Extraire le tableau des fichiers image avec OneDrive et Python
Je veux extraire le tableau de l'image
Vous souhaiterez peut-être extraire la ** table dans le fichier image ** en tant que données de table.
Par exemple, «numérisez un livre papier ou un document et numérisez-le sous forme de fichier image ou PDF».
(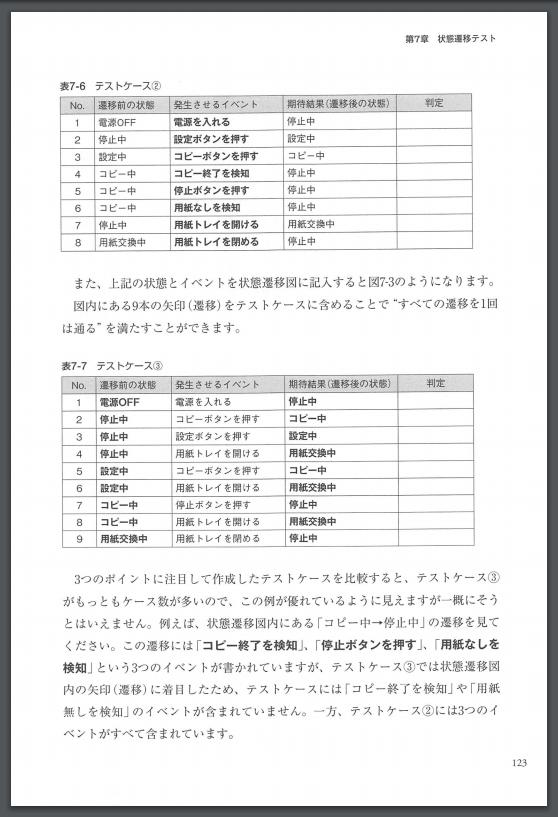
La table dans ceci n'est pas traitée par l'OCR ** juste une image **, elle n'est donc pas reconnue comme un caractère, encore moins comme une table.
Par conséquent, bien sûr, elles ne peuvent pas être traitées comme des données de table telles quelles. Alors, n'y a-t-il pas d'autre choix que d'abandonner et de tabuler régulièrement les données? Non, ** n'abandonnez pas! ** **
Comment extraire des données de table à partir d'une image
En fait, même à partir de telles images (jpg, png, pdf, etc.), le tableau peut être extrait sous forme de données à l'étape suivante.
Préparation. Créez un compte sur Microsoft OneDrive (gratuit) 0. Convertissez les fichiers image (jpg, png, etc.) en fichiers pdf (cette étape n'est pas nécessaire pour les PDF depuis le début)
- Enregistrez le fichier PDF sur OneDrive, convertissez-le en Word et appliquez le traitement OCR
- Enregistrer Word traité par OCR au format PDF
- Extraire le tableau au format PDF avec Python
J'utiliserai Word en cours de route, mais j'utiliserai Office Online gratuit pour que vous n'ayez pas besoin d'installer Microsoft Word sur votre PC.
Ensuite, cette fois, je vais vous expliquer en utilisant le fichier PDF de ↓.
(
Si vous souhaitez extraire un tableau d'un fichier image (jpg, png, etc.), convertissez-le d'abord en fichier PDF. Il existe également un service Web gratuit qui convertit les fichiers image en PDF, mais le plus simple est [Cliquez avec le bouton droit sur le fichier image-> Imprimer-> Sélectionnez "Microcoft Print to PDF" dans l'imprimante à imprimer].
Préparation. Créer un compte avec OneDrive
Enregistrez votre compte sur Microsoft OneDrive. Gratuit.
[Obtenez un compte Microsoft] (https://www.microsoft.com/ja-jp/office/homeuse/onedrive-guide.aspx)
1. Enregistrez le fichier PDF sur OneDrive
Téléchargez le fichier PDF cible sur OneDrive.
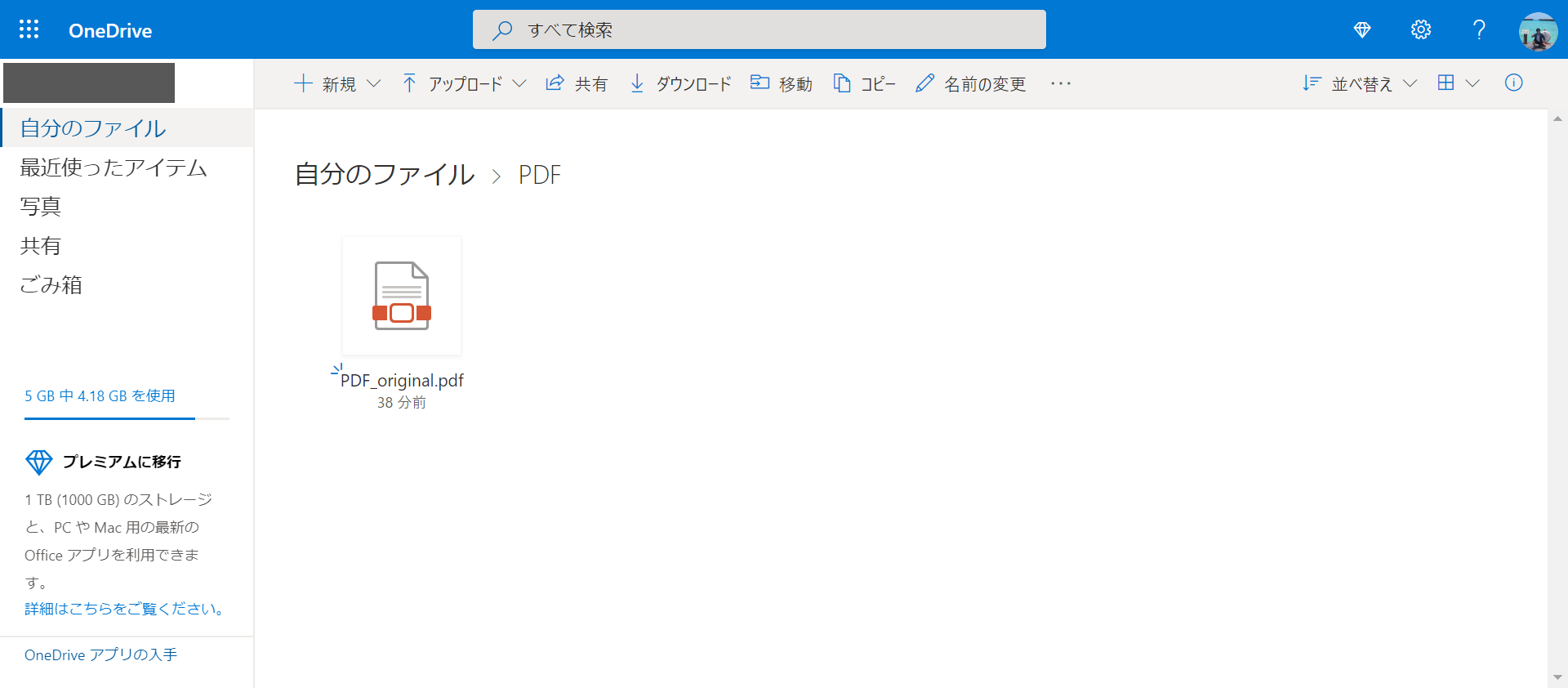
Cliquez avec le bouton droit sur le fichier et sélectionnez Ouvrir.
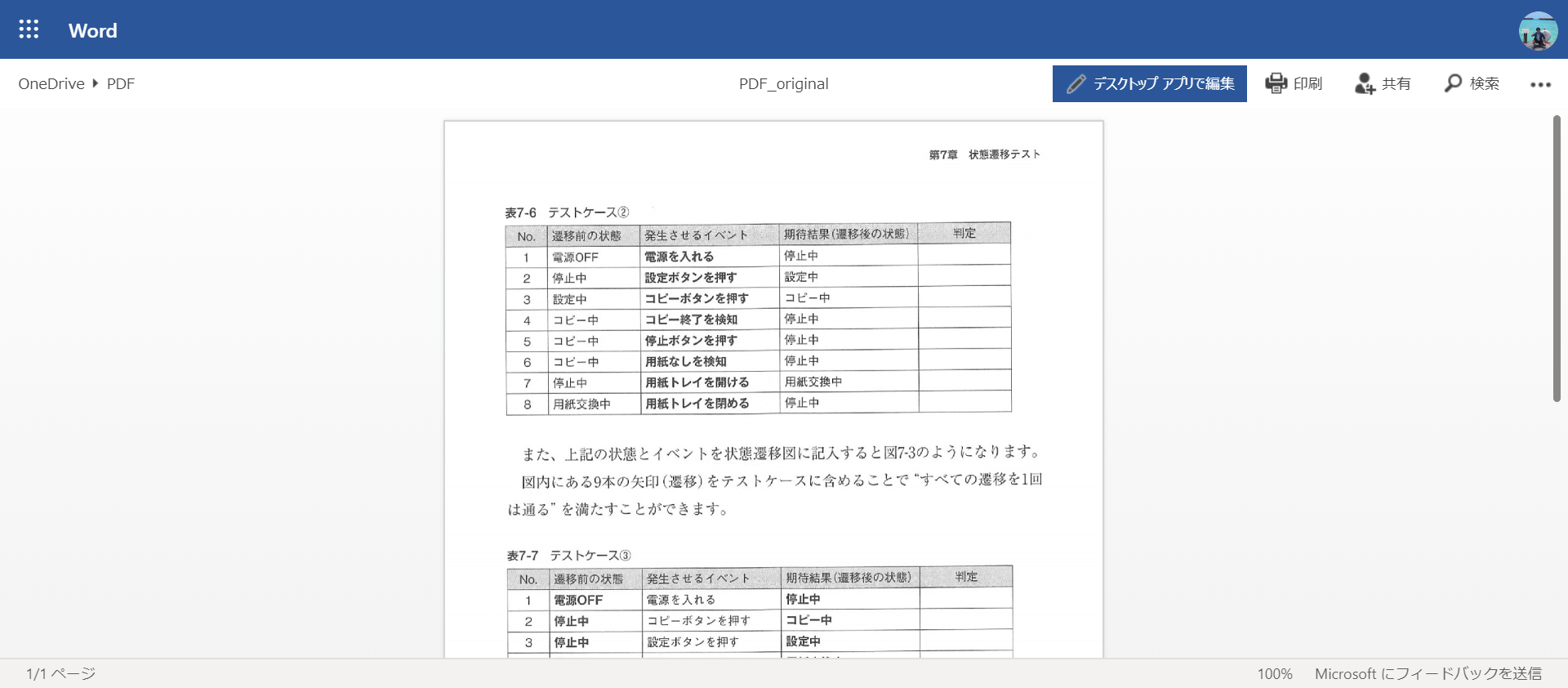
À ce stade, si vous essayez de sélectionner autour du tableau, vous pouvez sélectionner les caractères sous forme de texte. La structure de la table est également reconnue.
Appuyez sur le bouton "Modifier avec l'application de bureau". Ensuite, il vous sera demandé si vous souhaitez convertir le fichier, alors appuyez sur le bouton "Convertir".
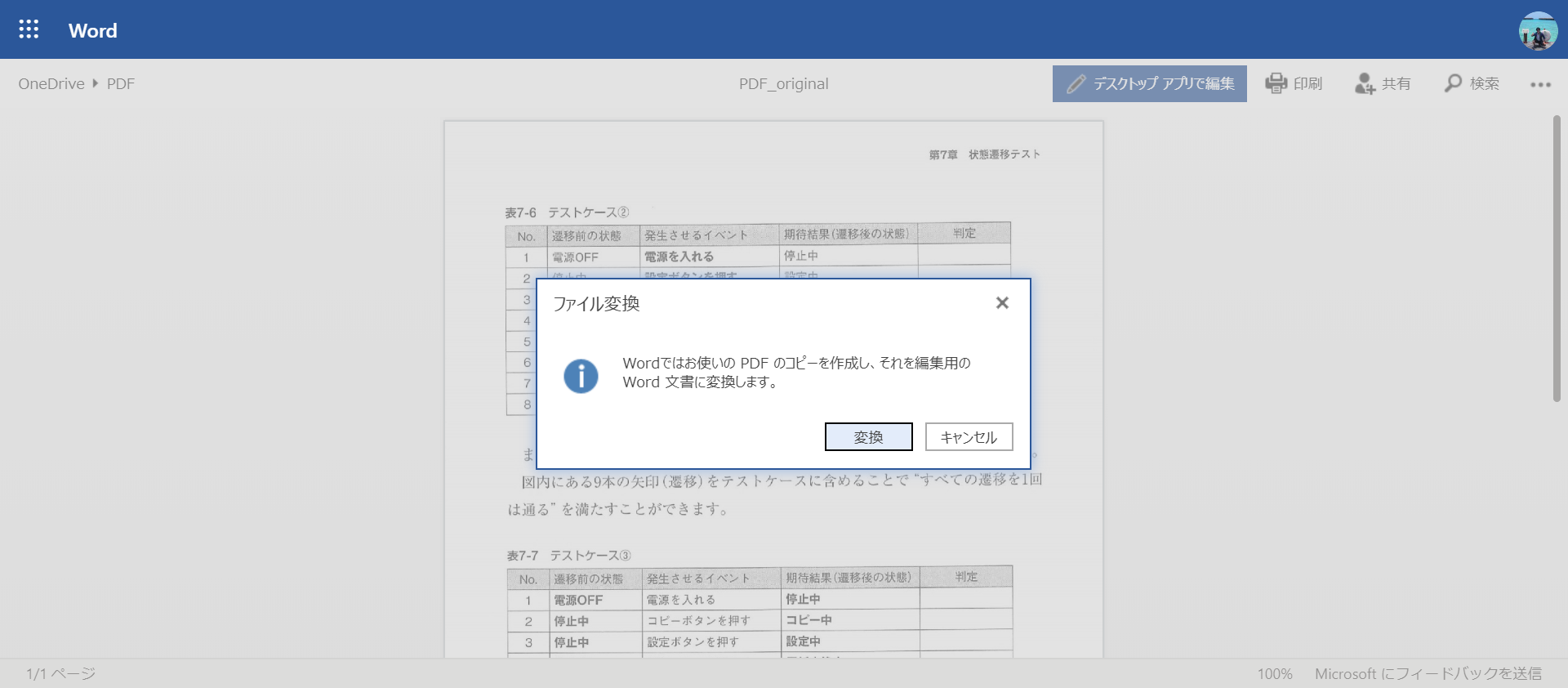
Ensuite, la conversion aura lieu. Lorsque la conversion est terminée, un écran de confirmation apparaîtra, alors appuyez sur "Modifier".
Cela ouvrira Word sur votre navigateur. Il est correctement converti en données de table.
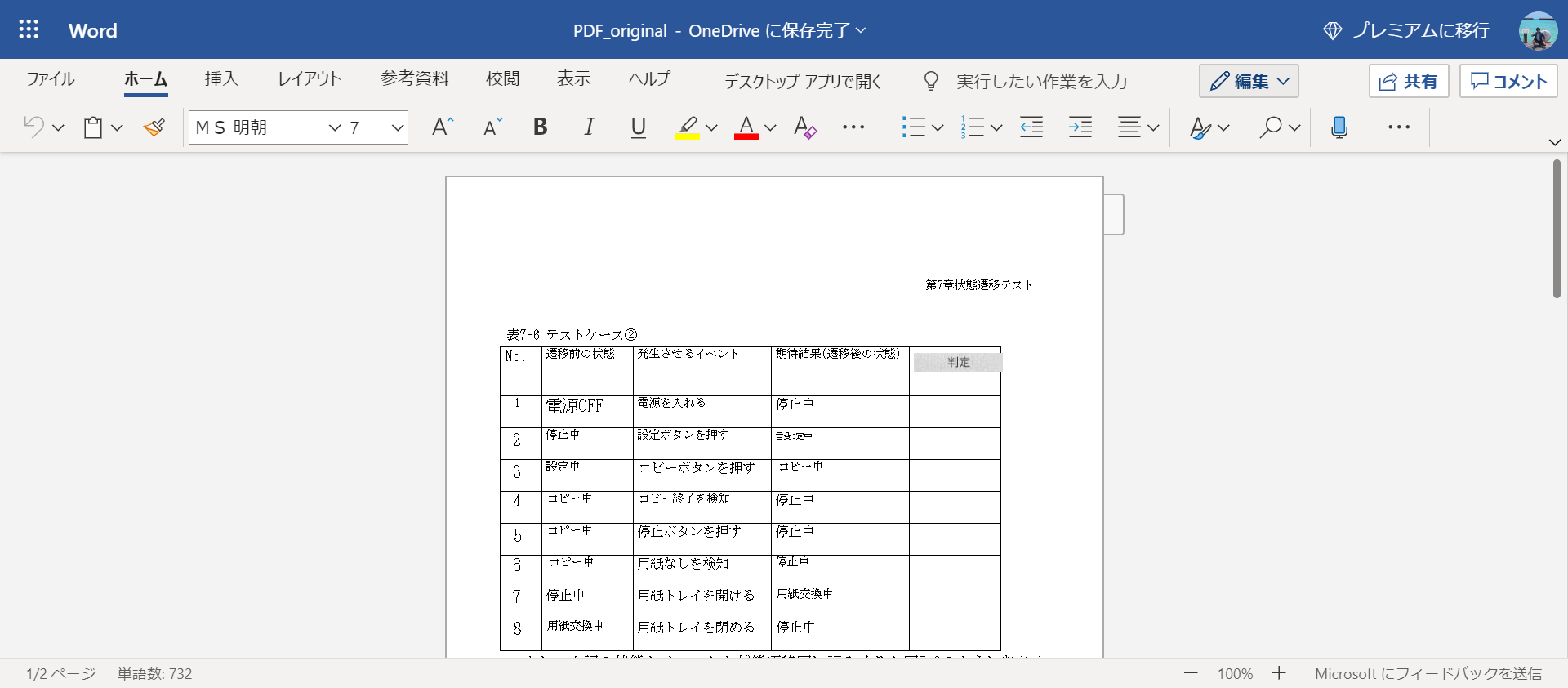
Il peut y avoir des endroits où les caractères ne sont pas reconnus correctement, donc si vous pouvez le réparer à ce stade, corrigez-le manuellement. Dans ce cas, "Copier" peut être "Coby", mais la conversion est presque correcte. C'est tout à fait une précision de reconnaissance!
2. Enregistrer le mot OCR traité au format PDF
Les fichiers PDF sont plus faciles à gérer en Python que les fichiers Word, alors convertissez-les en PDF et téléchargez-les.
Sélectionnez "Fichier" en haut à gauche et sélectionnez Enregistrer sous → Télécharger au format PDF.

3. Extrayez le tableau en PDF avec Python
Ouvrons le fichier PDF téléchargé. Contrairement au PDF d'origine, le tableau est correctement reconnu comme un tableau. C'est mal de voir la police parce qu'elle est grande ou petite, mais ne vous inquiétez pas car elle sera extraite en tant que DataFrame de pandas.
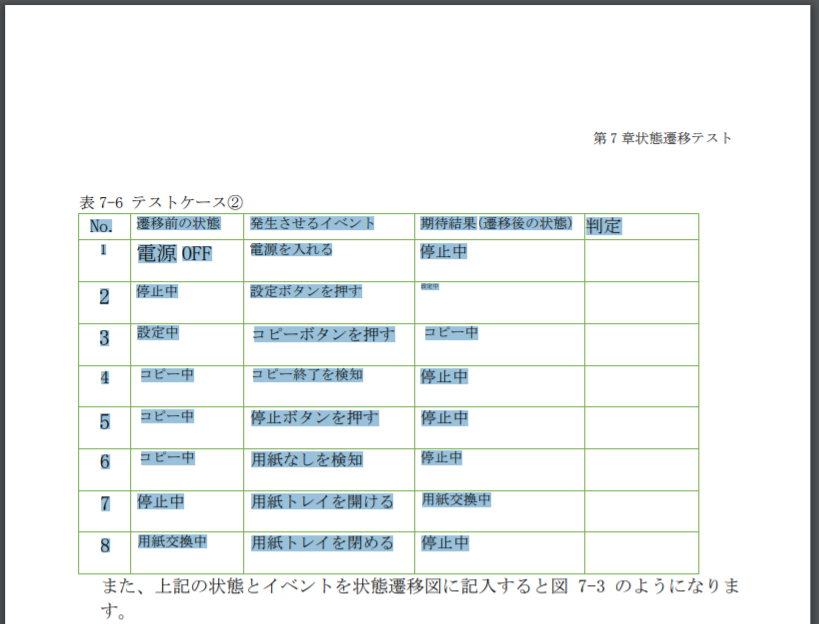
D'ailleurs, quand on arrive à ce point, le reste est une simple table utilisant Python par la méthode introduite dans l'article "Extraire le tableau en PDF avec Python". Peut être extrait.
python
import pandas as pd
import tabula
# lattice=True pour déterminer la cellule par l'axe du tableau
dfs = tabula.read_pdf("PDF_ocr.pdf", lattice=True, pages='1')
for df in dfs:
display(df)
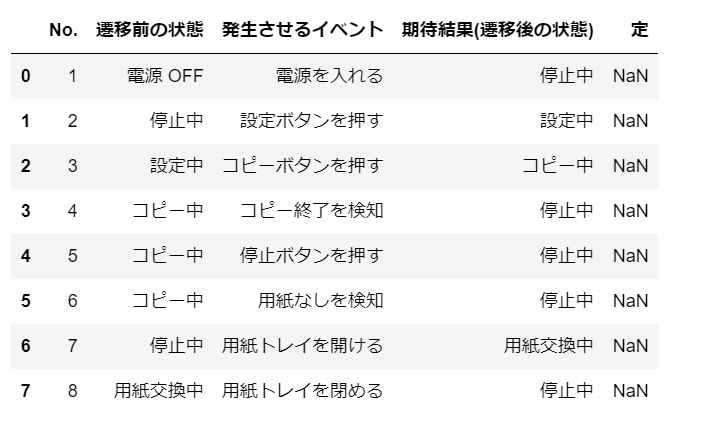
Résultat d'exécution
Recommended Posts