J'ai essayé d'analyser les principaux composants avec les données du Titanic!
Aperçu
En utilisant les données Titanic qui sont souvent utilisées au début de kaggle, J'ai essayé d'analyser les principaux composants. Cependant, cette fois, cela n'a pas été fait à des fins de prédiction. Le but était simplement d'observer les caractéristiques des données à l'aide d'une méthode d'analyse statistique. J'ai donc décidé d'analyser ensemble les principaux composants des données train / test.
supposition
―― Qu'est-ce que l'analyse en composantes principales?
Pour les données représentées par plusieurs axes (variables)
Une méthode pour trouver un "axe avec une grande variation de données".
En raison de la compression des dimensions lors de la prévision
Lors de l'analyse des données existantes, cela est souvent fait pour la synthèse.
Dans la figure ci-dessous (image)
Il y a l'axe rouge avec la variation la plus élevée, suivi de l'axe bleu avec la variation la plus élevée (perpendiculaire à l'axe rouge).
L'analyse de la composante principale consiste à trouver ces axes rouges et bleus.
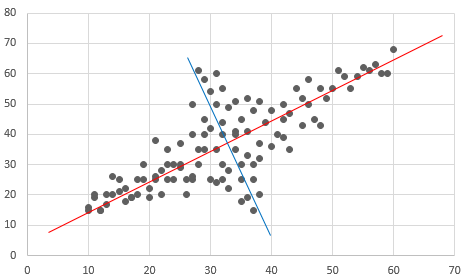
Analysis_Overview
- Données analytiques Données Titanic (train + test). Vous pouvez le télécharger à partir de ce qui suit (kaggle). (Cependant, vous devez vous connecter à kaggle.) https://www.kaggle.com/c/titanic/data
- point de confirmation
- Taux de cotisation -Vecteur unique --Facteur de chargement --Variations à exclure de l'analyse Cette fois, pour une analyse simple, nous exclurons les variables suivantes qui sont difficiles à prétraiter.
- Cabin
- Ticket
- Name
Analyse_Détails
- Importation de la bibliothèque
import os
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import display
from sklearn.decomposition import PCA
- Définition de variable (destination de stockage de données csv titanesques, etc.)
- Premise code qui stocke les données Titanic csv (train.csv, test.csv) dans le dossier "data".
#Dossier en cours
forlder_cur = os.getcwd()
print(" forlder_cur : {}".format(forlder_cur))
print(" isdir:{}".format(os.path.isdir(forlder_cur)))
#emplacement de stockage des données
folder_data = os.path.join(forlder_cur , "data")
print(" folder_data : {}".format(folder_data))
print(" isdir:{}".format(os.path.isdir(folder_data)))
#fichier de données
## train.csv
fpath_train = os.path.join(folder_data , "train.csv")
print(" fpath_train : {}".format(fpath_train))
print(" isdir:{}".format(os.path.isfile(fpath_train)))
## test.csv
fpath_test = os.path.join(folder_data , "test.csv")
print(" fpath_test : {}".format(fpath_test))
print(" isdir:{}".format(os.path.isfile(fpath_test)))
# id
id_col = "PassengerId"
#Variable objective
target_col = "Survived"
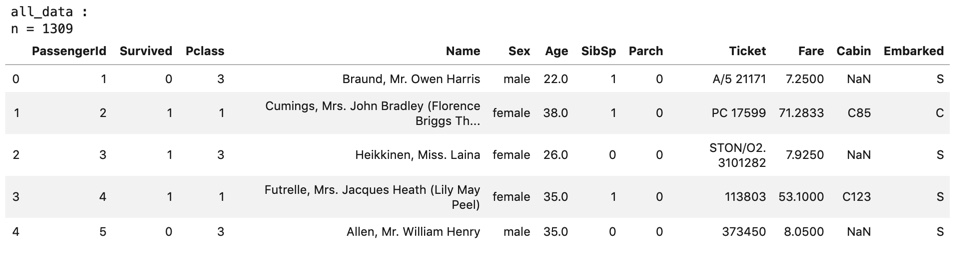
- Importez les données Titanic Les données "all_data" (train + test) créées par le code ci-dessous seront utilisées ultérieurement.
# train.csv
train_data = pd.read_csv(fpath_train)
print("train_data :")
print("n = {}".format(len(train_data)))
display(train_data.head())
# test.csv
test_data = pd.read_csv(fpath_test)
print("test_data :")
print("n = {}".format(len(test_data)))
display(test_data.head())
# train_and_test
col_list = list(train_data.columns)
tmp_test = test_data.assign(Survived=None)
tmp_test = tmp_test[col_list].copy()
print("tmp_test :")
print("n = {}".format(len(tmp_test)))
display(tmp_test.head())
all_data = pd.concat([train_data , tmp_test] , axis=0)
print("all_data :")
print("n = {}".format(len(all_data)))
display(all_data.head())
- Prétraitement La conversion de variable factice, la complétion manquante et la suppression de variable sont effectuées pour chaque variable, et les données créées "proc_all_data" sont utilisées ultérieurement.
#copie
proc_all_data = all_data.copy()
# Sex -------------------------------------------------------------------------
col = "Sex"
def app_sex(x):
if x == "male":
return 1
elif x == 'female':
return 0
#Disparu
else:
return 0.5
proc_all_data[col] = proc_all_data[col].apply(app_sex)
print("columns:{}".format(col) , "-" * 40)
display(all_data[col].value_counts())
display(proc_all_data[col].value_counts())
print("n of missing :" , len(proc_all_data.query("{0} != {0}".format(col))))
# Age -------------------------------------------------------------------------
col = "Age"
medi = proc_all_data[col].median()
proc_all_data[col] = proc_all_data[col].fillna(medi)
print("columns:{}".format(col) , "-" * 40)
display(all_data[col].value_counts())
display(proc_all_data[col].value_counts())
print("n of missing :" , len(proc_all_data.query("{0} != {0}".format(col))))
print("median :" , medi)
# Fare -------------------------------------------------------------------------
col = "Fare"
medi = proc_all_data[col].median()
proc_all_data[col] = proc_all_data[col].fillna(medi)
print("columns:{}".format(col) , "-" * 40)
display(all_data[col].value_counts())
display(proc_all_data[col].value_counts())
print("n of missing :" , len(proc_all_data.query("{0} != {0}".format(col))))
print("median :" , medi)
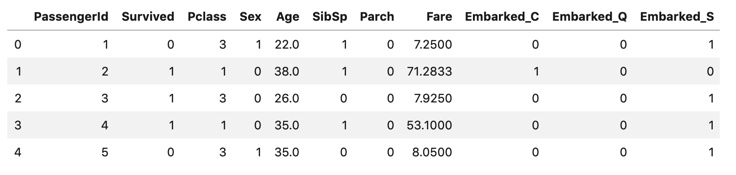
# Embarked -------------------------------------------------------------------------
col = "Embarked"
proc_all_data = pd.get_dummies(proc_all_data , columns=[col])
print("columns:{}".format(col) , "-" * 40)
display(all_data.head())
display(proc_all_data.head())
# Cabin -------------------------------------------------------------------------
col = "Cabin"
proc_all_data = proc_all_data.drop(columns=[col])
print("columns:{}".format(col) , "-" * 40)
display(all_data.head())
display(proc_all_data.head())
# Ticket -------------------------------------------------------------------------
col = "Ticket"
proc_all_data = proc_all_data.drop(columns=[col])
print("columns:{}".format(col) , "-" * 40)
display(all_data.head())
display(proc_all_data.head())
# Name -------------------------------------------------------------------------
col = "Name"
proc_all_data = proc_all_data.drop(columns=[col])
print("columns:{}".format(col) , "-" * 40)
display(all_data.head())
display(proc_all_data.head())
proc_all_data :
- Analyse des principales composantes (calcul du taux de cotisation)
#Variable explicative
feature_cols = list(set(proc_all_data.columns) - set([target_col]) - set([id_col]))
print("feature_cols :" , feature_cols)
print("len of feature_cols :" , len(feature_cols))
features = proc_all_data[feature_cols]
pca = PCA()
pca.fit(features)
print("Nombre de composants principaux: " , pca.n_components_)
print("Taux de cotisation: " , ["{:.2f}".format(ratio) for ratio in pca.explained_variance_ratio_])
Comme le montrent les résultats ci-dessous, la première composante principale est extrêmement variable.
Dans ce qui suit, le vecteur propre de la première composante principale et le chargement factoriel sont confirmés.
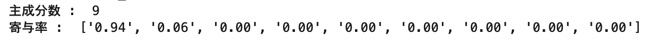
- Vecteur unique du premier composant principal
6-1. Transformation des données
#Vecteur unique(Premier composant principal)
components_df = pd.DataFrame({
"feature":feature_cols
, "component":pca.components_[0]
})
components_df["abs_component"] = components_df["component"].abs()
components_df["rank_component"] = components_df["abs_component"].rank(ascending=False)
#Tri décroissant par valeur absolue de la valeur vectorielle
components_df.sort_values(by="abs_component" , ascending=False , inplace=True)
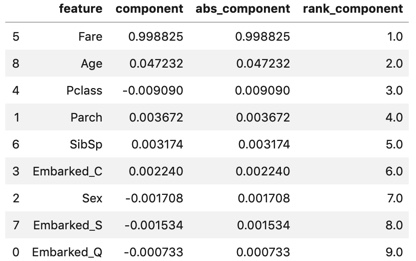
display(components_df)
components_df :
6-2. Représentation graphique
#Création de graphes
max_abs_component = max(components_df["abs_component"])
min_component = min(components_df["component"])
x_ticks_num = list(i for i in range(len(components_df)))
fig = plt.figure(figsize=(15,8))
plt.grid()
plt.title("Components of First Principal Component")
plt.xlabel("feature")
plt.ylabel("component")
plt.xticks(ticks=x_ticks_num , labels=components_df["feature"])
plt.bar(x_ticks_num , components_df["component"] , color="c" , label="components")
plt.plot(x_ticks_num , components_df["abs_component"] , color="r" , marker="o" , label="[abs] components")
plt.legend()
plt.show()
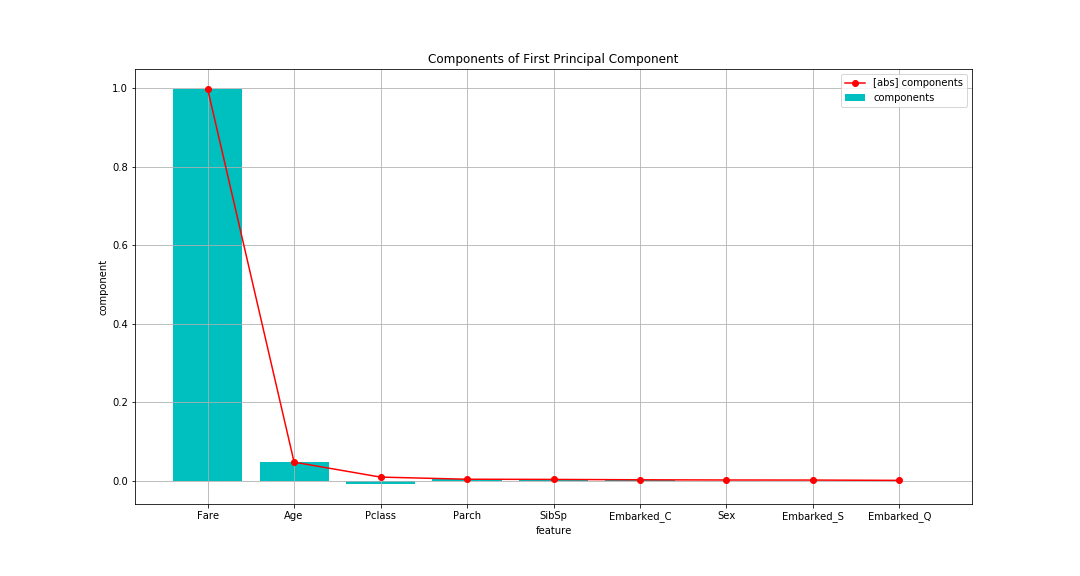
Le tarif (frais d'embarquement) est extrêmement élevé, suivi de l'âge (âge). Il n'y en a que quelques autres.
En ne regardant que les vecteurs propres, il semble que ce soit la principale composante résumée par Fare.
Cependant, comme la valeur du vecteur propre change en fonction de la taille de la dispersion de la variable cible,
Jetons un coup d'œil au chargement factoriel calculé plus tard.
- Facteur de chargement du premier composant principal
7-1. Transformation des données
#Score du composant principal(Premier composant principal)
score = pca.transform(features)[: , 0]
#Facteur de chargement
dict_fact_load = dict()
for col in feature_cols:
data = features[col]
factor_loading = data.corr(pd.Series(score))
dict_fact_load[col] = factor_loading
fact_load_df = pd.DataFrame({
"feature":feature_cols
, "factor_loading":[dict_fact_load[col] for col in feature_cols]
})
fact_load_df["abs_factor_loading"] = fact_load_df["factor_loading"].abs()
fact_load_df["rank_factor_loading"] = fact_load_df["abs_factor_loading"].rank(ascending=False)
#Tri décroissant par valeur absolue de la valeur vectorielle
fact_load_df.sort_values(by="abs_factor_loading" , ascending=False , inplace=True)
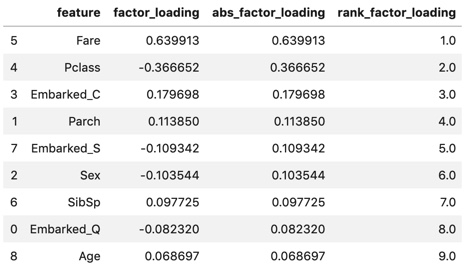
display(fact_load_df)
7-2. Représentation graphique
#Création de graphes
max_abs_factor_loading = max(fact_load_df["abs_factor_loading"])
min_factor_loading = min(fact_load_df["factor_loading"])
x_ticks_num = list(i for i in range(len(fact_load_df)))
plt.figure(figsize=(15,8))
plt.grid()
plt.title("Factor Lodings of First Principal Component")
plt.xlabel("feature")
plt.ylabel("factor loading")
plt.xticks(ticks=x_ticks_num , labels=fact_load_df["feature"])
plt.bar(x_ticks_num , fact_load_df["factor_loading"] , color="c" , label="factor loadings")
plt.plot(x_ticks_num , fact_load_df["abs_factor_loading"] , color="r" , marker="o" , label="[abs] factor loadings")
plt.legend()
plt.show()
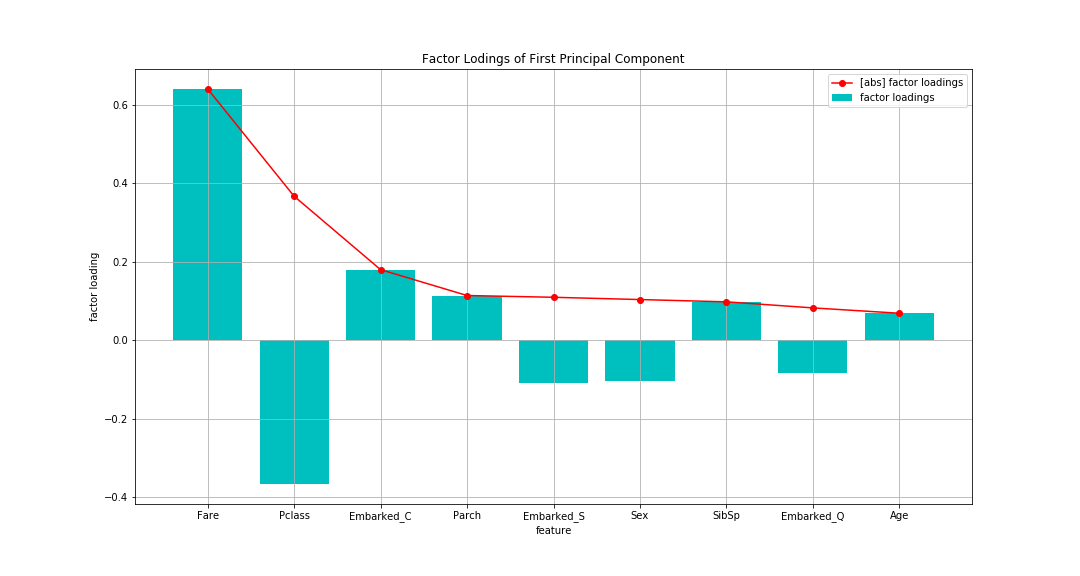
En regardant le chargement factoriel, En valeur absolue (ligne de rupture), Fare (frais d'embarquement) est le plus élevé, suivi de Pclass (classe passager). Avec une différence de Pclass, les autres sont à peu près aussi petits. Le premier composant principal est "Indicateur pour évaluer la richesse" Il semble que vous puissiez y penser.
Par rapport au vecteur propre confirmé ci-dessus En ce qui concerne le tarif, le vecteur propre était très majoritairement le plus grand, mais le chargement factoriel ne faisait pas une telle différence. En ce qui concerne l'âge, c'était le deuxième plus grand dans le vecteur propre, mais le plus bas dans le chargement factoriel. Le tarif et l'âge semblent être très dispersés.
Si vous essayez de juger de la corrélation entre le score de la composante principale et chaque variable du vecteur propre,
J'étais sur le point de faire une erreur.
La charge factorielle doit être calculée et confirmée.
Résumé
À la suite de l'analyse des composants principaux L'indice «Évaluer la richesse» est obtenu, L'indice était celui que la plupart des clients (chaque donnée) pouvaient être divisés (variés).
Nous avons également constaté que les tendances diffèrent entre le vecteur propre et le chargement factoriel. c'est, "(Pour vérifier le contenu du composant principal) Lorsque vous examinez la corrélation entre les composantes principales et chaque variable, regardez le chargement factoriel. Juger uniquement par le vecteur propre (Parce qu'il est affecté par la taille de la dispersion) Peut être trompeur " Il y a une mise en garde.