.001% | 0.001% | 0.004% | 51.443% | 0.052% |
| tensorflow | 0.000% | 0.019% | 0.000% | 0.000% | 0.000% | 0.000% | 0.000% | 0.000% | 77.173% | 0.000% | |
| theano | 0.045% | 2.147% | 0.000% | 0.000% | 0.000% | 0.000% | 0.000% | 0.000% | 76.233% | 0.030% | |
| answer:8 | ensemble | 8.188% | 3.700% | 0.012% | 0.053% | 0.003% | 0.000% | 0.000% | 0.002% | 88.006% | 0.035% |
| 3 | cntk | 41.421% | 2.234% | 0.902% | 0.223% | 1.573% | 0.006% | 0.062% | 0.070% | 21.528% | 9.104% |
| tensorflow | 1.056% | 3.040% | 0.000% | 0.028% | 0.000% | 0.000% | 0.002% | 0.000% | 72.917% | 0.147% | |
| theano | 0.356% | 52.288% | 0.012% | 0.305% | 0.005% | 0.000% | 0.001% | 0.001% | 23.977% | 1.508% | |
| answer:8 | ensemble | 18.402% | 24.729% | 0.393% | 0.239% | 0.678% | 0.003% | 0.028% | 0.031% | 50.876% | 4.622% |
| 4 | cntk | 44.158% | 6.019% | 1.613% | 4.033% | 1.339% | 0.091% | 0.133% | 0.150% | 11.250% | 8.334% |
| tensorflow | 68.420% | 0.740% | 0.175% | 0.296% | 0.010% | 0.004% | 0.029% | 0.006% | 6.932% | 0.580% | |
| theano | 37.302% | 2.057% | 0.594% | 2.029% | 0.348% | 0.086% | 0.043% | 0.029% | 33.511% | 2.455% | |
| answer:0 | ensemble | 64.391% | 3.788% | 1.023% | 2.731% | 0.729% | 0.078% | 0.088% | 0.079% | 22.208% | 4.884% |
| 5 | cntk | 0.005% | 0.001% | 27.413% | 1.284% | 8.657% | 0.023% | 39.720% | 0.001% | 0.017% | 0.001% |
| tensorflow | 0.000% | 0.000% | 0.020% | 0.884% | 71.491% | 0.001% | 4.796% | 0.000% | 0.000% | 0.000% | |
| theano | 0.000% | 0.000% | 2.550% | 0.190% | 1.722% | 0.000% | 73.993% | 0.000% | 0.000% | 0.000% | |
| answer:6 | ensemble | 0.002% | 0.000% | 12.881% | 1.013% | 35.172% | 0.011% | 50.913% | 0.000% | 0.007% | 0.000% |
| 6 | cntk | 0.001% | 0.000% | 3.774% | 23.424% | 8.258% | 0.708% | 40.913% | 0.036% | 0.001% | 0.005% |
| tensorflow | 0.002% | 0.000% | 0.401% | 41.210% | 1.115% | 4.864% | 29.589% | 0.006% | 0.004% | 0.001% | |
| theano | 0.000% | 0.000% | 0.009% | 0.263% | 0.005% | 0.072% | 78.107% | 0.000% | 0.000% | 0.000% | |
| answer:6 | ensemble | 0.001% | 0.000% | 1.797% | 27.881% | 4.029% | 2.425% | 63.844% | 0.018% | 0.002% | 0.003% |
| 7 | cntk | 3.350% | 0.113% | 14.258% | 12.193% | 0.190% | 4.802% | 0.295% | 41.802% | 0.021% | 0.097% |
| tensorflow | 0.048% | 41.460% | 0.462% | 9.073% | 0.000% | 0.737% | 0.079% | 0.602% | 0.044% | 24.686% | |
| theano | 0.008% | 49.193% | 0.053% | 2.381% | 0.001% | 0.065% | 0.183% | 0.015% | 0.024% | 26.531% | |
| answer:1 | ensemble | 1.463% | 38.994% | 6.347% | 10.159% | 0.082% | 2.408% | 0.240% | 18.224% | 0.038% | 22.045% |
| 8 | cntk | 0.014% | 0.001% | 14.742% | 5.123% | 42.021% | 0.048% | 15.141% | 0.020% | 0.008% | 0.004% |
| tensorflow | 0.108% | 0.000% | 9.300% | 6.686% | 31.076% | 0.310% | 29.625% | 0.072% | 0.008% | 0.007% | |
| theano | 0.023% | 0.000% | 33.777% | 0.185% | 1.431% | 0.096% | 42.927% | 0.013% | 0.002% | 0.000% | |
| answer:6 | ensemble | 0.062% | 0.000% | 24.840% | 5.153% | 32.018% | 0.195% | 37.674% | 0.046% | 0.007% | 0.005% |
| 9 | cntk | 0.005% | 0.000% | 4.104% | 43.597% | 17.353% | 5.953% | 5.485% | 0.624% | 0.000% | 0.001% |
| tensorflow | 0.000% | 0.000% | 0.067% | 70.856% | 2.242% | 3.932% | 0.091% | 0.004% | 0.000% | 0.000% | |
| theano | 0.000% | 0.000% | 0.001% | 78.418% | 0.011% | 0.021% | 0.002% | 0.003% | 0.000% | 0.000% | |
| answer:3 | ensemble | 0.002% | 0.000% | 1.792% | 82.860% | 8.423% | 4.256% | 2.396% | 0.271% | 0.000% | 0.000% |
| 10 | cntk | 8.810% | 7.715% | 8.225% | 13.706% | 6.575% | 3.413% | 8.631% | 4.522% | 5.751% | 9.773% |
| tensorflow | 0.482% | 68.974% | 0.012% | 0.014% | 0.001% | 0.001% | 0.213% | 0.000% | 4.088% | 3.405% | |
| theano | 0.480% | 48.363% | 0.000% | 0.000% | 0.000% | 0.000% | 0.000% | 0.000% | 3.134% | 26.477% | |
| answer:1 | ensemble | 4.199% | 53.724% | 3.539% | 5.895% | 2.825% | 1.467% | 3.799% | 1.943% | 5.574% | 17.036% |
What is interesting to look at is that even if the individual backends are incorrect, the ensemble will give the correct answer. For example, in image 3, CNTK, Tensorflow, and Theano make separate inferences, but since Tensorflow infers 8 with the highest probability, the ensemble is also 8.
Summary
In the learning phase, both backends are just as accurate. However, if you try to infer, each may give different results. Further ensemble seems to give the correct answer with higher accuracy than inferring with one backend.
I succeeded in parallel learning with Kubernetes. It's very convenient because Kubernetes Job will execute the specified program in the cluster. Kubernetes also has a Cron Job, and it seems that Job can be executed in a timed manner. When planning a deep learning study, I find it useful to automate it with Kubernetes' Cron Job. So, next time, I will verify the automatic execution of deep learning learning by Kubernetes Cron Job.
Recommended Posts