[Python] Déterminez le type d'iris avec SVM
Essayons un problème de classification d'apprentissage automatique utilisant les données d'iris, qui sont souvent utilisées dans les conférences pour débutants.
Données à utiliser
données irei. (Iris signifie fleur "Ayame".) Données sur trois variétés d'iris, Setosa Versicolor Virginica. Un total de 150 ensembles de données.
Contenu de l'ensemble de données
Sepal Length: Longueur de la pièce
Largeur sépale: largeur de la pièce
Longueur du pétale: Longueur du pétale
Largeur des pétales: Largeur des pétales
Nom: Données variétales d'Ayame (Iris-Setosa, Iris-Vesicolor, Iris-Virginica)

Modèle à adopter
SVM (Support Vector Machine). SVM convient au problème de classification de l'apprentissage supervisé. Un modèle qui peut également faire des discriminateurs de spam. Puisqu'il s'agit d'un apprentissage supervisé, des données de caractéristiques et des variables objectives sont nécessaires.
Flux global
- Préparation des données
- Visualisez les données
- Apprendre et évaluer le modèle
Entraine toi
1) Préparation des données
Tout d'abord, importez les bibliothèques nécessaires, puis importez et confirmez les données.
import numpy as np
import pandas as pd
import seaborn as sns
sns.set_style("whitegrid")
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.model_selection import train_test_split, cross_validate
df = pd.read_csv("iris.csv")
df.head()
SepalLength SepalWidth PetalLength PetalWidth Name
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
Divisez en données d'entraînement et données de test.
X = df[["SepalLength","SepalWidth","PetalLength","PetalWidth"]]
y = df["Name"]
X_train, X_test, y_train, y_test = train_test_split(X, y)
X_train.shape, X_test.shape
((112, 4), (38, 4)) #Vérifiez le nombre de matrices après division
Créez un Dataframe pour chacune des données d'entraînement et des données de test.
data_train = pd.DataFrame(X_train)
data_train["Name"] = y_train
2) Visualisez les données
Dans les données de vérification, quelle est la relation réelle entre le type d'iris et la quantité d'excédent acquis? Tracez et voyez s'il existe des différences dans les caractéristiques pour chaque type.
sns.pairplot(data_train, hue='Name', palette="husl")
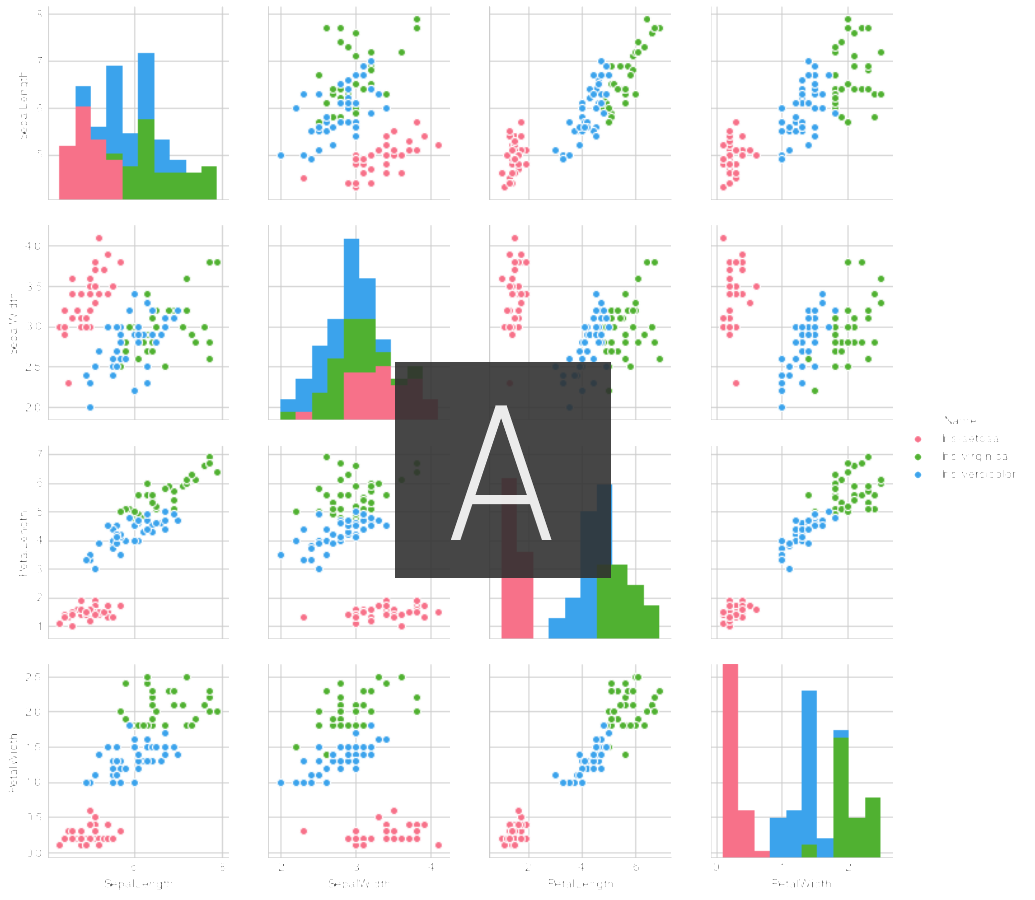
Certes, il semble qu'il y ait une nette différence dans chaque quantité de fonctionnalités en fonction du type d'iris.
3) Apprendre et évaluer le modèle
Mettons en fait les données de vérification dans SVM et créons un modèle.
X_train = data_train[["SepalLength", "SepalWidth","PetalLength"]].values
y_train = data_train["Name"].values
from sklearn import svm,metrics
clf = svm.SVC()
clf.fit(X_train,y_train)
Entrez les données de test dans le modèle créé.
pre = clf.predict(X_test)
Évaluez le modèle.
ac_score = metrics.accuracy_score(y_test,pre)
print("Taux de réponse correct=", ac_score)
Taux de réponse correct= 0.9736842105263158
Il a été confirmé que les données de test et les résultats obtenus par le modèle étaient cohérents à 97%.
Recommended Posts