J'ai créé un modèle de détection d'anomalies qui fonctionne sur iOS
Contexte
Je souhaite créer une application pour l'agriculture x l'apprentissage en profondeur!
Sur la base de ce motif, je pense que nous pouvons créer une application qui diagnostique l'état de santé d'une culture en saisissant une image de la culture, par exemple.
Même si vous créez une application avec un excellent modèle capable de juger de la maladie, le fait que l'utilisateur saisisse correctement l'image de la culture cible est un problème important pour garantir la fiabilité de l'application.
Par exemple, si vous créez une application qui diagnostique les maladies du riz ci-dessus, même si l'utilisateur entre une image de mauvaises herbes, si vous produisez un résultat comme celui-ci, le résultat du diagnostic de cette application elle-même sera suspect. Je vais finir.
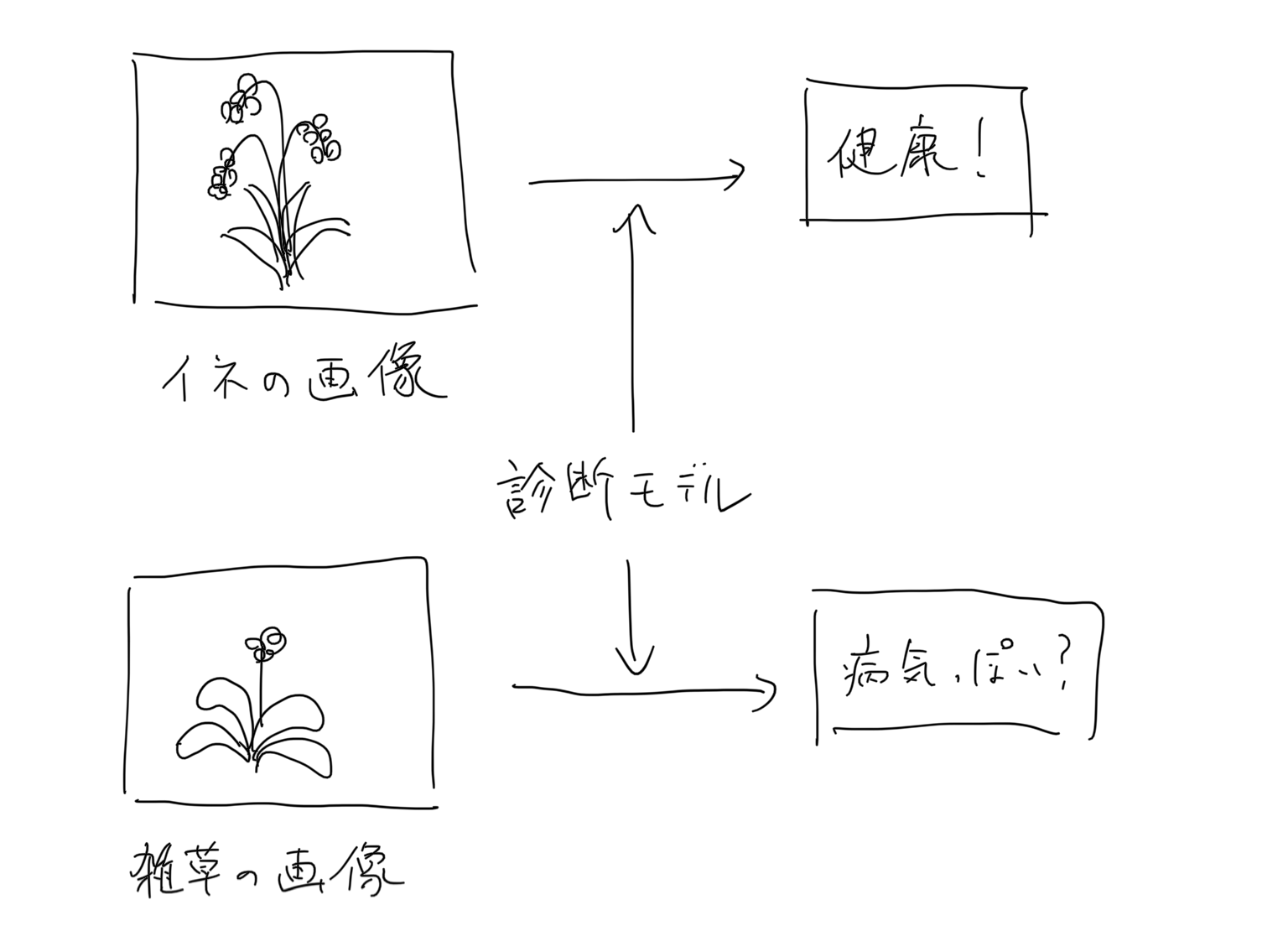
Afin de traiter ce problème, j'ai pensé qu'il serait préférable de placer un modèle de détection d'image anormale de l'image d'entrée devant le modèle principal.

Si seules les images jugées normales dans le modèle de détection d'anomalies sont transmises au modèle principal, il semble que des résultats hautement fiables puissent être produits.
Ce qui a été fait
J'ai installé l'application sur un iPhone X que j'ai acheté il y a trois ans, j'ai affiché une image de riz et de mauvaises herbes sur mon ordinateur portable et je l'ai pris en photo. Si vous faites attention à la jauge circulaire en haut à droite, vous pouvez voir comment le riz et les mauvaises herbes se distinguent d'une manière ou d'une autre.

Ci-dessous, j'écrirai ce que j'ai fait.
Apprentissage métrique
L'apprentissage métrique est une technique utilisée pour créer un modèle qui détermine si une paire d'images est la même. Pour cette exigence, nous avons utilisé cette technique pour déterminer si l'image d'entrée est la même que l'image normale formée.
J'ai fait référence à l'article suivant. https://qiita.com/shinmura0/items/06d81c72601c7578c6d3
modèle
J'ai utilisé Pytorch pour créer le modèle.
Puisque l'objectif est de le mettre sur un smartphone, nous utiliserons le léger MobileNet V2 comme extracteur de fonctionnalités. MobileNet V2 est fourni par torchvision par défaut.
Cette fois, la taille de l'image est de 128x128. Façonnez joliment la sortie de la couche d'entités et faites de la sortie finale un vecteur de 512 dimensions.
from torchvision.models import MobileNetV2
class MobileNetFeatures(nn.Module):
def __init__(self):
super(MobileNetFeatures, self).__init__()
self.head = MobileNetV2().features
self.pool = nn.AvgPool2d(4, 4)
self.flat = nn.Flatten()
self.fc = nn.Linear(1280, 512)
def forward(self, x):
x = self.head(x)
x = self.pool(x)
x = self.flat(x)
x = self.fc(x)
return x
Apprentissage
base de données
En tant que données d'apprentissage, il est nécessaire de donner une image anormale aléatoire en même temps qu'une image normale. Par conséquent, à partir de l'ensemble de données ouvertes ensemble de données COCO, le même nombre d'images que les images normales a été extrait au hasard, et cela a été utilisé comme un ensemble d'images anormales.
Fonction de perte
J'ai utilisé la fonction Loss relativement nouvelle ** Arcface **. Quant à l'explication d'Arcface, l'article suivant était incroyablement facile à comprendre. https://qiita.com/yu4u/items/078054dfb5592cbb80cc
De plus, dans le référentiel suivant, la dernière implémentation papier d'un tel apprentissage métrique est fournie sous forme de bibliothèque, j'ai donc utilisé ceci. https://github.com/KevinMusgrave/pytorch-metric-learning
Mesure des anomalies
La sortie du modèle entraîné est une incorporation de 512 dimensions. Afin de déterminer si l'image d'entrée est anormale, il est nécessaire de prendre la ** similitude cosinus ** avec l'incorporation obtenue à partir de l'image normale.
Par conséquent, lors de la phase d'apprentissage, enregistrez le vecteur moyen d'incorporation des données de validation en même temps que le modèle.
Ensuite, au moment de l'inférence, cela peut être lu et la similitude cosinus avec l'image d'entrée peut être prise pour déterminer si elle est anormale ou non.
train.py
if save_interval > 0 and epoch_id % save_interval == 0:
model.eval()
#Mesurer la similitude cosinus entre les images normales et anormales.
positive_dist = []
negative_dist = []
for batch in valid_loader:
images = batch[0].to(device)
labels = batch[1].numpy().tolist()
labels = [bool(i) for i in labels]
with torch.no_grad():
embeddings = model(images).cpu().numpy()
positive_embeddings = embeddings[labels]
negative_embeddings = embeddings[[not i for i in labels]]
mean_embedding = np.mean(positive_embeddings, axis=0)
for pe in positive_embeddings:
cos_sim = np.dot(mean_embedding, pe) / (np.linalg.norm(mean_embedding, ord=2) * np.linalg.norm(pe, ord=2))
positive_dist.append(cos_sim)
for ne in negative_embeddings:
cos_sim = np.dot(mean_embedding, ne) / (np.linalg.norm(mean_embedding, ord=2) * np.linalg.norm(ne, ord=2))
negative_dist.append(cos_sim)
mean_positive_dist = sum(positive_dist) / len(positive_dist)
mean_negative_dist = sum(negative_dist) / len(negative_dist)
print(f"epoch{epoch_id}: {mean_positive_dist} {mean_negative_dist}")
model.train()
#Enregistrer l'intégration
features_save_path = f"../saved_features/embedding.txt"
np.savetxt(features_save_path, mean_embedding, delimiter=",")
Conversion en modèle de smartphone
Cette fois, j'ai utilisé coreML, en supposant qu'il sera installé sur iOS.
Pour la conversion du modèle Pytorch en coreML, nous passerons une fois par la conversion au format ONNX. (La dernière version de coremltools semble pouvoir convertir sans passer par ONNX, mais cette fois, elle suit l'ancienne méthode en raison du manque de recherche.)
Veuillez vous référer au script suivant.
- Pytorch -> ONNX
- https://github.com/fltwtn/light_weight_annomaly_detection/blob/main/src/save_onnx.py
- ONNX -> CoreML
- https://github.com/fltwtn/light_weight_annomaly_detection/blob/main/src/save_coreml.py
Veuillez noter qu'à partir du 14 novembre 2020, dans l'environnement de Python 3.8.2, une erreur liée à ProtocolBuffer s'est produite et la conversion en ONNX-> CoreML n'a pas fonctionné. Cela peut être résolu en utilisant 3.7.7.
Tout ce que vous avez à faire est d'incorporer le .mlmodel généré dans Swift.
À la fin
L'ensemble du projet se trouve dans le référentiel suivant. https://github.com/fltwtn/light_weight_annomaly_detection
Lorsque je l'ai utilisé sur mon smartphone, j'ai à nouveau réalisé la vitesse de MobileNet V2. Peut-être que c'est plus de 30 images par seconde. .. .. Récemment, des modèles haute précision et haute vitesse ont été publiés l'un après l'autre, je vais donc continuer à essayer de convertir divers modèles en modèles de smartphones.
Recommended Posts