This is a training to become a data scientist using Python.
Finally, let's do one of the three sacred treasures, Pandas.
Pandas is Python's most powerful data analysis package.
It's very convenient because you can do anything you can do with Excel. (You can do things that Excel can't do)
It goes well with numpy and matplotlib and can be used seamlessly.
I think it's best to use the IPython Notebook described below to run Python programs using Pandas.
** PREV ** → [Python] Road to snake charmer (5) Play with Matplotlib
** NEXT ** → Pandas application (as soon as possible)
It visualizes DataFrames and graphs beautifully like this. amazing.
Pandas data structure
Pandas has three data structures.
--One-dimensional array: Series
--Two-dimensional array: DataFrame
--Three-dimensional array: Panel
Let's generate these from a Numpy array.
Series example (1D)
Python
import numpy as np
import pandas as pd
Python
# Series
a1 = np.arange(2)
idx = pd.Index(['A', 'B'], name = 'index')
series = pd.Series(a1, index=idx)
series
index
A 0
B 1
dtype: int64
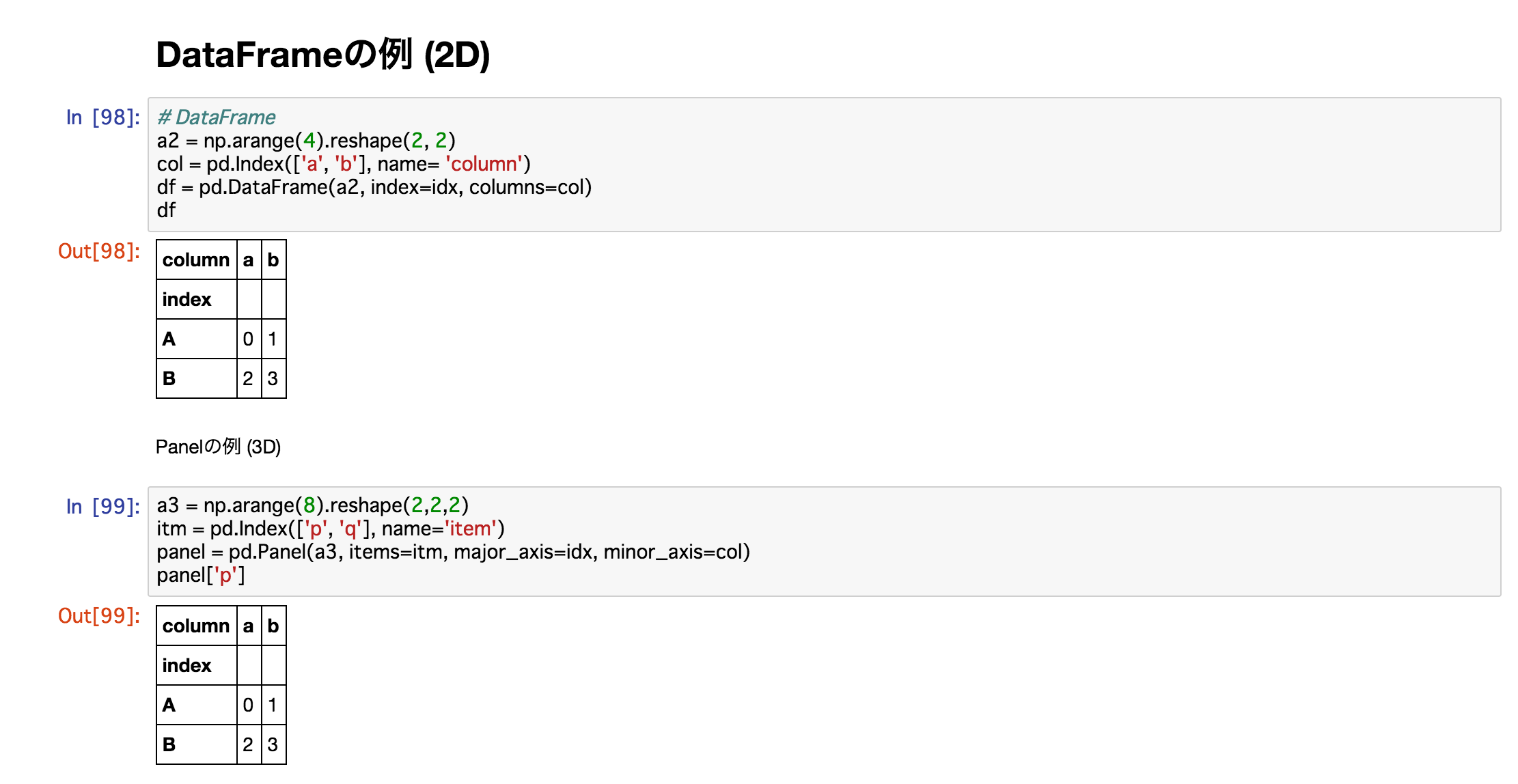
DataFrame example (2D)
Python
# DataFrame
a2 = np.arange(4).reshape(2, 2)
col = pd.Index(['a', 'b'], name= 'column')
df = pd.DataFrame(a2, index=idx, columns=col)
df
| column |
a |
b |
| index |
|
|
| A |
0 |
1 |
| B |
2 |
3 |
Panel example (3D)
Python
a3 = np.arange(8).reshape(2,2,2)
itm = pd.Index(['p', 'q'], name='item')
panel = pd.Panel(a3, items=itm, major_axis=idx, minor_axis=col)
panel['p']
| column |
a |
b |
| index |
|
|
| A |
0 |
1 |
| B |
2 |
3 |
Python
panel['q']
| column |
a |
b |
| index |
|
|
| A |
4 |
5 |
| B |
6 |
7 |
Example of Series with double index (effectively 2D)
Python
a1=np.arange(4)
idx = pd.MultiIndex.from_product([['A','B'],['a','b']], names=('i','j'))
series2 = pd.Series(a1, index=idx)
series2
#From even if the axis multiplicity is 3 or more_product can be used.
# pd.MultiIndex.from_product([['A', 'B'],['a', 'b'],['1', '2']], names=('i', 'j', 'k'))
i j
A a 0
b 1
B a 2
b 3
dtype: int64
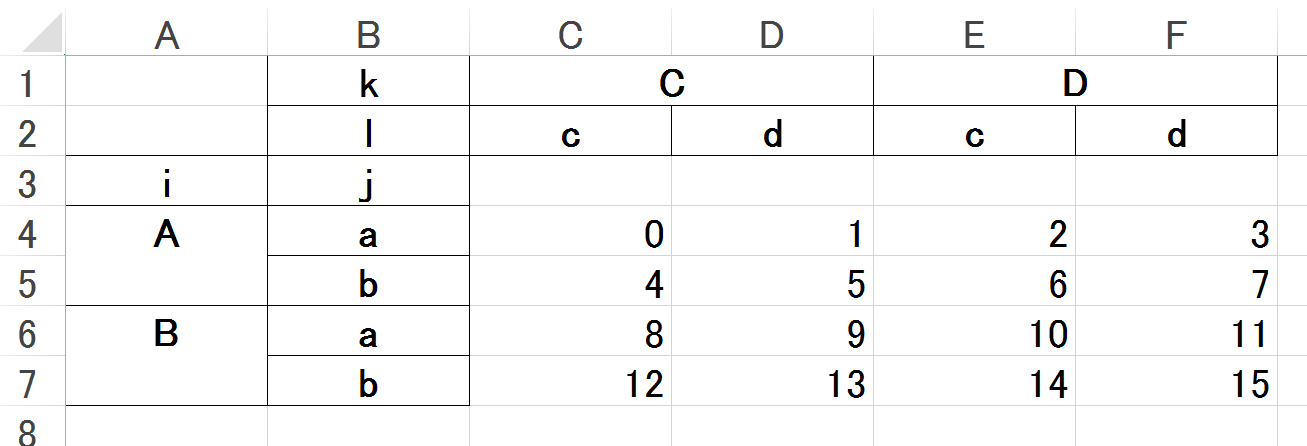
Example of DataFrame with double index (effectively 4D)
Python
a2 = np.arange(16) .reshape(4,4)
idx = pd.MultiIndex.from_product( [['A','B'],['a','b']], names=('i','j'))
col = pd.MultiIndex.from_product( [['C','D'],['c','d']], names=('k','l'))
df = pd.DataFrame(a2, index=idx, columns=col)
df
|
k |
C |
D |
|
l |
c |
d |
c |
d |
| i |
j |
|
|
|
|
| A |
a |
0 |
1 |
2 |
3 |
| b |
4 |
5 |
6 |
7 |
| B |
a |
8 |
9 |
10 |
11 |
| b |
12 |
13 |
14 |
15 |
Although omitted this time, Panel can also have multiple indexes in the same way.
How to access data (Indexing)
The big difference between Pandas and Numpy is that Numpy's index concept is more sophisticated in Pandas.
Let's compare the 2D array from earlier with Numpy and Pandas DataFrame.
Python
a2 = np.arange(4).reshape(2, 2)
a2
array([[0, 1],
[2, 3]])
Python
idx = pd.Index(['A', 'B'], name='index')
col = pd.Index(['a', 'b'], name='column')
df = pd.DataFrame(a2, index=idx, columns=col)
df
| column |
a |
b |
| index |
|
|
| A |
0 |
1 |
| B |
2 |
3 |
The rows are labeled A and B, and the columns are labeled a and b, respectively, which Pandas can use as an index.
This is called the ** label-based index **.
On the other hand, the 0-based integer index used in Numpy is called the ** position-based index **.
Both are available in Pandas.
Python
a2[1, 1]
3
Python
df.ix[1, 1]
3
Python
df.ix['B', 'b']
3
Since ** label-based index ** is the key of dict and ** position-based index ** is the index of list, you can think of Pandas as having both dict and list properties. I can do it.
So, of course, slice, fancy indexing, and boolean indexing are possible as well as Numpy.
slice
Python
df = pd.DataFrame( np.arange(16).reshape(4, 4), index=list('ABCD'),columns=list('abcd'))
df
|
a |
b |
c |
d |
| A |
0 |
1 |
2 |
3 |
| B |
4 |
5 |
6 |
7 |
| C |
8 |
9 |
10 |
11 |
| D |
12 |
13 |
14 |
15 |
Python
#First line and above,Less than 3rd line
df.ix[1:3]
|
a |
b |
c |
d |
| B |
4 |
5 |
6 |
7 |
| C |
8 |
9 |
10 |
11 |
Python
#Line A and above,Line C and below
# label-For based index, not less than
df.ix['A' : 'C']
|
a |
b |
c |
d |
| A |
0 |
1 |
2 |
3 |
| B |
4 |
5 |
6 |
7 |
| C |
8 |
9 |
10 |
11 |
fancy indexing
Python
#Specify multiple lines
df.ix[['A', 'B', 'D']]
|
a |
b |
c |
d |
| A |
0 |
1 |
2 |
3 |
| B |
4 |
5 |
6 |
7 |
| D |
12 |
13 |
14 |
15 |
Python
#Specify multiple columns
df[[ 'b', 'd']]
|
b |
d |
| A |
1 |
3 |
| B |
5 |
7 |
| C |
9 |
11 |
| D |
13 |
15 |
boolean indexing
Python
#See line that is True
df.ix[[True, False, True]]
|
a |
b |
c |
d |
| A |
0 |
1 |
2 |
3 |
| C |
8 |
9 |
10 |
11 |
Python
#See column that is True
df.ix[:,[True, False, True]]
|
a |
c |
| A |
0 |
2 |
| B |
4 |
6 |
| C |
8 |
10 |
| D |
12 |
14 |
Python
#See a row where twice the a value is greater than the c value
df.ix[df['a']*2 > df['c']]
|
a |
b |
c |
d |
| B |
4 |
5 |
6 |
7 |
| C |
8 |
9 |
10 |
11 |
| D |
12 |
13 |
14 |
15 |
Axis and index manipulation
Introducing axis swapping, moving, index renaming, index sorting, etc. that are important for using Pandas.
Swap axes
Python
a2 = np.arange(4) .reshape(2, 2)
idx = pd.Index(['A', 'B'], name='index')
col = pd.Index(['a', 'b'], name='column')
df = pd.DataFrame(a2, index=idx,columns=col)
df
| column |
a |
b |
| index |
|
|
| A |
0 |
1 |
| B |
2 |
3 |
Python
#Axis 0(line)And the first axis(Column)To replace
df.swapaxes(0, 1)
| index |
A |
B |
| column |
|
|
| a |
0 |
2 |
| b |
1 |
3 |
Python
#Transpose in 2D(T)Even if it is the same
df.T # transpose()Abbreviation for
| index |
A |
B |
| column |
|
|
| a |
0 |
2 |
| b |
1 |
3 |
Axis movement (stack / unstack)
Python
#Column moved to row side
df.stack()
index column
A a 0
b 1
B a 2
b 3
dtype: int64
Python
#Row moves to column side
df.unstack()
column index
a A 0
B 2
b A 1
B 3
dtype: int64
Python
#stack()And unstack()Is the reverse operation, so if you repeat these two operations, it will return to the original
df.stack().unstack()
| column |
a |
b |
| index |
|
|
| A |
0 |
1 |
| B |
2 |
3 |
When the row moves to the column side, the column is represented by a double index.
If you stack () or unstack () a (non-multiplexed) DataFrame, the output will be Series.
Swap axes
Python
a2 = np.arange(64).reshape(8,8)
idx = pd.MultiIndex.from_product( [['A','B'],['C','D'],['E','F']],names=list('ijk'))
col = pd.MultiIndex.from_product([['a','b'],['c','d'],['e','f']],names=list('xyz'))
df = pd.DataFrame(a2, index=idx,columns=col)
df
|
|
x |
a |
b |
|
|
y |
c |
d |
c |
d |
|
|
z |
e |
f |
e |
f |
e |
f |
e |
f |
| i |
j |
k |
|
|
|
|
|
|
|
|
| A |
C |
E |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| F |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
| D |
E |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
| F |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
| B |
C |
E |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
| F |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
| D |
E |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
| F |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
This is an example where each axis has 3 layers (3 layers), but swapaxes () replaces all layers entirely.
Python
df.swapaxes(0,1)
|
|
i |
A |
B |
|
|
j |
C |
D |
C |
D |
|
|
k |
E |
F |
E |
F |
E |
F |
E |
F |
| x |
y |
z |
|
|
|
|
|
|
|
|
| a |
c |
e |
0 |
8 |
16 |
24 |
32 |
40 |
48 |
56 |
| f |
1 |
9 |
17 |
25 |
33 |
41 |
49 |
57 |
| d |
e |
2 |
10 |
18 |
26 |
34 |
42 |
50 |
58 |
| f |
3 |
11 |
19 |
27 |
35 |
43 |
51 |
59 |
| b |
c |
e |
4 |
12 |
20 |
28 |
36 |
44 |
52 |
60 |
| f |
5 |
13 |
21 |
29 |
37 |
45 |
53 |
61 |
| d |
e |
6 |
14 |
22 |
30 |
38 |
46 |
54 |
62 |
| f |
7 |
15 |
23 |
31 |
39 |
47 |
55 |
63 |
Swapping multiple axes (swaplevel / reorder_levels)
Python
#Axis 0(line)Of the 0th layer(i)And the second level(z)Swap
df.reorder_levels([2, 1, 0])
# swaplevel(0, 2)Or swaplevel('i', 'z')But the same
|
|
x |
a |
b |
|
|
y |
c |
d |
c |
d |
|
|
z |
e |
f |
e |
f |
e |
f |
e |
f |
| k |
j |
i |
|
|
|
|
|
|
|
|
| E |
C |
A |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| F |
C |
A |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
| E |
D |
A |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
| F |
D |
A |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
| E |
C |
B |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
| F |
C |
B |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
| E |
D |
B |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
| F |
D |
B |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
Python
#1st axis(Column)Of the 0th layer(x)And the first level(y)Swap
df.reorder_levels([1,0,2],axis=1)
# swaplevel(0, 1, axis=1)Or swaplevel('i', 'j', axis=1)But the same
|
|
y |
c |
d |
c |
d |
|
|
x |
a |
a |
b |
b |
|
|
z |
e |
f |
e |
f |
e |
f |
e |
f |
| i |
j |
k |
|
|
|
|
|
|
|
|
| A |
C |
E |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| F |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
| D |
E |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
| F |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
| B |
C |
E |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
| F |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
| D |
E |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
| F |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
Multi-axis movement (stack / unstack)
stack () moves the bottom level axis of the column axis to the bottom level axis of the row axis.
Python
df.stack()
|
|
|
x |
a |
b |
|
|
|
y |
c |
d |
c |
d |
| i |
j |
k |
z |
|
|
|
|
| A |
C |
E |
e |
0 |
2 |
4 |
6 |
| f |
1 |
3 |
5 |
7 |
| F |
e |
8 |
10 |
12 |
14 |
| f |
9 |
11 |
13 |
15 |
| D |
E |
e |
16 |
18 |
20 |
22 |
| f |
17 |
19 |
21 |
23 |
| F |
e |
24 |
26 |
28 |
30 |
| f |
25 |
27 |
29 |
31 |
| B |
C |
E |
e |
32 |
34 |
36 |
38 |
| f |
33 |
35 |
37 |
39 |
| F |
e |
40 |
42 |
44 |
46 |
| f |
41 |
43 |
45 |
47 |
| D |
E |
e |
48 |
50 |
52 |
54 |
| f |
49 |
51 |
53 |
55 |
| F |
e |
56 |
58 |
60 |
62 |
| f |
57 |
59 |
61 |
63 |
unstack () moves the bottom level axis of the row axis to the bottom level axis of the column axis.
Python
df.unstack()
|
x |
a |
b |
|
y |
c |
d |
c |
d |
|
z |
e |
f |
e |
f |
e |
f |
e |
f |
|
k |
E |
F |
E |
F |
E |
F |
E |
F |
E |
F |
E |
F |
E |
F |
E |
F |
| i |
j |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| A |
C |
0 |
8 |
1 |
9 |
2 |
10 |
3 |
11 |
4 |
12 |
5 |
13 |
6 |
14 |
7 |
15 |
| D |
16 |
24 |
17 |
25 |
18 |
26 |
19 |
27 |
20 |
28 |
21 |
29 |
22 |
30 |
23 |
31 |
| B |
C |
32 |
40 |
33 |
41 |
34 |
42 |
35 |
43 |
36 |
44 |
37 |
45 |
38 |
46 |
39 |
47 |
| D |
48 |
56 |
49 |
57 |
50 |
58 |
51 |
59 |
52 |
60 |
53 |
61 |
54 |
62 |
55 |
63 |
index rename
Python
df = pd.DataFrame( [[90, 50], [60, 80]], index=['t', 'h'],columns=['m', 'e'])
df
Python
df.index.name='name'
df.columns.name='Subject'
df.rename(index=dict(t='Taro', h='Hanako'), columns=dict(m='Math', e='English'))
| Subjects
| Mathematics
| English
|
| name
| |
|
| Taro
| 90 |
50 |
| Hanako
| 60 |
80 |
Sort by index
Python
df = pd.DataFrame (np.arange(9).reshape(3,3), index=['B','A','C'], columns=['c','b','a'])
df
|
c |
b |
a |
| B |
0 |
1 |
2 |
| A |
3 |
4 |
5 |
| C |
6 |
7 |
8 |
Python
#Sort rows by row index
df.sort_index(axis=0)
|
c |
b |
a |
| A |
3 |
4 |
5 |
| B |
0 |
1 |
2 |
| C |
6 |
7 |
8 |
Python
#Sort columns by column index
df.sort_index(axis=0).sort_index(axis=1)
|
a |
b |
c |
| A |
5 |
4 |
3 |
| B |
2 |
1 |
0 |
| C |
8 |
7 |
6 |
Data conversion
Series data conversion
Python
series=pd.Series([2, 3], index=list('ab'))
series
a 2
b 3
dtype: int64
Python
#Square each value in Series
series ** 2
a 4
b 9
dtype: int64
Python
#You can also pass functions and dicts on the map
series.map(lambda x: x**2)
# series.map( {x:x**2 for x in range(3) })
a 4
b 9
dtype: int64
DataFrame data conversion
Python
df = pd.DataFrame( [[2, 3], [4, 5]], index=list('AB'),columns=list('ab'))
df
Python
#Similar to Series
df ** 2
# df.map(lambda x: x**2)
Python
#function(Series to scalar)Apply to each column
#One dimension down, the result is Series
df.apply(lambda c: c['A']*c['B'], axis=0)
a 8
b 15
dtype: int64
Python
#function(Series to Series)Apply to each line
#The result is a DataFrame
df.apply(lambda r: pd.Series(dict(a=r['a']+r['b'], b=r['a']*r['b'])), axis=1)
Concat and merge
Pandas allows you to concatenate and combine multiple Series and DataFrames.
Series concat (concat)
Even if there are duplicate indexes, they will be combined as they are.
Python
ser1=pd.Series([1,2], index=list('ab'))
ser2=pd.Series([3,4], index=list('bc'))
pd.concat([ser1, ser2])
a 1
b 2
b 3
c 4
dtype: int64
Python
#When making the index unique, remove duplicate inex
dif_idx = ser2.index.difference(ser1.index)
pd.concat([ser1, ser2[list(dif_idx)]])
a 1
b 2
c 4
dtype: int64
DataFrame concat (concat)
Python
df1 = pd.DataFrame([[1, 2], [3, 4]], index=list('AB'),columns=list('ab'))
df2 = pd.DataFrame([[5, 6], [7, 8]], index=list('CD'),columns=list('ab'))
df3 = pd.DataFrame([[5, 6], [7, 8]], index=list('AB'),columns=list('cd'))
Python
df1
Python
df2
Python
df3
Python
#0th axis(line)Stack in the direction
pd.concat([df1, df2], axis=0)
|
a |
b |
| A |
1 |
2 |
| B |
3 |
4 |
| C |
5 |
6 |
| D |
7 |
8 |
Python
#1st axis(Column)Stack in the direction
pd.concat([df1, df3], axis=1)
|
a |
b |
c |
d |
| A |
1 |
2 |
5 |
6 |
| B |
3 |
4 |
7 |
8 |
DataFrame merge
Python
df1.index.name = df3.index.name = 'A'
df10 = df1.reset_index()
df30 = df3.reset_index()
Python
df10
Python
df30
Python
#Join in column A
pd.merge(df10, df30, on='A')
|
A |
a |
b |
c |
d |
| 0 |
A |
1 |
2 |
5 |
6 |
| 1 |
B |
3 |
4 |
7 |
8 |
On is given the column name to use for the join.
Multiple specifications can be specified, in which case it is given as a list.
If omitted, the common column name of the two DataFrames is adopted.
In the above example, the common column name is only A, so it can be omitted.
Note that in merge, the index column is ignored.
Input / output of various file formats
Pandas can input and output various formats.
Python
a2 = np.arange(16) .reshape(4,4)
idx = pd.MultiIndex.from_product( [['A','B'],['a','b']], names=('i','j'))
col = pd.MultiIndex.from_product( [['C','D'],['c','d']], names=('k','l'))
df = pd.DataFrame(a2, index=idx, columns=col)
df
|
k |
C |
D |
|
l |
c |
d |
c |
d |
| i |
j |
|
|
|
|
| A |
a |
0 |
1 |
2 |
3 |
| b |
4 |
5 |
6 |
7 |
| B |
a |
8 |
9 |
10 |
11 |
| b |
12 |
13 |
14 |
15 |
Export file
Python
#Output to HTML file
df.to_html('a2.html')

Python
#Output to excel file(Requires openpyxl)
df.to_excel('a2.xlsx')
Read file
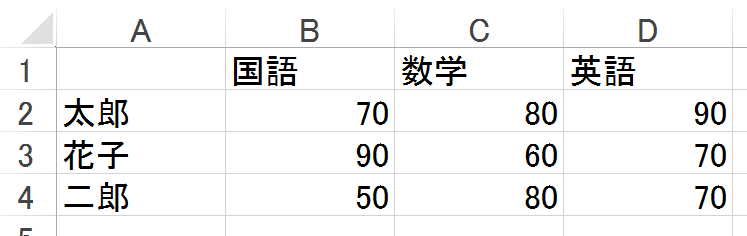
Python
xl = pd.ExcelFile('test.xlsx')
#Specifying sheet
df = xl.parse('Sheet1')
df
|
Japanese
| Mathematics
| English
|
| Taro
| 70 |
80 |
90 |
| Hanako
| 90 |
60 |
70 |
| Jiro
| 50 |
80 |
70 |
Creating a graph
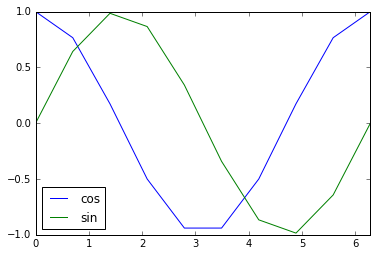
Pandas works great with Matplotlib and makes it easy to create graphs from DataFrames.
Python
%matplotlib inline
x = np.linspace(0, 2*np.pi, 10)
df = pd.DataFrame(dict(sin=np.sin(x), cos=np.cos(x)), index=x)
df
|
cos |
sin |
| 0.000000 |
1.000000 |
0.000000e+00 |
| 0.698132 |
0.766044 |
6.427876e-01 |
| 1.396263 |
0.173648 |
9.848078e-01 |
| 2.094395 |
-0.500000 |
8.660254e-01 |
| 2.792527 |
-0.939693 |
3.420201e-01 |
| 3.490659 |
-0.939693 |
-3.420201e-01 |
| 4.188790 |
-0.500000 |
-8.660254e-01 |
| 4.886922 |
0.173648 |
-9.848078e-01 |
| 5.585054 |
0.766044 |
-6.427876e-01 |
| 6.283185 |
1.000000 |
-2.449294e-16 |
Python
#Graph output
df.plot()