Comment visualiser où se produit une mauvaise classification dans la classification de l'analyse des données
Identifier où l'erreur de classification s'est produite pour améliorer l'exactitude des résultats de l'analyse des données
C'est le thème de cette époque.
Donc, aujourd'hui, nous allons utiliser la matrice de confusion pour visualiser où l'erreur de classification s'est produite.
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import confusion_matrix
clf = DecisionTreeClassifier()
clf.fit(X_train, Y_train)
result = clf.predict(X_test)
cm = confusion_matrix(Y_test, result)
print(cm)
En utilisant le jeu de données iris, il sera visualisé comme indiqué dans la figure ci-dessous.
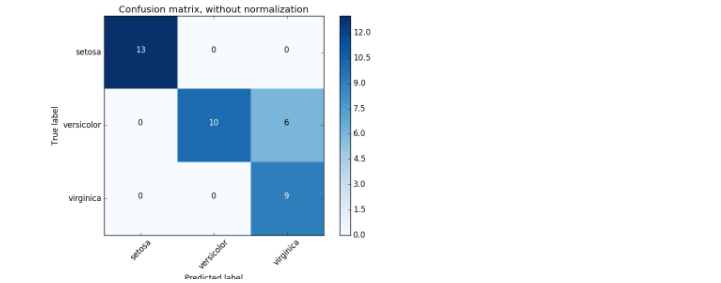 Extrait de sklearn Official Document
Extrait de sklearn Official Document
Cela peut être un peu petit et difficile à voir, mais l'axe des y est la valeur Vraie, c'est-à-dire l'étiquetage correct, l'axe des x est la valeur prévue et il est étiqueté à l'aide d'un modèle d'apprentissage automatique. En regardant la figure ci-dessus, il y a une erreur de classification dans la rangée centrale, à droite.
En reconnaissant cela, l'examen du prétraitement des données et le réajustement des paramètres du modèle d'apprentissage automatique peuvent améliorer la précision.
Recommended Posts