Prédire à partir de diverses données en Python à l'aide de l'outil de prédiction de séries chronologiques Facebook Prophet
Cet article est [Greg Rafferty](https://towardsdatascience.com/@raffg?source=post_page-----29810eb57e66 -------------------- ---) Il s'agit d'une traduction japonaise de "Forecasting in Python with Facebook Prophet" publiée par M. en novembre 2019. .. Cet article est publié avec l'autorisation de l'auteur original.
Je suis Greg Rafferty, un data scientist dans la Bay Area. Vous pouvez également vérifier le code utilisé dans ce projet depuis mon github.
Dans cet article, je vais vous montrer comment faire diverses prédictions à l'aide d'une bibliothèque de prédictions appelée Facebook Prophet, et quelques techniques avancées pour utiliser votre expertise pour gérer les incohérences de tendance. Il existe de nombreux didacticiels Prophet sur le Web, mais toutes les façons de régler le modèle de Prophet et d'intégrer les connaissances des analystes pour que le modèle navigue correctement dans les données sont trop détaillées. ne pas. Cet article couvrira les deux.
 https://www.instagram.com/p/BaKEnIPFUq-/
https://www.instagram.com/p/BaKEnIPFUq-/
Un article précédent sur Prediction Using Tableau (https://towardsdatascience.com/forecasting-with-python-and-tableau-dd37a218a1e5) utilisait un algorithme ARIMA modifié pour les passagers sur des vols commerciaux aux États-Unis. J'ai prédit le nombre. Bien que l'approche d'ARIMA fonctionne bien pour prédire les données stationnaires et les délais courts, il existe certains cas qu'ARIMA ne peut pas gérer, et les ingénieurs de Facebook ont développé des outils à utiliser dans ces cas. Prophet construit son backend en STAN, un langage de codage probabiliste. Cela permet à Prophet de bénéficier de nombreux avantages des statistiques Bayes, y compris la saisonnalité, l'inclusion d'expertise et les intervalles de confiance qui ajoutent des estimations de risque basées sur les données.
Ici, nous allons examiner trois sources de données pour expliquer comment utiliser Prophet et ses avantages. Si vous voulez vraiment l'essayer à portée de main, installez d'abord Prophet. Il y a une brève description dans Facebook Documentation. Tout le code nécessaire à la construction du modèle utilisé pour écrire cet article se trouve dans ce Notebook. Je vais.
Passager aérien
Commençons par les plus simples. Utilisez les mêmes données sur les passagers aériens que celles utilisées dans l'article précédent (https://towardsdatascience.com/forecasting-with-python-and-tableau-dd37a218a1e5). Prophet requiert des données chronologiques avec deux colonnes ou plus, l'horodatage ds et la valeur y. Après avoir chargé les données, formatez-les comme suit:
passengers = pd.read_csv('data/AirPassengers.csv')df = pd.DataFrame()
df['ds'] = pd.to_datetime(passengers['Month'])
df['y'] = passengers['#Passengers']
En quelques lignes, Prophet peut créer un modèle prédictif aussi sophistiqué que le modèle ARIMA que j'ai construit précédemment. Ici, j'appelle Prophet et je fais une prévision sur 6 ans (fréquence mensuelle, 12 mois x 6 ans):
prophet = Prophet()
prophet.fit(df)
future = prophet.make_future_dataframe(periods=12 * 6, freq='M')
forecast = prophet.predict(future)
fig = prophet.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), prophet, forecast)
 Nombre de passagers des compagnies aériennes commerciales américaines (en unités de 1000)
Nombre de passagers des compagnies aériennes commerciales américaines (en unités de 1000)
Prophet entoure les données d'origine avec des points noirs et affiche le modèle prédictif avec une ligne bleue. La zone bleu clair est l'intervalle de confiance. La fonction add_changepoints_to_plot ajoute également une ligne rouge. La ligne pointillée rouge dessinée verticalement montre où Prophet a identifié le changement de tendance, et la courbe rouge montre la tendance avec toute saisonnalité supprimée. Cet article continuera à utiliser ce format de tracé.
C'est tout pour le cas simple, et examinons maintenant des données plus complexes.
Partage de vélos Divvy
Divvy est le service de partage de vélos de Chicago. J'ai déjà travaillé sur un projet qui analysait les données de Divvy et les associait à des informations météorologiques recueillies auprès de Weather Underground. Je savais que ces données montraient une forte saisonnalité, alors je l'ai choisie parce que je pensais que ce serait un excellent exemple de démonstration des capacités de Prophet.
Les données Divvy sont triées par trajet. Pour formater les données pour Prophet, additionnez d'abord le niveau journalier, puis le mode de colonne «événements» quotidiens (par exemple, conditions météorologiques: «imprécis», «pluie ou neige», «ensoleillé», «ensoleillé»). Créez une colonne composée de nuageux, orageux, inconnu, etc.), le nombre d'utilisations (manèges) et la température moyenne.
Une fois les données formatées, voyons combien de fois elles sont utilisées par jour:

De cela, nous pouvons voir que les données ont une saisonnalité claire et les tendances augmentent avec le temps. Nous utiliserons cet ensemble de données pour décrire comment ajouter des régresseurs supplémentaires, dans ce cas, la météo et la température. Voyons la température:

Similaire au graphique précédent, mais sans tendance à la hausse. Cette similitude a du sens car plus de gens font du vélo les jours ensoleillés et chauds et les deux parcelles montent et descendent en tandem.
Lorsque vous ajoutez une autre variable explicative externe pour créer une prévision, la variable externe que vous ajoutez nécessite des données de période de prévision. Pour cette raison, j'ai raccourci les données de Divvy d'un an afin de pouvoir prédire cette année avec les informations météorologiques. Vous pouvez également voir que Prophet a ajouté les jours fériés américains par défaut.
prophet = Prophet()
prophet.add_country_holidays(country_name='US')
prophet.fit(df[d['date'] < pd.to_datetime('2017-01-01')])
future = prophet.make_future_dataframe(periods=365, freq='d')
forecast = prophet.predict(future)
fig = prophet.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), prophet, forecast)
plt.show()
fig2 = prophet.plot_components(forecast)
plt.show()
Le bloc de code ci-dessus crée le graphique de tendance décrit dans la section Passager aérien.
 Diagramme de tendance Divvy
Diagramme de tendance Divvy
Et voici le graphique des composants:
 Graphique des composants Divvy
Graphique des composants Divvy
Le graphique des composants comprend trois sections: les tendances, les vacances et la saisonnalité. La somme de ces trois composants constitue en fait le modèle entier. Les tendances sont les données après soustraction de tous les autres composants. Le graphique des vacances montre l'impact de toutes les vacances dans le modèle. Les vacances implémentées dans Prophet peuvent être considérées comme des événements non naturels, où la tendance s'écarte de la ligne de base mais revient après la fin de l'événement. Les variables explicatives externes (plus à ce sujet plus tard) sont similaires aux vacances en ce qu'elles peuvent faire dévier la tendance par rapport à la ligne de base, mais la tendance reste inchangée après l'événement. Dans ce cas, tous les jours fériés ont entraîné une diminution du nombre de passagers, ce qui est également logique étant donné que bon nombre de nos utilisateurs sont des navetteurs. En regardant la composante saisonnière hebdomadaire, nous pouvons voir que le nombre d'utilisateurs est presque constant tout au long de la semaine, mais diminue fortement le week-end. Cela fournit des preuves supplémentaires à l'appui de l'hypothèse selon laquelle la plupart des passagers sont des navetteurs. Last but not least, le graphique de la variation saisonnière au cours de l'année est assez ondulé. Ces parcelles sont constituées de transformées de Fourier, essentiellement des sinusoïdes empilées. De toute évidence, la valeur par défaut dans ce cas est trop flexible. Pour lisser la courbe, nous allons maintenant créer un modèle Prophet pour désactiver la saisonnalité de l'année et ajouter des variables externes pour l'adapter, mais avec moins de liberté. Le modèle ajoute également ces variables météorologiques.
prophet = Prophet(growth='linear',
yearly_seasonality=False,
weekly_seasonality=True,
daily_seasonality=False,
holidays=None,
seasonality_mode='multiplicative',
seasonality_prior_scale=10,
holidays_prior_scale=10,
changepoint_prior_scale=.05,
mcmc_samples=0
).add_seasonality(name='yearly',
period=365.25,
fourier_order=3,
prior_scale=10,
mode='additive')prophet.add_country_holidays(country_name='US')
prophet.add_regressor('temp')
prophet.add_regressor('cloudy')
prophet.add_regressor('not clear')
prophet.add_regressor('rain or snow')
prophet.fit(df[df['ds'] < pd.to_datetime('2017')])
future = prophet.make_future_dataframe(periods=365, freq='D')
future['temp'] = df['temp']
future['cloudy'] = df['cloudy']
future['not clear'] = df['not clear']
future['rain or snow'] = df['rain or snow']
forecast = prophet.predict(future)
fig = prophet.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), prophet, forecast)
plt.show()
fig2 = prophet.plot_components(forecast)
plt.show()
Les graphiques de tendance étaient à peu près les mêmes, donc je ne vais vous montrer que les graphiques de composants:
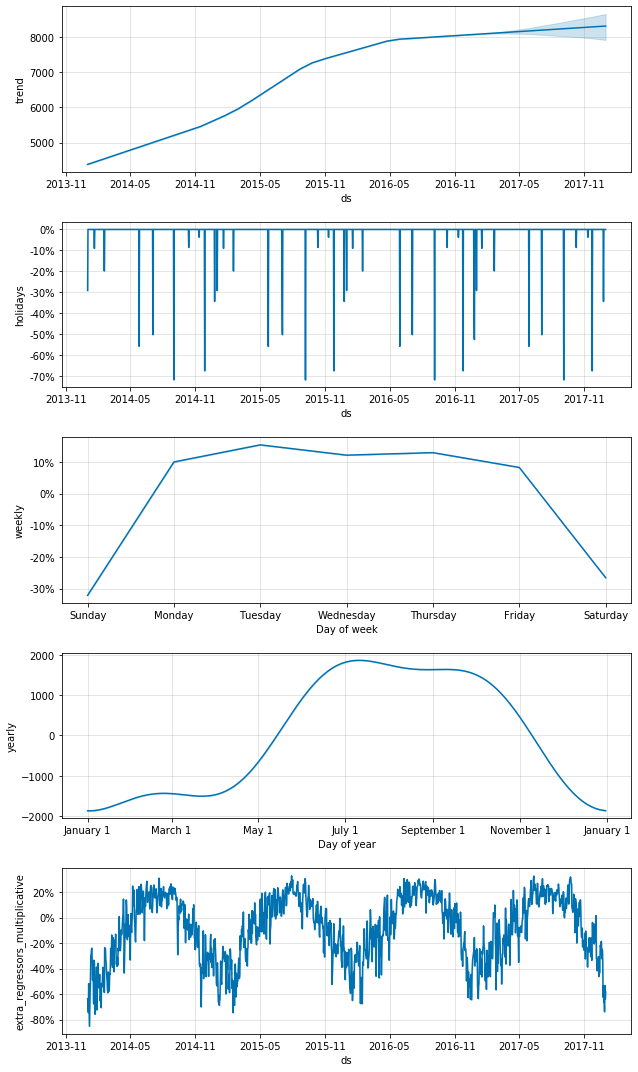 Diagramme de composantes Divvy avec courbes lissées et ajout de variables externes pour la saisonnalité annuelle et la météo
Diagramme de composantes Divvy avec courbes lissées et ajout de variables externes pour la saisonnalité annuelle et la météo
Dans cette intrigue, la dernière année de la tendance est à la hausse, pas à la baisse comme la première intrigue! Cela peut s'expliquer par le fait que la température moyenne dans les données de l'année dernière était basse et que le nombre d'utilisateurs a diminué plus que prévu. De plus, la courbe annuelle a été lissée et un graphique extra_regressors_multiplicative a été ajouté. Cela montre l'effet de la météo. L'augmentation / diminution du nombre d'utilisateurs est également conforme aux attentes. Le nombre d'utilisateurs augmente en été et diminue en hiver, et bon nombre des fluctuations peuvent être expliquées par les conditions météorologiques. Il y a encore une chose que je voudrais confirmer pour la démonstration. Exécutez à nouveau le modèle ci-dessus, en ajoutant cette fois uniquement les variables externes de pluie et de neige. Le tracé des composants ressemble à ceci:
 Diagramme des composants Divvy montrant uniquement les effets de la pluie et de la neige
Diagramme des composants Divvy montrant uniquement les effets de la pluie et de la neige
Cela montre que les jours de pluie ou de neige, le nombre d'usages quotidiens est d'environ 1400 de moins que les jours sans pluie. C’est assez intéressant, non?
Enfin, nous agrégons ce jeu de données à l'heure pour créer un autre diagramme de composants, la saisonnalité quotidienne. L'intrigue ressemble à ceci:
 Diagramme des composantes Divvy montrant la saisonnalité quotidienne
Diagramme des composantes Divvy montrant la saisonnalité quotidienne
Comme le dit M. Rivers, 4 heures du matin est le pire moment pour se lever le matin. Apparemment, les motards de Chicago sont d'accord. Après 8 heures du matin, le pic est atteint par les navetteurs du matin. Et vers 18 heures, tout le pic des rapatriés dans la soirée viendra. Vous pouvez également voir qu'il y a un petit pic après minuit. Probablement à cause de ceux qui reviennent du bar. Ce sont les données Divvy! Ensuite, passons à Instagram.
Prophet a été conçu à l'origine par Facebook pour analyser ses propres données. Ensuite, cet ensemble de données est un excellent endroit pour essayer Prophet. J'ai cherché sur Instagram des comptes présentant des tendances intéressantes et j'ai trouvé trois comptes: @natgeo, @kosh_dp //www.instagram.com/kosh_dp/), @ jamesrodriguez10
National Geographic
 https://www.instagram.com/p/B5G_U_IgVKv/
https://www.instagram.com/p/B5G_U_IgVKv/
En 2017, alors que je travaillais sur un projet, je travaillais sur un [compte Instagram] National Geographic (https: // J'ai remarqué qu'il y a une anomalie sur www.instagram.com/natgeo/). En août 2016, il y a eu un incident au cours duquel le nombre de likes par photo a mystérieusement augmenté de façon spectaculaire et est revenu à la ligne de base dès la fin du mois d'août. Je voulais modéliser cette poussée à la suite d'une campagne marketing d'un mois pour augmenter le nombre de likes et voir si je pouvais prédire l'efficacité des futures campagnes marketing.
Le nombre de goûts de National Geographic est le suivant. Les tendances augmentent clairement et la variabilité augmente avec le temps. Il y a de nombreuses exceptions avec des likes considérablement plus élevés, mais dans le Spike d'août 2016, toutes les photos publiées ce mois-là étaient extrêmement nombreuses que celles publiées les mois avant et après. J'ai gagné le numéro.

Je ne veux pas deviner pourquoi, mais supposons que pour ce modèle que nous avons créé, par exemple, le service marketing de National Geographic a lancé une campagne d'un mois visant spécifiquement à augmenter le nombre de likes. Regardons. Tout d'abord, construisez un modèle qui ignore ce fait et créez une base de référence pour la comparaison.
 Nombre de likes par photo de National Geographic
Nombre de likes par photo de National Geographic
Le Prophète semble confus par cette pointe. Vous pouvez voir que nous essayons d'ajouter ce pic à la composante saisonnière de chaque année, car la ligne bleue montre la poussée en août de chaque année. Prophet veut appeler cela un événement récurrent. Faisons des vacances ce mois-ci pour dire à Prophet que quelque chose de spécial s'est produit en 2016 qui ne s'est pas répété les autres années:
promo = pd.DataFrame({'holiday': "Promo event",
'ds' : pd.to_datetime(['2016-08-01']),
'lower_window': 0,
'upper_window': 31})
future_promo = pd.DataFrame({'holiday': "Promo event",
'ds' : pd.to_datetime(['2020-08-01']),
'lower_window': 0,
'upper_window': 31})promos_hypothetical = pd.concat([promo, future_promo])
Le cadre de données promotionnelles contient uniquement les événements d'août 2016 et le bloc de données promos_hypothetical contient des promotions supplémentaires que National Geographic suppose être mises en œuvre en août 2020. Lors de l'ajout de jours fériés, Prophet vous permet d'inclure plus ou moins de jours dans les événements de vacances de base, par exemple si le Black Friday est inclus dans Thanksgiving ou le réveillon de Noël est inclus dans Noël. peut aussi faire. Cette fois, j'ai ajouté 31 jours après "vacances" pour inclure le mois entier dans l'événement. Vous trouverez ci-dessous le code et le nouveau graphique de tendance. Notez que nous avons spécifié vacances = promo lors de l'appel de l'objet Prophet.
prophet = Prophet(holidays=promo)
prophet.add_country_holidays(country_name='US')
prophet.fit(df)
future = prophet.make_future_dataframe(periods=365, freq='D')
forecast = prophet.predict(future)
fig = prophet.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), prophet, forecast)
plt.show()
fig2 = prophet.plot_components(forecast)
plt.show()
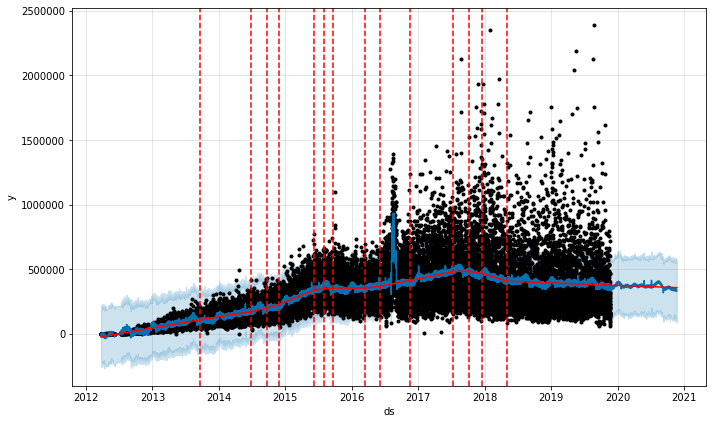 Nombre de likes par photo de National Geographic, y compris la campagne marketing en août 2016
Nombre de likes par photo de National Geographic, y compris la campagne marketing en août 2016
C'est merveilleux! Ici, Prophet montre que cette augmentation ridicule des likes n'a certainement augmenté qu'en 2016, pas en août de chaque année. Utilisons donc à nouveau ce modèle, en utilisant la base de données promos_hypothetical, pour prédire ce qui se passerait si National Geographic menait la même campagne en 2020.
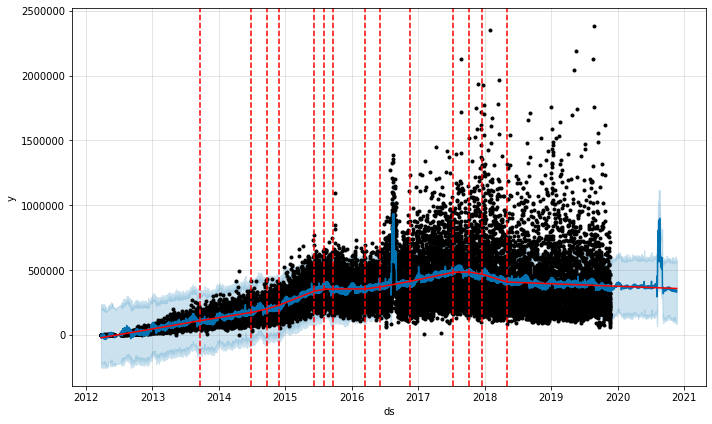 Nombre de likes par photo National Geographic, en supposant une campagne marketing en 2020
Nombre de likes par photo National Geographic, en supposant une campagne marketing en 2020
Vous pouvez utiliser cette méthode pour prédire ce qui se passe lorsque vous ajoutez un événement non naturel. Par exemple, le plan de vente de produits de cette année peut être un modèle. Passons au compte suivant.
Anastasia Kosh
 https://www.instagram.com/p/BfZG2QCgL37/
https://www.instagram.com/p/BfZG2QCgL37/
Anastasia Kosh est une photographe russe qui publie des autoportraits loufoques sur son Instagram et des clips vidéo sur YouTube. Lorsque j'habitais à Moscou il y a quelques années, nous vivions dans la même rue et étions voisins. À l'époque, son Instagram comptait environ 10000 abonnés, mais en 2017, les comptes YouTube se sont rapidement répandus en Russie, faisant d'elle une petite célébrité, en particulier chez les adolescents de Moscou. Son compte Instagram a connu une croissance exponentielle et ses abonnés approchent rapidement du million, et je pensais que cette croissance exponentielle serait un défi parfait pour Prophet.
Les données à modéliser sont:
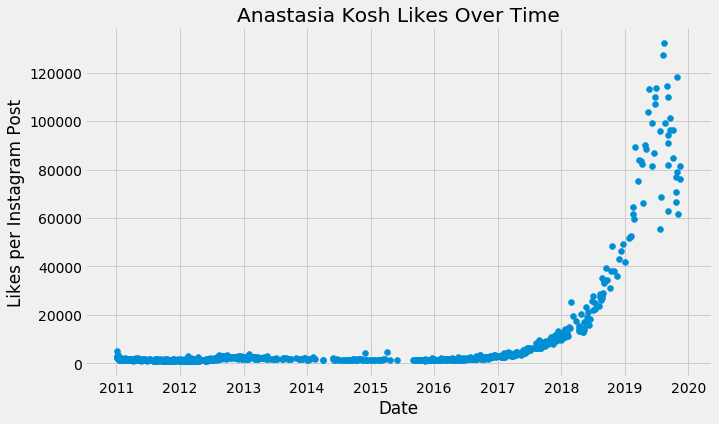
C'est un type de tique de hockey typique et montre une croissance optimiste, mais ce n'est que dans ce cas que ce serait vraiment le cas! Comme les autres données que nous avons vues jusqu'à présent, la modélisation avec une croissance linéaire donne des prédictions irréalistes.
 Nombre de likes par photo d'Anastasia Kosh grandissant linéairement
Nombre de likes par photo d'Anastasia Kosh grandissant linéairement
Cette courbe se poursuit indéfiniment. Mais, bien sûr, il y a une limite au nombre de likes Instagram. Théoriquement, cette limite est égale au nombre total de comptes enregistrés sur le service. Mais en réalité, tous les comptes ne voient pas les photos et ils ne les aiment pas. C'est là qu'un peu d'expertise en tant qu'analyste est utile. Cette fois, j'ai décidé de modéliser cela avec une croissance logistique. Pour ce faire, vous devez indiquer à Prophet le plafond de la limite supérieure (Prophet l'appelle cap) et le plancher de la limite inférieure.
cap = 200000
floor = 0
df['cap'] = cap
df['floor'] = floor
Après ma connaissance d'Instagram et quelques essais et erreurs, j'ai décidé de limiter le nombre de likes à 200000 et la limite inférieure à 0. Dans Prophet, ces valeurs peuvent être définies en fonction du temps et ne doivent pas nécessairement être des constantes. Dans ce cas, vous avez vraiment besoin d'une valeur constante:
prophet = Prophet(growth='logistic',
changepoint_range=0.95,
yearly_seasonality=False,
weekly_seasonality=False,
daily_seasonality=False,
seasonality_prior_scale=10,
changepoint_prior_scale=.01)
prophet.add_country_holidays(country_name='RU')
prophet.fit(df)
future = prophet.make_future_dataframe(periods=1460, freq='D')
future['cap'] = cap
future['floor'] = floor
forecast = prophet.predict(future)
fig = prophet.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), prophet, forecast)
plt.show()
fig2 = prophet.plot_components(forecast)
plt.show()
J'ai défini cette croissance comme une croissance logistique cette fois-ci, en désactivant toute saisonnalité (cela ne semble pas être tant que ça dans ce graphique) et en ajustant quelques paramètres supplémentaires. Comme la plupart des adeptes d'Anastasia sont en Russie, j'ai également ajouté les vacances par défaut de la Russie. Lorsque vous appelez la méthode .fit avec df, Prophet regarde les colonnes cap et floor de df et reconnaît qu'elles doivent être incluses dans le modèle. À ce stade, ajoutons ces colonnes à la trame de données lors de la création de la trame de données de prédiction (future trame de données du bloc de code ci-dessus). Cela sera expliqué à nouveau dans la section suivante. Mais pour l'instant, le graphique des tendances est beaucoup plus réaliste!
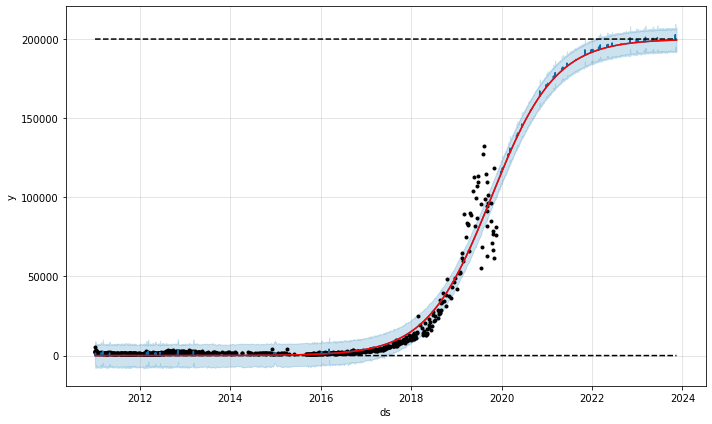 Croissance logistique Anastasia Kosh Nombre de j'aime par photo
Croissance logistique Anastasia Kosh Nombre de j'aime par photo
Regardons le dernier exemple.
James Rodríguez
 https://www.instagram.com/p/BySl8I7HOWa/
https://www.instagram.com/p/BySl8I7HOWa/
James Rodríguez est un footballeur colombien qui a très bien joué lors des Coupes du monde 2014 et 2018. Son compte Instagram n'a cessé de croître depuis son ouverture. Cependant, tout en travaillant sur Analyse précédente, lors des deux dernières Coupes du monde, son J'ai remarqué une augmentation rapide et soutenue du nombre de followers sur mon compte. Contrairement à la prolifération des comptes National Geographic qui peuvent être modélisés comme une saison des fêtes, la croissance de Rodríguez n'est pas revenue à la base après deux tournois et redéfinit une nouvelle base. Il s'agit d'un mouvement radicalement différent, et capturer ce mouvement nécessite une approche de modélisation différente.
Vous trouverez ci-dessous le nombre de likes par photo depuis l'ouverture du compte James Rodríguez:

Il est difficile de modéliser cela proprement avec les techniques utilisées jusqu'à présent dans ce didacticiel. La tendance de référence a augmenté lors de la 1ère Coupe du monde à l'été 2014, des pics se sont produits lors de la 2ème Coupe du monde à l'été 2018, et la référence peut avoir changé. Tenter de modéliser ce comportement avec le modèle par défaut ne fonctionne pas.
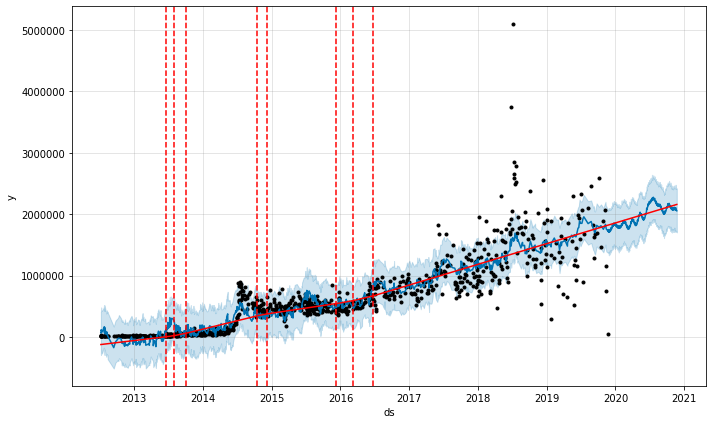 Nombre de likes par photo de James Rodríguez
Nombre de likes par photo de James Rodríguez
Cependant, ce n'est pas un modèle terrible. C'est juste que le comportement dans ces deux Coupes du monde n'est pas bien modélisé. Si vous modélisez ces tournois comme des vacances, comme dans les données Anastasia Kosh ci-dessus, vous verrez des améliorations dans le modèle.
wc_2014 = pd.DataFrame({'holiday': "World Cup 2014",
'ds' : pd.to_datetime(['2014-06-12']),
'lower_window': 0,
'upper_window': 40})
wc_2018 = pd.DataFrame({'holiday': "World Cup 2018",
'ds' : pd.to_datetime(['2018-06-14']),
'lower_window': 0,
'upper_window': 40})world_cup = pd.concat([wc_2014, wc_2018])prophet = Prophet(yearly_seasonality=False,
weekly_seasonality=False,
daily_seasonality=False,
holidays=world_cup,
changepoint_prior_scale=.1)
prophet.fit(df)
future = prophet.make_future_dataframe(periods=365, freq='D')
forecast = prophet.predict(future)
fig = prophet.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), prophet, forecast)
plt.show()
fig2 = prophet.plot_components(forecast)
plt.show()
 Nombre de likes par photo de James Rodríguez lors de l'ajout de vacances pendant la Coupe du monde
Nombre de likes par photo de James Rodríguez lors de l'ajout de vacances pendant la Coupe du monde
Il est trop tard pour que le modèle réponde aux tendances changeantes, en particulier lors de la Coupe du monde 2014, et personnellement je ne l'aime pas encore. La transition de la ligne de tendance est trop douce. Dans de tels cas, vous pouvez ajouter une variable explicative externe pour que Prophet prenne en compte les changements soudains.
Dans cet exemple, chaque tournoi définit deux périodes, pré-tournoi et post-convention. En modélisant de cette manière, nous supposons qu'il existe une ligne de tendance spécifique avant le tournoi, cette ligne de tendance subit un changement linéaire pendant le tournoi, suivi d'une ligne de tendance différente après le tournoi. .. Je définis ces périodes comme 0 ou 1, activées ou désactivées et laisse Prophet entraîner les données pour connaître leur ampleur.
df['during_world_cup_2014'] = 0
df.loc[(df['ds'] >= pd.to_datetime('2014-05-02')) & (df['ds'] <= pd.to_datetime('2014-08-25')), 'during_world_cup_2014'] = 1
df['after_world_cup_2014'] = 0
df.loc[(df['ds'] >= pd.to_datetime('2014-08-25')), 'after_world_cup_2014'] = 1df['during_world_cup_2018'] = 0
df.loc[(df['ds'] >= pd.to_datetime('2018-06-04')) & (df['ds'] <= pd.to_datetime('2018-07-03')), 'during_world_cup_2018'] = 1
df['after_world_cup_2018'] = 0
df.loc[(df['ds'] >= pd.to_datetime('2018-07-03')), 'after_world_cup_2018'] = 1
Mettez à jour les futures dataframes pour inclure les événements "vacances" comme suit:
prophet = Prophet(yearly_seasonality=False,
weekly_seasonality=False,
daily_seasonality=False,
holidays=world_cup,
changepoint_prior_scale=.1)prophet.add_regressor('during_world_cup_2014', mode='additive')
prophet.add_regressor('after_world_cup_2014', mode='additive')
prophet.add_regressor('during_world_cup_2018', mode='additive')
prophet.add_regressor('after_world_cup_2018', mode='additive')prophet.fit(df)
future = prophet.make_future_dataframe(periods=365)future['during_world_cup_2014'] = 0
future.loc[(future['ds'] >= pd.to_datetime('2014-05-02')) & (future['ds'] <= pd.to_datetime('2014-08-25')), 'during_world_cup_2014'] = 1
future['after_world_cup_2014'] = 0
future.loc[(future['ds'] >= pd.to_datetime('2014-08-25')), 'after_world_cup_2014'] = 1future['during_world_cup_2018'] = 0
future.loc[(future['ds'] >= pd.to_datetime('2018-06-04')) & (future['ds'] <= pd.to_datetime('2018-07-03')), 'during_world_cup_2018'] = 1
future['after_world_cup_2018'] = 0
future.loc[(future['ds'] >= pd.to_datetime('2018-07-03')), 'after_world_cup_2018'] = 1forecast = prophet.predict(future)
fig = prophet.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), prophet, forecast)
plt.show()
fig2 = prophet.plot_components(forecast)
plt.show()
 Nombre de likes par photo de James Rodríguez avec ajout de variables explicatives externes
Nombre de likes par photo de James Rodríguez avec ajout de variables explicatives externes
Regardez cette ligne bleue. La ligne rouge montre uniquement les tendances et est exclue des effets des variables externes supplémentaires et des jours fériés. Voyez comment la ligne de tendance bleue s'envole pendant la Coupe du monde. C'est exactement ce que notre savoir-faire enseigne! Lorsque Rodríguez a marqué son premier but à la Coupe du monde, des milliers de followers se sont soudainement rassemblés sur son compte. Vous pouvez voir l'effet concret de ces variables explicatives externes en regardant le graphique des composants.
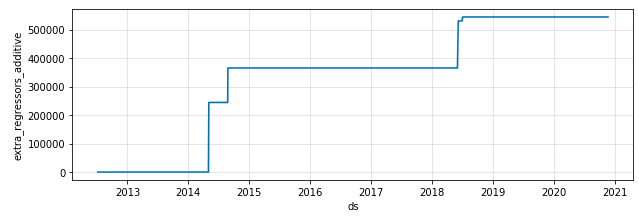 Graphique des composants des variables explicatives externes de la Coupe du monde de James Rodríguez
Graphique des composants des variables explicatives externes de la Coupe du monde de James Rodríguez
Cela montre que la Coupe du monde n'a eu aucun effet sur le nombre de likes sur les photos de Rodríguez de 2013 à début 2014. Lors de la Coupe du monde 2014, ses moyennes ont considérablement augmenté, comme le montre l'image, qui s'est poursuivie après le tournoi (auquel il a eu tant de followers actifs lors de cet événement). Je peux expliquer à partir de là). Il y a eu une augmentation similaire à la Coupe du monde 2018, mais pas si dramatiquement. On peut en déduire que c'était probablement parce qu'il n'y avait plus beaucoup de fans de football à l'époque qui ne le connaissaient pas.
Merci d'avoir suivi cet article jusqu'au bout! Vous savez maintenant comment utiliser les vacances dans Prophet, comment utiliser la croissance linéaire et logistique, et comment utiliser des régresseurs externes pour améliorer considérablement les prédictions de Prophet. Facebook a créé un outil incroyablement utile appelé Prophet, transformant la tâche autrefois très difficile de prédiction probabiliste en un simple ensemble de paramètres pouvant être largement ajustés. Que vos prédictions soient excellentes!
Coopération de traduction
Original Author: Greg Rafferty Thank you for letting us share your knowledge!
Cet article a été publié avec la coopération des personnes suivantes. Merci encore. Sélecteur: yumika tomita Traducteur: siho1 Auditeur: takujio Éditeur: siho1
Souhaitez-vous écrire un article avec nous?
Nous traduisons des articles de haute qualité de l'étranger vers le japonais avec la coopération de plusieurs excellents ingénieurs et publions les articles. Veuillez nous contacter si vous êtes d'accord avec nos activités ou si vous souhaitez diffuser des articles de bonne qualité à de nombreuses personnes. Veuillez envoyer un message avec le titre "Souhaite participer" dans [Mail](mailto: [email protected]), ou envoyer un message dans Twitter. Par exemple, nous pouvons vous présenter les pièces qui peuvent vous aider après la sélection.
- Nous répondrons toujours à votre message.
Nous attendons vos opinions et impressions avec impatience.
Comment était cet article? ・ J'aurais aimé faire ça, je veux que tu fasses plus, je pense que ce serait mieux ・ Ce genre d'endroit était bon Nous recherchons des opinions franches telles que. N'hésitez pas à publier vos commentaires dans la section commentaires car nous utiliserons vos commentaires pour améliorer la qualité des prochains articles. Nous apprécions également vos commentaires sur Twitter. Nous attendons votre message avec impatience.
Recommended Posts