Qu'est-ce que le réseau neuronal convolutif?
Dans le monde de l'apprentissage automatique, le réseau de neurones convolutifs (CNN) est bien entendu reconnu en matière d'images et de Kagawa en matière d'udon. Cependant, il y a étonnamment peu d'explications sur ce qu'est le CNN.
Par conséquent, dans cet article, je voudrais expliquer le mécanisme et les mérites de CNN.
Comme décrit dans les références, le contenu de l'explication est basé sur le cours CNN de Stanford. Ce cours expliquera du réseau neuronal à CNN à la mise en œuvre par Tensorflow, donc si vous êtes intéressé, veuillez vous y référer également.
Qu'est-ce que le réseau neuronal convolutif?
Comme son nom l'indique, CNN est un réseau neuronal normal avec l'ajout de la convolution. Ici, je vais vous expliquer ce que sont la convolution et la convolution, et pourquoi elles sont efficaces pour la reconnaissance d'image.
En tant que tâche simple, considérez la tâche de déterminer si le chiffre écrit est ○ ou ×. Voici un exemple d'utilisation d'un réseau neuronal normal.

Pensez à un pixel de l'image comme une entrée. Pour une image 10x10, l'entrée sera un vecteur de taille 100 (notez que pour la représentation RVB, ce sera x3 ici).
Sur la figure, la partie noire du bord du cercle est affichée comme entrée, mais si vous regardez cela, vous pouvez voir que si la position est légèrement décalée, le jugement sera grandement affecté. En effet, si la position ou la forme change légèrement comme indiqué dans la figure ci-dessous, les informations d'entrée seront également mal alignées et reconnues.
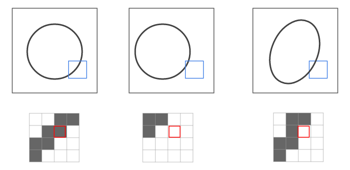
Cependant, l'intérieur du carré bleu de la figure a tendance à être "noir du coin supérieur droit vers le coin inférieur gauche". En d'autres termes, si vous pouvez saisir une certaine quantité de zone à la fois au lieu de 1 pixel, il semble que vous puissiez faire un jugement plus précis.
CNN est la réalisation de cette idée.
Comme le montre la figure ci-dessous, une petite zone appelée filtre (zone 4x4 avec un cadre rouge dans la figure ci-dessous) est prise sur l'image, et elle est compressée (= pliée) comme une quantité de caractéristiques.

Ce processus est répété en faisant glisser la zone. Le résultat est une couche de convolution, une couche créée par convolution des informations dans le filtre.

Si le diagramme de réseau neuronal ci-dessus est converti en CNN, l'image sera la suivante.

Le processus de «pliage» à l'aide de ce filtre est précisément la multiplication et le produit interne entre le «vecteur de l'image dans le filtre» et le «vecteur utilisé pour le pliage». Dans ce qui suit, un filtre 5x5x3 est appliqué à une image 32x32x3 (image RVB 32x32).
 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p13
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p13
Cela créera finalement un calque 28x28x1 (si la largeur de la diapositive est 1).
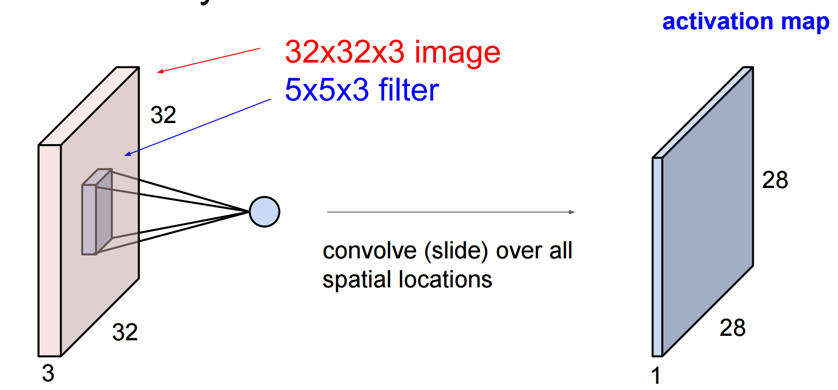 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p14
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p14
Et si vous augmentez les types de filtres, la couche de convolution augmentera en conséquence. Ci-dessous, 6 couches sont créées avec 6 filtres.
 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p16
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p16
On peut dire qu'il s'agit simplement de créer une "nouvelle image" en pliant. Comme un réseau neuronal normal, la couche convolutive créée de cette manière est connectée par une fonction d'activation pour former un réseau neuronal convolutif (ReLU est souvent utilisé comme fonction d'activation).
Je vais résumer l'histoire jusqu'à présent.
- CNN est un réseau neuronal qui introduit une couche de convolution créée par convolution des informations sur la zone à l'intérieur du filtre.
- La couche de convolution est créée en appliquant tout en déplaçant le filtre, et autant que le nombre de filtres sont créés. Un réseau est construit en les empilant et en les connectant avec une fonction d'activation (ReLU, etc.).
- Le pliage permet d'extraire des caractéristiques en fonction de zones plutôt que de points, ce qui le rend robuste au mouvement et à la déformation de l'image. De plus, il est possible d'extraire des caractéristiques telles que des arêtes qui ne peuvent être comprises qu'en fonction de la zone.
Ce CNN est caractérisé par des paramètres de filtre et des couches.
Paramètres de filtre
Les quatre paramètres suivants doivent être définis pour le filtre utilisé pour la convolution.
- Nombre de filtres (K): Le nombre de filtres à utiliser. Environ une puissance de 2 est prise (32, 64, 128 ...)
- Taille du filtre (F): la taille du filtre utilisé
- Largeur de mouvement du filtre (S): Largeur pour déplacer le filtre
- Padding (P): combien remplir la zone de bord de l'image
Le remplissage est le processus de remplissage de la zone de bord de l'image avec 0, comme indiqué ci-dessous.
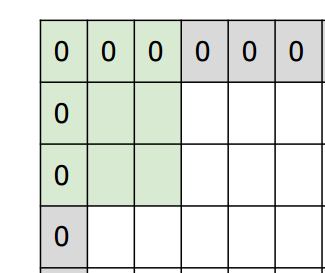 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p35
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p35
La raison en est que le pliage normal réduit le nombre de fois que la zone de bord est pliée par rapport aux autres zones. En remplissant les bords de l'image avec 0 de cette manière et en filtrant à partir de là, les bords seront réfléchis de la même manière que les autres zones.
De plus, il est nécessaire d'ajuster la taille et la largeur de mouvement du filtre afin qu'il s'adapte correctement à la taille de l'image. Veuillez noter que vous ne pouvez pas définir la taille et la largeur de mouvement du filtre qui s'étend au-delà de l'image comme indiqué ci-dessous.

A partir des valeurs de ces paramètres, il est possible de calculer la taille de la couche convolutionnelle. Supposons que vous souhaitiez appliquer un filtre 5x5x3 à une image 32x32x3 avec une largeur de mouvement de 1 et un remplissage de 2. Tout d'abord, lorsque le remplissage est ajouté, la taille de l'image est 32 + 2 * 2 = 36. Si vous prenez un filtre d'une largeur de 5 à partir d'ici avec une largeur de mouvement de 1, ce sera 32 avec 36-5 + 1. Vous vous retrouvez donc avec une couche 32x32x3.
Ces paramètres doivent également être définis lors de l'utilisation d'une bibliothèque telle que Caffe, c'est donc une bonne idée de garder à l'esprit leur signification et comment calculer la taille.
Structure des couches
Il existe trois types de couches dans CNN, y compris la couche convolutionnelle.
- Couche convolutionnelle: une couche qui convolve les fonctionnalités
- Couche de mise en commun: une couche pour réduire la couche et la rendre plus facile à manipuler
- Couche entièrement connectée: la couche qui rend le jugement final à partir de la quantité d'entités
L'image est la suivante.
 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p22
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p22
Je vais expliquer les couches autres que la couche convolutionnelle. Le premier est le calque de regroupement, qui est le calque qui compresse l'image. Il a l'avantage de compresser la taille de l'image et de faciliter sa manipulation dans les couches ultérieures.
 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p54
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p54
Il existe Max Pooling comme moyen de faire cette mise en commun. Il s'agit d'une méthode de compression en prenant la valeur maximale dans chaque zone.
 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p55
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p55
Une couche entièrement connectée est une couche qui relie tous les éléments de la couche précédente. Il est principalement utilisé dans la couche qui rend le jugement final. En combinant ces couches, nous allons construire un CNN.
Évolution de CNN
La précision de CNN s'est améliorée au fil des ans, mais les caractéristiques suivantes peuvent être vues dans les configurations récentes.
- Réduisez la taille du filtre et approfondissez la hiérarchie
- Éliminez le pooling et les couches FC
Dans la figure ci-dessous, vous pouvez voir que les couches deviennent plus profondes à mesure que la précision augmente d'année en année.
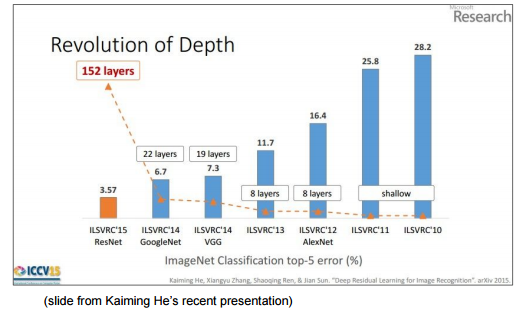 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p78
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p78
En ce qui concerne la profondeur de la couche, ce qui suit peut être plus facile à comprendre. Par rapport aux 8 couches d'AlexNet apparues en 2012, ResNet, qui a remporté la couronne en 2015, a augmenté de manière significative à 152 couches.
 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p80
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p80
Il semble qu'il existe plusieurs des modèles suivants comme configuration de base de CNN.
(Convolution * N + (Pooling)) * M + Fully Connected * K
** N ** est d'environ ~ 5, et ** M ** couches sont superposées (M est une valeur assez grande), et finalement FC pour le jugement est ** K ** couche (0 <= K <=). 2) C'est comme la mise en place (j'ajoute parfois un calque en utilisant la fonction SoftMax pour gérer le problème de classification). ReLU est souvent utilisé comme fonction d'activation.
Bien que CNN semble très compliqué, il peut être entraîné par rétropropagation comme Neural Network car il ne supprime pas les bases du réseau neuronal qui se propage avec le poids. Je pense que la flexibilité ici est également l'attrait de Neural Network.
Exemple d'application CNN
CNN a été appliqué non seulement à l'image d'origine, mais également à d'autres tâches. Cet exemple d'application est très bien organisé dans la diapositive ci-dessous, donc si vous êtes intéressé, jetez un œil.
Tendances des réseaux de neurones convolutifs
En d'autres termes, un CNN capable d'identifier une image peut bien capturer les caractéristiques de l'image. En d'autres termes, le CNN sans la couche discriminante peut être vu comme le processus de transformation de l'image d'entrée en un vecteur qui représente bien ses caractéristiques (de manière distincte). Certains des exemples d'application utilisent cette fonctionnalité, et en particulier l'exemple d'application de l'ajout d'une légende à l'image combine la quantité de fonctionnalités de l'image extraite de CNN et les informations textuelles.
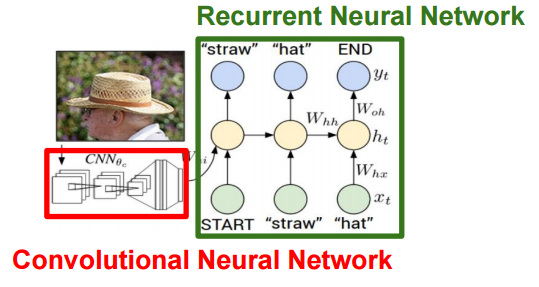
Je pense que divers exemples d'application sortiront à l'avenir, et si vous utilisez le récent framework d'apprentissage automatique, vous pouvez l'essayer vous-même. J'espère que cet article vous aidera.
Les références
- CS231n: Convolutional Neural Networks for Visual Recognition
- Tendances des réseaux de neurones convolutionnels
Recommended Posts