Asynchronous processing in Python: asyncio reverse lookup reference
There weren't many practical examples of Python's asyncio and async / await, so I created an example-based reverse lookup based on the information I collected. However, there is a mystery about what is true because there is really no information in this area, so if you have any information, please feel free to contact us.
The examples introduced this time are summarized in the following gist. I hope you can refer to it when implementing it.
icoxfog417/asyncio_examples.py
Introduction
Python has three packages that could be used for parallel processing: threading, multiprocessing, and ʻasyncio`. First of all, let's take a look at these differences.
The difference between these packages is directly equivalent to the difference between "multithreaded", "multiprocessed" and "non-blocking". First, the difference between multithreading and multiprocessing.
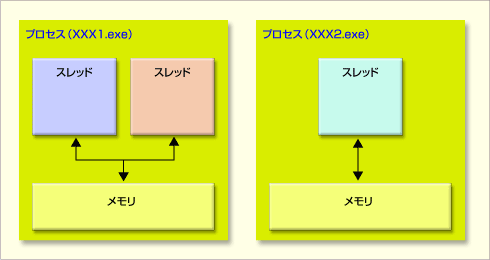 1st multi-thread is used in such cases (1/2)
1st multi-thread is used in such cases (1/2)
A process is a processing unit with its own memory, and in the case of a so-called multi-core CPU, this process can be assigned to each core and can be processed efficiently (although it is not impossible to create more processes than the number of cores). It becomes inefficient). A thread is a processing unit within a process, and threads between the same processes share memory.
Non-blocking was born as a way to overcome the weaknesses of multithreading. There is a difference in the method of handling a large number of requests (Reference: Introduction to Node.js).
- Multi-thread: Create threads for each request-> If there are many requests, it will be difficult (C10K problem)
- Non-blocking: Handle multiple requests in one thread
- If you handle a certain request so far, move on to processing other requests, and when it is finished, process it as if it were the original ...
Therefore, multithreading and nonblocking cannot live together because they handle threads differently, but both can be combined with multiprocessing (in theory).
Asyncio and async / await handled this time are functions for implementing non-blocking processing. Please keep this point in mind first.
Basic: How to write non-blocking process
First, I will introduce how to write non-blocking processing using asyncio as a basis. In addition, this non-blocking processing is effective and applicable in the following cases.
- There is heavy processing that becomes a bottleneck
- The process occurs in large numbers
- The order in which the processes are completed does not matter
Specifically, I think that page acquisition from url and data acquisition from DB are applicable, but please note that "the order of completion of processing does not matter".
The following is a simple example (extracted from the first example).
import asyncio
Seconds = [
("first", 5),
("second", 0),
("third", 3)
]
async def sleeping(order, seconds, hook=None):
await asyncio.sleep(seconds)
if hook:
hook(order)
return order
async def basic_async():
# the order of result is nonsequential (not depends on order, even sleeping time)
for s in Seconds:
r = await sleeping(*s)
print("{0} is finished.".format(r))
return True
if __name__ == "__main__":
loop = asyncio.get_event_loop()
loop.run_until_complete(basic_async())
The core of the process is basic_async. Here, the process called sleeping (in the image, this corresponds to the process of" heavy but the processing order does not matter ") is repeated.
The event loop generated by loop = asyncio.get_event_loop () is responsible for executing the process, and this is the "non-blocking thread". Basically, pass a function (asyncio.coroutine) that is ʻasync here and let it process (loop.run_until_complete (basic_async ()) `).
Looking at r = await sleeping (* s), we are waiting for ʻawait` to finish the process. Looking at this alone, I feel that it is the same as a normal for statement because it waits for the processing to finish every time, and in fact it is so in this example. As you can see by running it, the results are always in the following order:
first is finished.
second is finished.
third is finished.
Isn't it asynchronous! However, this ʻawait actually works when processing in parallel as introduced below. When ʻawait is done, something heavy starts, so when you reach this point, the thread starts "other things in the event loop". Then, when the processing performed by ʻawait` is completed, it returns to the task and continues the processing.
Therefore, if you process them in parallel as shown below, you can see that each task is being performed (be careful when executing the script below as it does not end as indicated by run_forever).
async def basic_async(num):
# the order of result is nonsequential (not depends on order, even sleeping time)
for s in Seconds:
r = await sleeping(*s)
print("{0}'s {1} is finished.".format(num, r))
return True
if __name__ == "__main__":
loop = asyncio.get_event_loop()
# make two tasks in event loop
asyncio.ensure_future(basic_async(1))
asyncio.ensure_future(basic_async(2))
loop.run_forever()
If you look at the execution result, you can see that when 1 is executed and ʻawait is reached, 2 is started, when 1 returns from ʻawait, it returns to 1 and continues, and so on. ..
1's first is finished.
2's first is finished.
1's second is finished.
2's second is finished.
1's third is finished.
2's third is finished.
So if there is only one coroutine in the event loop, async / await will have no effect. This is important and needs to be remembered.
At the end of the basics, let's sort out the confusing objects around asyncio.
coroutine: The return value of the async function will becoroutine- ʻAsync def hoge (): If you have a function called xxx
,hoge ()will be acoroutine` object instead of an immediate return. Future: Deferred object in jQuery- Execution results can be propagated using
set_resultandset_exception Task- A subclass of
Futurethat manages execution. I don't make it directly (or rather, I shouldn't make it), so I don't really care about it.
It actually deals with coroutine or Future, and most functions support both. coroutine can be converted to Task with ʻasyncio.ensure_future ([ create_task`](http://docs.python.jp/3/library/asyncio-eventloop.html#asyncio.BaseEventLoop. There is also a method called create_task) that can be a Task, but there is basically no difference between these two methods (http://stackoverflow.com/questions/33980086/whats-the-difference-between-loop) -create-task-asyncio-async-ensure-future-and)).
Now, let's see how to actually handle multiple tasks in the event loop.
I want to process in parallel (fixed length)
If the number of processes you want to execute in parallel is decided in advance, you can process them all at once in parallel. The features provided for this are ʻasyncio.gather and ʻasyncio.wait.
First, the pattern of ʻasyncio.gather`
async def parallel_by_gather():
# execute by parallel
def notify(order):
print(order + " has just finished.")
cors = [sleeping(s[0], s[1], hook=notify) for s in Seconds]
results = await asyncio.gather(*cors)
return results
if __name__ == "__main__":
loop = asyncio.get_event_loop()
results = loop.run_until_complete(parallel_by_gather())
for r in results:
print("asyncio.gather result: {0}".format(r))
This ʻasyncio.gather` has an indefinite order of execution as usual, but it has the nice property that it returns the processed results in the order in which they were passed (here. See jp / 3 / library / asyncio-task.html # asyncio.gather). This is useful when you want to keep the order of the original array in the execution result while performing asynchronous processing.
- When using the Dictionary system, please note that the order of the Dictionary itself is indefinite (I got stuck). In the case of Dictionary, it is not guaranteed that the keys will appear in the order of definition.
The other is to use ʻasyncio.wait`.
async def parallel_by_wait():
# execute by parallel
def notify(order):
print(order + " has just finished.")
cors = [sleeping(s[0], s[1], hook=notify) for s in Seconds]
done, pending = await asyncio.wait(cors)
return done, pending
if __name__ == "__main__":
loop = asyncio.get_event_loop()
done, pending = loop.run_until_complete(parallel_by_wait())
for d in done:
dr = d.result()
print("asyncio.wait result: {0}".format(dr))
The result of wait is returned with done and pending. Note that when retrieving the result, you need to retrieve it with result () (if an exception occurs during processing, the exception will be thrown when result () is executed).
I want to process in parallel (indefinite length)
I knew the number of parallel processes to be performed earlier, but the length may not be fixed (stream, etc.) when requests come one after another.
In such a case, processing using Queue is possible.
async def queue_execution(arg_urls, callback, parallel=2):
loop = asyncio.get_event_loop()
queue = asyncio.Queue()
for u in arg_urls:
queue.put_nowait(u)
async def fetch(q):
while not q.empty():
u = await q.get()
future = loop.run_in_executor(None, requests.get, u)
future.add_done_callback(callback)
await future
tasks = [fetch(queue) for i in range(parallel)]
return await asyncio.wait(tasks)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
results = []
def store_result(f):
results.append(f.result())
loop.run_until_complete(queue_execution([
"http://www.google.com",
"http://www.yahoo.com",
"https://github.com/"
], store_result))
for r in results:
print("queue execution: {0}".format(r.url))
This is a fixed length and passes an array of urls, so I don't use Queue very much ... As a point, create a queue with ʻasyncio.Queue and put the processing target in it with put_nowait(when fixing the size of the queue, useput` to create a queue. You can block until it's free).
ʻAsync def fetch will continue to process unless the queueis empty. This time, we are runningfetch in parallel for the number of parallel, so it looks like one queue is shared by two coroutine`s.
Note that getting the Python url (ʻurllib.request.urlopen) will block the process, so [here](http://stackoverflow.com/questions/22190403/how-could-i-use-requests- I tried to implement it with reference to in-asyncio), but it didn't run in parallel (probably I have to do ʻawait after finishing all the run_in_executors?). If you want to get in parallel, it is safer to use ʻaiohttp`.
However, as shown in loop.run_in_executor (None, requests.get, u), you can [Future] ordinary functions by using run_in_executor [http://docs.python.jp/3/". library / asyncio-eventloop.html # asyncio.BaseEventLoop.run_in_executor) can be used as a technique in other cases as well.
I want to control the number of executions in parallel
Especially when scraping, processing the urls of 1000 contents in a certain site all at once causes a lot of trouble, so you may want to control the number of processes executed in parallel.
At this time, use Semaphore.
async def limited_parallel(limit=3):
sem = asyncio.Semaphore(limit)
# function want to limit the number of parallel
async def limited_sleep(num):
with await sem:
return await sleeping(str(num), num)
import random
tasks = [limited_sleep(random.randint(0, 3)) for i in range(9)]
return await asyncio.wait(tasks)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
done, pending = loop.run_until_complete(limited_parallel())
for d in done:
print("limited parallel: {0}".format(d.result()))
It's easy to use, just wait for Semaphore to be available by with await sem in the async function you want to control the number of concurrent executions.
I want to perform callback processing after asynchronous processing is completed
If you want to perform a specific process after the process is completed, you can use ʻadd_done_callback in ʻasyncio.Future. In the following, coroutine is converted to Task by ʻasyncio.ensure_future` and the received callback is added.
async def future_callback(callback):
futures = []
for s in Seconds:
cor = sleeping(*s)
f = asyncio.ensure_future(cor)
f.add_done_callback(callback)
futures.append(f)
await asyncio.wait(futures)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
results = []
def store_result(f):
results.append(f.result())
loop.run_until_complete(future_callback(store_result))
for r in results:
print("future callback: {0}".format(r))
If you want to do it, I think you can add more Futures to the callback, but I think it's a complicated mystery and should be stopped (I wasted a few hours of precious vacation).
I want to create an Iterator that processes asynchronously
If you want to stream processing without blocking while being an Iterator, such as sequential reading from a database, you can create your own Iterator.
def get_async_iterator(arg_urls):
class AsyncIterator():
def __init__(self, urls):
self.urls = iter(urls)
self.__loop = None
def __aiter__(self):
self.__loop = asyncio.get_event_loop()
return self
async def __anext__(self):
try:
u = next(self.urls)
future = self.__loop.run_in_executor(None, requests.get, u)
resp = await future
except StopIteration:
raise StopAsyncIteration
return resp
return AsyncIterator(arg_urls)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
async def async_fetch(urls):
ai = get_async_iterator(urls)
async for resp in ai:
print(resp.url)
loop.run_until_complete(async_fetch([
"http://www.google.com",
"http://www.yahoo.com",
"https://github.com/"
]))
The points are __aiter__ and __anext__, which are the async versions of regular Iterator. You can use ʻawait in ʻanext. Please note that when using it, iterate with ʻasync for resp in ai and ʻasync for.
I want to perform non-blocking processing in multiple processes (unconfirmed)
At the very beginning, I said that multi-process and non-blocking can live together (in theory), but here's how to do that? I don't know the exact point because it is a mystery how to check if it is multi-process + non-blocking, but I will post it for the time being.
import asyncio
import concurrent.futures
loop = asyncio.get_event_loop()
executor = concurrent.futures.ProcessPoolExecutor()
loop.set_default_executor(executor)
Source
- Cleanly shutdown the IO loop when using an executor
- How to properly create and run concurrent tasks using python's asyncio module?
Default ʻexecutor` uses ThreadPoolExecutor, so I will change this to ProcessPoolExecutor. As a result, non-blocking processing will probably be performed on a process-by-process basis, and as with multiprocessing, you can benefit from parallel processing by distributing only the CPU cores.
However, conversely, it is not efficient for a process to duplicate more than the number of CPU cores, and it is not suitable when you want to acquire many URLs in parallel (this is more suitable for threads). I think you should use it properly according to the situation. If you are afraid to set it to the default, you may use it only when executing a specific function with run_in_executor. I think.
The following is a Process version of the Queue example (I think this works best). The print_num is out because an error occurred if it wasn't a global function (are you using pickle when duplicating the Process?).
def print_num(num):
print(num)
async def async_by_process():
executor = concurrent.futures.ProcessPoolExecutor()
queue = asyncio.Queue()
for i in range(10):
queue.put_nowait(i)
async def proc(q):
while not q.empty():
i = await q.get()
future = loop.run_in_executor(executor, print_num, i)
await future
tasks = [proc(queue) for i in range(4)] # 4 = number of cpu core
return await asyncio.wait(tasks)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
loop.run_until_complete(async_by_process())
The above is a summary of Python's asyncio.
Recommended Posts