100 Language Processing Knock 2020 Chapitre 4: Analyse morphologique
L'autre jour, 100 Language Processing Knock 2020 a été publié. Je ne travaille moi-même sur le langage naturel que depuis un an, et je ne connais pas les détails, mais je vais résoudre tous les problèmes et les publier afin d'améliorer mes compétences techniques.
Tout doit être exécuté sur le notebook jupyter, et les restrictions de l'énoncé du problème peuvent être brisées de manière pratique. Le code source est également sur github. Oui.
Le chapitre 3 est ici.
L'environnement est Python 3.8.2 et Ubuntu 18.04.
Chapitre 4: Analyse morphologique
Utilisez MeCab pour analyser morphologiquement le texte (neko.txt) du roman de Natsume Soseki "Je suis un chat" et enregistrez le résultat dans un fichier appelé neko.txt.mecab. Utilisez ce fichier pour implémenter un programme qui répond aux questions suivantes.
Veuillez télécharger l'ensemble de données requis depuis ici.
Le fichier téléchargé est placé sous «données».
Analyse morphologique avec MeCab
code
mecab < data/neko.txt > data/neko.txt.mecab
Vous pouvez obtenir un fichier avec un contenu comme celui-ci
Un nom,nombre,*,*,*,*,un,Ichi,Ichi
EOS
EOS
symbole,Vide,*,*,*,*, , ,
Mon nom,Synonyme,Général,*,*,*,je,Wagahai,Wagahai
Est un assistant,Assistance,*,*,*,*,Est,C,sensationnel
Chat substantif,Général,*,*,*,*,Chat,chat,chat
Avec verbe auxiliaire,*,*,*,Spécial,Type continu,Est,De,De
Un verbe d'aide,*,*,*,Cinq étapes, La ligne Al,Forme basique,y a-t-il,Al,Al
.. symbole,Phrase,*,*,*,*,。,。,。
30. Lecture des résultats de l'analyse morphologique
Implémentez un programme qui lit les résultats de l'analyse morphologique (neko.txt.mecab). Cependant, chaque élément morphologique est stocké dans un type de mappage avec la clé de la forme de surface (surface), de la forme de base (base), d'une partie du mot (pos) et d'une partie du mot sous-classification 1 (pos1), et une phrase est exprimée sous forme d'une liste d'éléments morphologiques (type de mappage). Faisons le. Pour le reste des problèmes du chapitre 4, utilisez le programme créé ici.
Préparez une fonction pour extraire la forme de la couche de surface, la forme de base, le numéro de pièce et la sous-classification de pièce de pièce 1 de chaque ligne de la sortie de MeCab. Renvoie None lorsqu'il atteint la fin de la phrase.
code
def line_to_dict(line):
line = line.rstrip()
if line == 'EOS':
return None
lst = line.split('\t')
pos = lst[1].split(',')
dct = {
'surface' : lst[0],
'pos' : pos[0],
'pos1' : pos[1],
'base' : pos[6],
}
return dct
Convertissez la sortie de MeCab en liste des sorties de la fonction ci-dessus.
code
def mecab_to_list(text):
lst = []
tmp = []
for line in text.splitlines():
dct = line_to_dict(line)
if dct is not None:
tmp.append(dct)
elif tmp:
lst.append(tmp)
tmp = []
return lst
code
with open('data/neko.txt.mecab') as f:
neko = mecab_to_list(f.read())
production(3 premiers éléments)
[[{'surface': 'un', 'pos': 'nom', 'pos1': 'nombre', 'base': 'un'}],
[{'surface': '\u3000', 'pos': 'symbole', 'pos1': 'Vide', 'base': '\u3000'},
{'surface': 'je', 'pos': 'nom', 'pos1': '代nom', 'base': 'je'},
{'surface': 'Est', 'pos': 'Particule', 'pos1': '係Particule', 'base': 'Est'},
{'surface': 'Chat', 'pos': 'nom', 'pos1': 'Général', 'base': 'Chat'},
{'surface': 'alors', 'pos': 'Verbe auxiliaire', 'pos1': '*', 'base': 'Est'},
{'surface': 'y a-t-il', 'pos': 'Verbe auxiliaire', 'pos1': '*', 'base': 'y a-t-il'},
{'surface': '。', 'pos': 'symbole', 'pos1': 'Phrase', 'base': '。'}],
[{'surface': 'Nom', 'pos': 'nom', 'pos1': 'Général', 'base': 'Nom'},
{'surface': 'Est', 'pos': 'Particule', 'pos1': '係Particule', 'base': 'Est'},
{'surface': 'encore', 'pos': 'adverbe', 'pos1': 'Connexion auxiliaire', 'base': 'encore'},
{'surface': 'Non', 'pos': 'adjectif', 'pos1': 'Indépendance', 'base': 'Non'},
{'surface': '。', 'pos': 'symbole', 'pos1': 'Phrase', 'base': '。'}]]
31. verbe
Extraire toutes les formes de surface du verbe.
code
surfaces_of_verb = {
dct['surface']
for sent in neko
for dct in sent
if dct['pos'] == 'verbe'
}
for _, verb in zip(range(10), surfaces_of_verb):
print(verb)
print('total:', len(surfaces_of_verb))
production
Amour propre
Jaillissant
Renflement
Allons y
jouer
À
Résistant
Saleté
Frappé
Travail
total: 3893
32. Prototype du verbe
Extraire toutes les formes originales du verbe.
code
bases_of_verb = {
dct['base']
for sent in neko
for dct in sent
if dct['pos'] == 'verbe'
}
for _, verb in zip(range(10), bases_of_verb):
print(verb)
print('total:', len(bases_of_verb))
production
Suku
disparaître
jouer
Aube
Ressortir
Frappé
Apparaître
Demain
Remplir
Balançoire
total: 2300
33. «B de A»
Extraire la nomenclature dans laquelle deux nomenclatures sont reliées par "non".
code
def tri_grams(sent):
return zip(sent, sent[1:], sent[2:])
def is_A_no_B(x, y, z):
return x['pos'] == z['pos'] == 'nom' and y['base'] == 'de'
A_no_Bs = {
''.join([x['surface'] for x in tri_gram])
for sent in neko
for tri_gram in tri_grams(sent)
if is_A_no_B(*tri_gram)
}
for _, phrase in zip(range(10), A_no_Bs):
print(phrase)
print('total:', len(A_no_Bs))
Prenez le tri-gramme et n'extrayez que ceux qui sont "nom + + nez". La double boucle est tournée par la méthode d'inclusion de liste.
résultat
Ma place
Filet de thon
Pousse maison
Le deuxième roi
Ushigome Yamabushi
Questions et réponses à gauche
Pattes de chat
Visiteurs
Vieil homme
Autre que
total: 4924
34. Concaténation de nomenclature
Extraire la concaténation de la nomenclature (noms qui apparaissent consécutivement) avec la correspondance la plus longue.
code
def longest_nouns(sent):
lst = []
tmp = []
for dct in sent:
if dct['pos'] == 'nom':
tmp.append(dct['surface'])
else:
if len(tmp) > 1:
lst.append(tmp)
tmp = []
return lst
noun_chunks = [
''.join(nouns)
for sent in neko
for nouns in longest_nouns(sent)
]
for _, chunk in zip(range(10), noun_chunks):
print(chunk)
print('total:', len(noun_chunks))
Une boucle est tournée pour chaque phrase pour extraire la partie où la nomenclature est continue. L'apparition d'une seule nomenclature n'était pas considérée comme une concaténation.
production
Chez l'homme
Le pire
Opportun
Un cheveu
Puis chat
une fois
Puupuu et fumée
À l'intérieur du manoir
Trois cheveux
Autre que étudiant
total: 7335
35. Fréquence d'occurrence des mots
Trouvez les mots qui apparaissent dans la phrase et leur fréquence d'apparition et classez-les par ordre décroissant de fréquence d'apparition.
code
from collections import Counter
code
surfaces = [
dct['surface']
for sent in neko
for dct in sent
]
cnt = Counter(surfaces).most_common()
for _, (word, freq) in zip(range(10), cnt):
print(word, freq)
Vous venez de compter le nombre avec Counter.
production
9194
。 7486
6868
、 6772
Est 6420
Au 6243
6071
Et 5508
Est 5337
3988
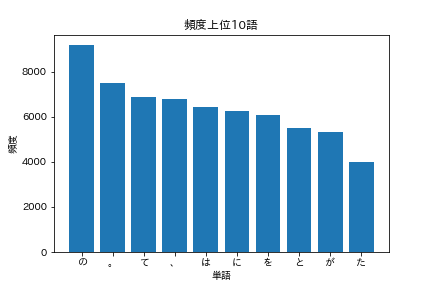
36. Top 10 des mots les plus fréquents
Affichez les 10 mots les plus courants et leur fréquence d'apparition dans un graphique (par exemple, un graphique à barres).
code
import matplotlib.pyplot as plt
import japanize_matplotlib
Je veux utiliser matplotlib, mais le japonais ne s'affiche pas bien avec cela seul. L'importation de japanize_matplotlib fonctionne très bien.
code
words = [word for word, _ in cnt[:10]]
freqs = [freq for _, freq in cnt[:10]]
plt.bar(words, freqs)
plt.title('Top 10 des mots les plus fréquents')
plt.xlabel('mot')
plt.ylabel('la fréquence')
plt.show()
Vous devriez voir un graphique comme celui ci-dessous.
37. Top 10 des mots qui coïncident fréquemment avec "chat"
Afficher 10 mots qui cohabitent souvent avec "chat" (fréquence élevée de cooccurrence) et leur fréquence d'apparition dans un graphique (par exemple, un graphique à barres).
Les mots qui "coexistent" sont considérés comme apparaissant dans la même phrase.
code
co_occured = []
for sent in neko:
if any(dct['base'] == 'Chat' for dct in sent):
words = [dct['base'] for dct in sent if dct['base'] != 'Chat']
co_occured.extend(words)
cnt = Counter(co_occured).most_common()
for _, (word, freq) in zip(range(10), cnt):
print(word, freq)
production
391
Est 272
、 252
À 250
232
231
229
。 209
Et 202
Est 180
Honnêtement, c'est ennuyeux avec seulement des mots auxiliaires, donc je vais limiter les parties.
code
co_occured = []
for sent in neko:
if any(dct['base'] == 'Chat' for dct in sent):
words = [
dct['base']
for dct in sent
if dct['base'] != 'Chat'
and dct['pos'] in {'nom', 'verbe', 'adjectif', 'adverbe'}
]
co_occured.extend(words)
cnt = Counter(co_occured).most_common()
for _, (word, freq) in zip(range(10), cnt):
print(word, freq)
production
144
* 63
Chose 59
Je 58
58
Il y a 55
55
Humain 40
Pas 39
Dire 38
Puisque c'est un gros problème, jetons un coup d'œil à quelques phrases dans lesquelles les chats et les humains coexistent.
code
for sent in neko[:1000]:
if any(dct['base'] == 'Chat' for dct in sent) and any(dct['base'] == 'Humain' for dct in sent):
lst = [dct['surface'] for dct in sent]
print(''.join(lst))
code
Shira-kun a versé des larmes et a raconté toute l'histoire, et il est dit que pour que nos chats complètent l'amour des parents et des enfants et mènent une belle vie de famille, nous devons combattre les humains et les détruire. C'était.
Cependant, malheureusement, je l'ai laissé tel quel parce que les êtres humains sont des animaux qui n'ont pas été baignés dans les bénédictions du ciel dans la mesure où ils peuvent comprendre la langue du genre Cat.
J'aimerais dire un peu au lecteur, mais ce n'est pas bien que les êtres humains aient l'habitude de m'évaluer avec un ton dédaigneux, comme les chats.
Il peut être courant pour les enseignants qui sont conscients de leur ignorance et qui ont un visage fier de penser que les vaches et les chevaux sont fabriqués à partir de sardines humaines et que les chats sont fabriqués à partir de fumier de vache et de cheval. Cependant, ce n'est pas une personne très agréable à regarder.
De l'autre côté, une ligne, l'égalité et l'indiscrimination, il semble qu'aucun des chats n'a ses propres caractéristiques uniques, mais quand on rampe dans la société féline, c'est assez compliqué et le mot du monde humain de 10 personnes et 10 couleurs reste Il peut également être appliqué ici.
En regardant cela, les humains peuvent être supérieurs aux chats dans le sens de l'équité déterminée par l'égoïsme, mais la sagesse semble être inférieure aux chats.
Il peut être nécessaire pour une personne comme le maître qui a les deux côtés d'écrire dans un journal et de montrer son propre visage qui n'est pas montré au monde dans la pièce sombre, mais quand il s'agit de notre genre de chat, il est authentique de s'asseoir et d'uriner. C'est un journal, donc je ne pense pas que ce soit suffisant pour prendre un travail aussi pénible et sauver mon sérieux.
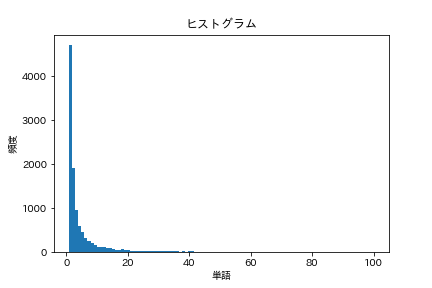
38. histogramme
Tracez un histogramme de la fréquence d'occurrence des mots (l'axe horizontal représente la fréquence d'occurrence et l'axe vertical représente le nombre de types de mots qui prennent la fréquence d'occurrence sous forme de graphique à barres).
code
words = [
dct['base']
for sent in neko
for dct in sent
]
cnt = Counter(words).most_common()
freqs = [freq for _, freq in cnt]
plt.title('histogramme')
plt.xlabel('mot')
plt.ylabel('la fréquence')
plt.hist(freqs, bins=100, range=(1,100))
plt.show()
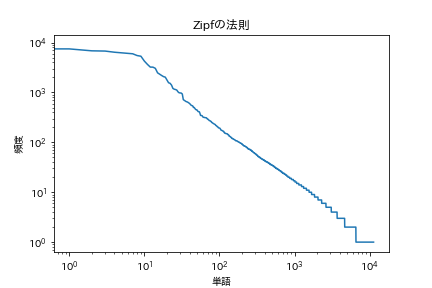
39. Loi de Zipf
Tracez les deux graphiques logarithmiques avec la fréquence d'occurrence des mots sur l'axe horizontal et la fréquence d'occurrence sur l'axe vertical.
[Loi de Zip](https://ja.wikipedia.org/wiki/%E3%82%B8%E3%83%83%E3%83%97%E3%81%AE%E6%B3%95%E5 % 89% 87)
code
plt.title('Loi de Zipf')
plt.xlabel('mot')
plt.ylabel('la fréquence')
plt.xscale('log')
plt.yscale('log')
plt.plot(range(len(freqs)), freqs)
plt.show()
Ça ressemble à ça.
Vient ensuite le chapitre 5
Traitement du langage 100 knocks 2020 Chapitre 5: Analyse des dépendances
Recommended Posts