[Français] scikit-learn 0.18 Introduction de l'apprentissage automatique par le didacticiel scikit-learn
google a traduit http://scikit-learn.org/stable/tutorial/basic/tutorial.html. Table des matières du didacticiel scikit-learn 0.18
Contenu de la section
Cette section présente les termes d'apprentissage automatique utilisés dans scikit-learn et donne des exemples d'apprentissage simple.
Apprentissage automatique: définition des problèmes
En général, le problème d'apprentissage considère un ensemble de n échantillons de données et tente de prédire les caractéristiques de données inconnues. Si chaque échantillon est plus grand qu'un seul nombre, ou s'il s'agit d'un élément multidimensionnel (également appelé multivarié), on dit qu'il possède plusieurs attributs ou caractéristiques.
Les problèmes d'apprentissage peuvent être divisés en plusieurs catégories:
--Dans Apprentissage enseigné, les attributs que vous souhaitez prédire sont ajoutés aux données d'entraînement (Cliquez ici. nazoking @ github / items / 267f2371757516f8c168 # 1-% E6% 95% 99% E5% B8% AB% E4% BB% 98% E3% 81% 8D% E5% AD% A6% E7% BF% 92) et scikit -apprendre Visitez la page d'apprentissage supervisé). Ce problème peut être l'un des suivants:
- Classification: les spécimens appartiennent à plus d'une classe et comment prédire la classe de données non étiquetées à partir de données déjà étiquetées Je veux apprendre. Un exemple de problème de classification est la reconnaissance des nombres manuscrits, dont le but est d'assigner chaque vecteur d'entrée à l'une d'un nombre fini de catégories discrètes. Une autre façon de penser à la classification est d'avoir un nombre limité de catégories et d'essayer d'étiqueter chacun des n échantillons fournis avec la bonne catégorie ou classe, de manière autonome (non continue). ) Apprentissage continu par des enseignants. --Regression (https://en.wikipedia.org/wiki/Regression_analysis): Si la sortie souhaitée se compose d'une ou plusieurs variables continues, la tâche est appelée régression. Un exemple de problème de régression est la prédiction de la longueur du saumon en fonction de l'âge et du poids. --Dans Apprentissage non supervisé, les données d'apprentissage sont un ensemble de vecteurs d'entrée x sans valeur cible correspondante. Le but de ces problèmes est de découvrir un groupe d'exemples similaires dans les données appelées Clustering (https://en.wikipedia.org/wiki/Cluster_analysis) ou d'estimer la densité (https: //). Accédez à la page d'apprentissage non supervisé Scikit-Learn pour déterminer la distribution des données dans l'espace d'entrée appelé en.wikipedia.org/wiki/Density_estimation) ou à des fins de visualisation en haute dimension. Cliquez ici (http://qiita.com/nazoking@github/items/267f2371757516f8c168#2-%E6%95%99%E5%B8%AB%E3%81%AA%E3%81%97] % E5% AD% A6% E7% BF% 92) S'il vous plaît.
** Ensemble d'entraînement et ensemble de test ** Le but de l'apprentissage automatique est d'apprendre certaines propriétés d'un ensemble de données et de les appliquer à de nouvelles données. Une façon courante d'évaluer les algorithmes dans l'apprentissage automatique consiste à diviser les données disponibles en deux ensembles. L'un est appelé ** ensemble d'apprentissage ** pour l'apprentissage des caractéristiques des données et l'autre est appelé ** ensemble de test ** pour tester les caractéristiques.
Charger un exemple de jeu de données
scikit-learn inclut iris et chiffres pour la classification. -Based + Recognition + of + Handwritten + Digits) et Boston Home Prices ensembles de données pour la régression, etc. Livré avec plusieurs jeux de données standard.
Ce qui suit lance l'interpréteur Python à partir du shell et charge les ensembles de données ʻirisetdigits. Dans notre notation, $représente une invite du shell et> >>` représente une invite d'interprétation Python.
$ python
>>> from sklearn import datasets
>>> iris = datasets.load_iris()
>>> digits = datasets.load_digits()
Un ensemble de données est un objet de type dictionnaire qui contient toutes les données et certaines métadonnées sur ces données. Ces données sont stockées dans le membre .data. Ceci est un tableau de n_samples, n_features. Avec un enseignant, une ou plusieurs variables de réponse sont stockées dans le membre .target. Pour plus d'informations sur les différents ensembles de données, consultez la section dédiée (http://scikit-learn.org/0.18/datasets/index.html#datasets).
Par exemple, pour l'ensemble de données digits, «digits.data» accède aux fonctionnalités qui peuvent être utilisées pour classer des échantillons numériques.
>>> print(digits.data)
[[ 0. 0. 5. ..., 0. 0. 0.]
[ 0. 0. 0. ..., 10. 0. 0.]
[ 0. 0. 0. ..., 16. 9. 0.]
...,
[ 0. 0. 1. ..., 6. 0. 0.]
[ 0. 0. 2. ..., 12. 0. 0.]
[ 0. 0. 10. ..., 12. 1. 0.]]
digits.target renvoie la valeur de vérité sur laquelle le jeu de données de chiffres est basé. C'est le nombre qui correspond à l'image de chaque nombre que vous essayez d'apprendre.
>>> digits.target
array([0, 1, 2, ..., 8, 9, 8])
** Forme du tableau de données ** Les données sont toujours un tableau à deux dimensions, shape `(n_samples, n_features), même si la forme des données d'origine est différente. Pour les nombres, chaque échantillon original est une image de forme (8,8) ʻet est accessible en utilisant:
>>> digits.images[0]
array([[ 0., 0., 5., 13., 9., 1., 0., 0.],
[ 0., 0., 13., 15., 10., 15., 5., 0.],
[ 0., 3., 15., 2., 0., 11., 8., 0.],
[ 0., 4., 12., 0., 0., 8., 8., 0.],
[ 0., 5., 8., 0., 0., 9., 8., 0.],
[ 0., 4., 11., 0., 1., 12., 7., 0.],
[ 0., 2., 14., 5., 10., 12., 0., 0.],
[ 0., 0., 6., 13., 10., 0., 0., 0.]])
Cet exemple simple d'ensemble de données est Il montre comment vous pouvez commencer avec le problème d'origine et façonner les données que vous consommez avec scicit-learn.
** Chargement à partir d'un ensemble de données externe **
Pour charger à partir d'un ensemble de données externe, consultez Chargement d'un ensemble de données externe (http://scikit-learn.org/0.18/datasets/index.html#external-datasets).
Apprentissage et prédiction
Pour l'ensemble de données de chiffres, la tâche consiste à prédire les nombres qu'il représente, compte tenu de l'image. L'estimateur (https://en.wikipedia.org/wiki/Estimator) reçoit un échantillon de 10 classes possibles (nombres de zéro à 9) afin que la classe à laquelle appartient l'échantillon inconnu puisse être prédite. Peut être fait.
Dans scikit-learn, l'estimateur de classification est un objet Python qui implémente les méthodes «fit (X, y)» et «prédire (T)».
Un exemple d'estimateur est la classe sklearn.svm.SVC, qui implémente la classification vectorielle de support. Le constructeur de l'estimateur prend les paramètres du modèle comme arguments, mais considère pour le moment l'estimateur comme une boîte noire:
>>> from sklearn import svm
>>> clf = svm.SVC(gamma=0.001, C=100.)
** Sélection des paramètres du modèle ** Dans cet exemple, définissez manuellement la valeur de «gamma». Grid Search et Cross Validation etc. Vous pouvez utiliser les outils de pour rechercher automatiquement les valeurs appropriées pour vos paramètres.
J'ai nommé l'instance d'estimateur «clf» car c'est un classificateur. Vous devez rendre le modèle «fit». Autrement dit, vous devez apprendre du modèle. Cela se fait en passant l'ensemble d'entraînement à la méthode fit. En tant qu'ensemble d'entraînement, utilisez toutes les images de votre ensemble de données à l'exception de la dernière. Sélectionnez cet ensemble d'entraînement avec la syntaxe Python [: -1]. Cela générera un nouveau tableau contenant tout sauf la dernière entrée dans digits.data.
>>> clf.fit(digits.data[:-1], digits.target[:-1])
SVC(C=100.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma=0.001, kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
Vous pouvez désormais prédire de nouvelles valeurs. Alors, quel numéro est la dernière image de l'ensemble de données de chiffres que vous n'avez pas utilisé pour entraîner le classificateur?
>>> clf.predict(digits.data[-1:])
array([8])
Les images correspondantes sont:
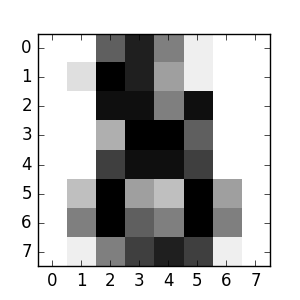
Comme vous pouvez le voir, c'est une tâche difficile. La résolution de l'image est faible. Êtes-vous d'accord avec le classificateur? Un exemple complet de ce problème de classification est disponible comme exemple que vous pouvez exécuter et apprendre. Reconnaître les nombres manuscrits
Persistance du modèle
Vous pouvez utiliser le module de persistance intégré de Python, pickle, pour enregistrer votre modèle scicit:
>>> from sklearn import svm
>>> from sklearn import datasets
>>> clf = svm.SVC()
>>> iris = datasets.load_iris()
>>> X, y = iris.data, iris.target
>>> clf.fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> import pickle
>>> s = pickle.dumps(clf)
>>> clf2 = pickle.loads(s)
>>> clf2.predict(X[0:1])
array([0])
>>> y[0]
0
Dans certains cas de scikit, il peut être préférable d'utiliser le remplacement de joblib pickle (joblib.dump et joblib.load). Il est plus efficace pour les données volumineuses, mais il ne peut être enregistré que sur le disque.
>>> from sklearn.externals import joblib
>>> joblib.dump(clf, 'filename.pkl')
Vous pouvez ensuite charger le modèle pickled (peut-être dans un autre processus Python):
>>> clf = joblib.load('filename.pkl')
Remarque Les fonctions
joblib.dumpetjoblib.loadacceptent également un objet de type fichier au lieu d'un nom de fichier. Pour plus d'informations sur la persistance des données dans Joblib, voir ici (https://pythonhosted.org/joblib/persistence.html).
Gardez à l'esprit que pickle a des problèmes de sécurité et de maintenabilité. Pour plus d'informations sur la persistance des modèles avec scikit-learn, voir Persistance des modèles.
termes
L'estimateur scikit-learn suit certaines règles pour rendre son comportement plus prédictif.
Type fonte
Sauf indication contraire, l'entrée sera convertie en float64:
>>> import numpy as np
>>> from sklearn import random_projection
>>> rng = np.random.RandomState(0)
>>> X = rng.rand(10, 2000)
>>> X = np.array(X, dtype='float32')
>>> X.dtype
dtype('float32')
>>> transformer = random_projection.GaussianRandomProjection()
>>> X_new = transformer.fit_transform(X)
>>> X_new.dtype
dtype('float64')
Dans cet exemple, «X» est «float32» et est converti en «float64» par «fit_transform (X)». La cible de régression est convertie en «float64» et la cible de classification est conservée.
>>> from sklearn import datasets
>>> from sklearn.svm import SVC
>>> iris = datasets.load_iris()
>>> clf = SVC()
>>> clf.fit(iris.data, iris.target)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> list(clf.predict(iris.data[:3]))
[0, 0, 0]
>>> clf.fit(iris.data, iris.target_names[iris.target])
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> list(clf.predict(iris.data[:3]))
['setosa', 'setosa', 'setosa']
Ici, le premier predire () retourne un tableau d'entiers car ʻiris.target(tableau d'entiers) a été utilisé dansfit. Le second predire () retourne un tableau de chaînes. Parce que ʻiris.target_names était pour le montage.
Mises à jour et mises à jour des paramètres
Les hyperparamètres de l'estimateur sont la méthode sklearn.pipeline.Pipeline.set_params. Peut être mis à jour après avoir été créé en utilisant. Appeler fit () plusieurs fois écrase ce qui a été appris par le précédent fit ():
>>> from sklearn.svm import SVC
>>> rng = np.random.RandomState(0)
>>> X = rng.rand(100, 10)
>>> y = rng.binomial(1, 0.5, 100)
>>> X_test = rng.rand(5, 10)
>>> clf = SVC()
>>> clf.set_params(kernel='linear').fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma='auto', kernel='linear',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> clf.predict(X_test)
array([1, 0, 1, 1, 0])
>>> clf.set_params(kernel='rbf').fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> clf.predict(X_test)
array([0, 0, 0, 1, 0])
Ici, le noyau par défaut «rbf» est d'abord modifié linéairement après que l'estimateur a été construit via «SVC ()», puis revient à «rbf» pour reconfigurer l'estimateur et faire une seconde prédiction. Faire.
Raccord multi-classes et multi-étiquettes
Lors de l'utilisation du classificateur multiclasse (http://scikit-learn.org/0.18/modules/classes.html#module-sklearn.multiclass), les tâches d'entraînement et de prédiction effectuées seront au format des données cibles. Dépend.
>>> from sklearn.svm import SVC
>>> from sklearn.multiclass import OneVsRestClassifier
>>> from sklearn.preprocessing import LabelBinarizer
>>> X = [[1, 2], [2, 4], [4, 5], [3, 2], [3, 1]]
>>> y = [0, 0, 1, 1, 2]
>>> classif = OneVsRestClassifier(estimator=SVC(random_state=0))
>>> classif.fit(X, y).predict(X)
array([0, 0, 1, 1, 2])
Dans le cas ci-dessus, le classificateur s'insère dans un tableau unidimensionnel multi-étiqueté, de sorte que la méthode predict () fournit la prédiction multi-classe correspondante. Il est également possible de s'insérer dans un tableau bidimensionnel d'indicateurs d'étiquettes binaires:
>>> y = LabelBinarizer().fit_transform(y)
>>> classif.fit(X, y).predict(X)
array([[1, 0, 0],
[1, 0, 0],
[0, 1, 0],
[0, 0, 0],
[0, 0, 0]])
Ici, le classificateur utilise LabelBinarizer pour créer les deux dimensions de y. Ajuster () à la représentation d'étiquette binaire. Dans ce cas, «predict ()» renvoie un tableau bidimensionnel représentant la prédiction multi-étiquettes correspondante.
Les 4ème et 5ème instances renvoient toutes 0, indiquant qu'aucune des 3 étiquettes "convient". Avec la sortie multi-étiquettes, il est également possible d'attribuer plusieurs étiquettes à une instance.
>> from sklearn.preprocessing import MultiLabelBinarizer
>> y = [[0, 1], [0, 2], [1, 3], [0, 2, 3], [2, 4]]
>> y = preprocessing.MultiLabelBinarizer().fit_transform(y)
>> classif.fit(X, y).predict(X)
array([[1, 1, 0, 0, 0],
[1, 0, 1, 0, 0],
[0, 1, 0, 1, 0],
[1, 0, 1, 1, 0],
[0, 0, 1, 0, 1]])
Dans ce cas, le classificateur s'insère dans une instance, chacune étant affectée de plusieurs étiquettes. MultiLabelBinarizer est utilisé pour faire évoluer un tableau bidimensionnel multi-étiqueté. Je vais. En conséquence, «predict ()» renvoie un tableau à deux dimensions avec plusieurs étiquettes prédictives par instance.
© 2010 --2016, développeurs scikit-learn (licence BSD).
Recommended Posts