100 Language Processing Knock 2020 Chapitre 6: Apprentissage automatique
L'autre jour, 100 Language Processing Knock 2020 a été publié. Je ne travaille moi-même sur le langage naturel que depuis un an, et je ne connais pas les détails, mais je vais résoudre tous les problèmes et les publier afin d'améliorer mes compétences techniques.
Tout doit être exécuté sur le notebook jupyter, et les restrictions de l'énoncé du problème peuvent être brisées de manière pratique. Le code source est également sur github. Oui.
Le chapitre 5 est ici.
L'environnement est Python 3.8.2 et Ubuntu 18.04.
Chapitre 6: Apprentissage automatique
Dans ce chapitre, nous utiliserons l'ensemble de données d'agrégateur d'actualités publié par Fabio Gasparetti pour travailler sur la tâche (classification par catégorie) de classer les titres d'articles de presse dans les catégories «entreprise», «science et technologie», «divertissement» et «santé».
Veuillez télécharger l'ensemble de données requis depuis ici.
Le fichier téléchargé est placé sous «données».
50. Obtention et mise en forme des données
Téléchargez le jeu de données News Aggregator et créez les données d'entraînement (train.txt), les données de vérification (valid.txt) et les données d'évaluation (test.txt) comme suit.
- Décompressez le fichier zip téléchargé et lisez l'explication de readme.txt.
- N'extrayez que les cas (articles) où la source d'information (éditeur) est "Reuters", "Huffington Post", "Businessweek", "Contactmusic.com", "Daily Mail".
- Triez au hasard les observations extraites.
- Divisez 80% des observations extraites en données d'apprentissage et les 10% restants en données de vérification et en données d'évaluation, et enregistrez-les respectivement sous les noms de fichier train.txt, valid.txt et test.txt. Écrivez un cas par ligne dans le fichier et utilisez un format délimité par des tabulations pour les noms de catégories et les en-têtes d'articles. Après avoir créé les données d'entraînement et les données d'évaluation, vérifiez le nombre de cas dans chaque catégorie.
Lisez l'ensemble de données à partir du fichier zip.
code
import zipfile
code
#Lire à partir du fichier zip
with zipfile.ZipFile('data/NewsAggregatorDataset.zip') as f:
with f.open('newsCorpora.csv') as g:
data = g.read()
#Décoder la chaîne d'octets
data = data.decode('UTF-8').splitlines()
#Onglet délimité
data = [line.split('\t') for line in data]
len(data)
production
422937
Spécifiez la source d'informations et triez au hasard.
code
publishers = {
'Reuters',
'Huffington Post',
'Businessweek',
'Contactmusic.com',
'Daily Mail',
}
data = [
lst
for lst in data
if lst[3] in publishers
]
data.sort()
len(data)
production
13356
Jeter tout sauf le nom de la catégorie et l'en-tête de l'article.
code
data = [
[lst[4], lst[1]]
for lst in data
]
Divisez en données d'apprentissage / de vérification / d'évaluation. sklearn a une fonction avec une fonction similaire, mais ce n'est pas aussi difficile que d'entrer dans la boîte noire. Spécifiez simplement l'emplacement à découper et à découper.
code
train_end = int(len(data) * 0.8)
valid_end = int(len(data) * 0.9)
train = data[:train_end]
valid = data[train_end:valid_end]
test = data[valid_end:]
print('Données d'entraînement', len(train))
print('Données de validation', len(valid))
print('Données d'évaluation', len(test))
production
Données d'entraînement 10684
Données de validation 1336
Données d'évaluation 1336
Enregistrez dans un fichier.
code
def write_dataset(filename, data):
with open(filename, 'w') as f:
for lst in data:
print('\t'.join(lst), file = f)
code
write_dataset('../train.txt', train)
write_dataset('../valid.txt', valid)
write_dataset('../test.txt', test)
Vérifiez le nombre de cas pour chaque catégorie.
code
from collections import Counter
from tabulate import tabulate
code
categories = ['b', 't', 'e', 'm']
category_names = ['business', 'science and technology', 'entertainment', 'health']
table = [
[name] + [freqs[cat] for cat in categories]
for name, freqs in [
('train', Counter([cat for cat, _ in train])),
('valid', Counter([cat for cat, _ in valid])),
('test', Counter([cat for cat, _ in test])),
]
]
tabulate(table, headers = categories)
production
b t e m
----- ---- ---- ---- ---
train 4463 1223 4277 721
valid 617 168 459 92
test 547 134 558 97
51. Extraction d'entités
Extrayez les fonctionnalités des données d'entraînement, des données de vérification et des données d'évaluation, et enregistrez-les sous les noms de fichier train.feature.txt, valid.feature.txt et test.feature.txt (ce fichier sera réutilisé ultérieurement à la question 70). Faire). Écrivez un cas par ligne dans le fichier et utilisez un format séparé par des espaces pour les noms de catégories et les en-têtes d'articles. N'hésitez pas à concevoir les fonctionnalités susceptibles d'être utiles pour la catégorisation. La ligne de base minimale serait un titre d'article converti en une chaîne de mots.
Il semble que tf-idf ou vecteur de mot puisse être utilisé, mais comme l'obscurité de l'extraction de caractéristiques est infiniment profonde, je voudrais m'échouer dans des eaux peu profondes. En d'autres termes, Bag-of-Words.
code
import re
import spacy
import nltk
Divisez-le en chaînes de mots et rendez-les inférieurs et radicaux.
code
nlp = spacy.load('en')
stemmer = nltk.stem.snowball.SnowballStemmer(language='english')
def tokenize(x):
x = re.sub(r'\s+', ' ', x)
x = nlp.make_doc(x) # nlp(x)Parce qu'il fonctionne autrement que le tokenizer lent
x = [stemmer.stem(doc.lemma_.lower()) for doc in x]
return x
code
tokenized_train = [[cat, tokenize(line)] for cat, line in train]
tokenized_valid = [[cat, tokenize(line)] for cat, line in valid]
tokenized_test = [[cat, tokenize(line)] for cat, line in test]
Extrayez les jetons à utiliser comme quantités de caractéristiques.
code
#Comptez la fréquence d'apparition
counter = Counter([
token
for _, tokens in tokenized_train
for token in tokens
])
#Supprimer les mots à haute et basse fréquence
vocab = [
token
for token, freq in counter.most_common()
if 2 < freq < 300
]
len(vocab)
production
4790
Le bi-gramme est également une quantité caractéristique. Les États-Unis et nous sont devenus les mêmes en raison de la réduction, mais si le bi-gramme est inclus, "le stock américain" sera efficace en tant que quantité caractéristique.
code
bi_grams = Counter([
bi_gram
for _, sent in tokenized_train
for bi_gram in zip(sent, sent[1:])
]).most_common()
bi_grams = [tup for tup, freq in bi_grams if freq > 4]
len(bi_grams)
production
3094
vous sauvegardez.
code
with open('result/vocab_for_news.txt', 'w') as f:
for token in vocab:
print(token, file = f)
code
with open('result/bi_grams_for_news.txt', 'w') as f:
for tup in bi_grams:
print(' '.join(tup), file = f)
Total des fonctionnalités
code
features = vocab + [' '.join(x) for x in bi_grams]
len(features)
production
7884
Extrayez le montant de la fonction et enregistrez-le.
code
import numpy as np
code
vocab_dict = {x:n for n, x in enumerate(vocab)}
bi_gram_dict = {x:n for n, x in enumerate(bi_grams)}
def count_uni_gram(sent):
lst = [0 for token in vocab]
for token in sent:
if token in vocab_dict:
lst[vocab_dict[token]] += 1
return lst
def count_bi_gram(sent):
lst = [0 for token in bi_grams]
for tup in zip(sent, sent[1:]):
if tup in bi_gram_dict:
lst[bi_gram_dict[tup]] += 1
return lst
code
def prepare_feature_dataset(data):
ts = [categories.index(cat) for cat, _ in data]
xs = [
count_uni_gram(sent) + count_bi_gram(sent)
for _, sent in data
]
return np.array(xs, dtype=np.float32), np.array(ts, dtype=np.int8)
def write_feature_dataset(filename, xs, ts):
with open(filename, 'w') as f:
for t, x in zip(ts, xs):
line = categories[t] + ' ' + ' '.join([str(int(n)) for n in x])
print(line, file = f)
code
train_x, train_t = prepare_feature_dataset(tokenized_train)
valid_x, valid_t = prepare_feature_dataset(tokenized_valid)
test_x, test_t = prepare_feature_dataset(tokenized_test)
code
write_feature_dataset('result/train.feature.txt', train_x, train_t)
write_feature_dataset('result/valid.feature.txt', valid_x, valid_t)
write_feature_dataset('result/test.feature.txt', test_x, test_t)
Regardons un exemple.
code
import pandas as pd
code
with open('result/train.feature.txt') as f:
table = [line.strip().split(' ') for _, line in zip(range(10), f)]
pd.DataFrame(table, columns=['category'] + features)
52. Apprentissage
Apprenez le modèle de régression logistique à l'aide des données d'entraînement construites en> 51.
Utilisez sklearn.
C'est aussi simple que de mettre en œuvre une régression logistique avec la méthode de descente la plus raide, mais si vous essayez de gratter la méthode quasi-Newton, votre cœur sera brisé par la matrice de Hesse et votre cœur se brisera autour de la recherche linéaire, vous aurez donc une lourde charge mentale au quotidien. Il n'est pas recommandé pour les êtres humains. C'est une histoire d'expérience, mais il y a un risque d'exécuter des choses étranges telles que rouler la feuille d'aluminium et l'arrêter là où les conditions de la feuille d'aluminium sont remplies. D'autre part, scikit-learn peut être utilisé même en dormant.
code
from sklearn.linear_model import LogisticRegression
code
lr = LogisticRegression(max_iter=1000)
lr.fit(train_x, train_t)
production
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=1000,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=None, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)
Vous pouvez le faire même si vous dormez car vous pouvez créer un modèle et l'adapter (). C'est très facile.
53. Prévisions
Utilisez le modèle de régression logistique appris en> 52 et implémentez un programme qui calcule la catégorie et sa probabilité de prédiction à partir de l'en-tête d'article donné.
code
def predict(x):
out = lr.predict_proba(x)
preds = out.argmax(axis=1)
probs = out.max(axis=1)
return preds, probs
Prédite par les données d'entraînement.
code
preds, probs = predict(train_x)
pd.DataFrame([[y, p] for y, p in zip(preds, probs)], columns = ['Prévoir', 'probabilité'])
Prédite par les données d'évaluation.
code
preds, probs = predict(test_x)
pd.DataFrame([[y, p] for y, p in zip(preds, probs)], columns = ['Prévoir', 'probabilité'])
54. Mesure du taux de réponse correcte
Mesurez le taux de réponse correct du modèle de régression logistique appris en> 52 sur les données d'entraînement et les données d'évaluation.
code
def accuracy(lr, xs, ts):
ys = lr.predict(xs)
return (ys == ts).mean()
code
print('Données d'entraînement')
print(accuracy(lr, train_x, train_t))
production
Données d'entraînement
0.994664919505803
code
print('Données d'évaluation')
print(accuracy(lr, test_x, test_t))
production
Données d'évaluation
0.906437125748503
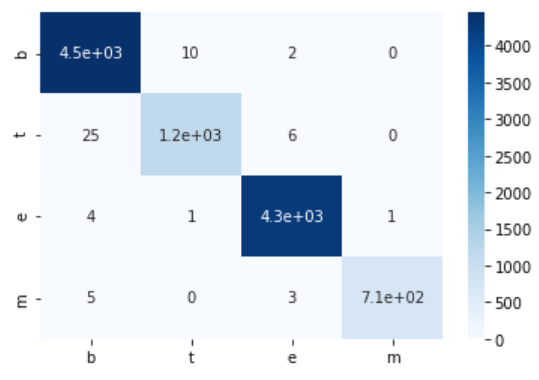
55. Création d'une matrice de confusion
Créer une matrice de confusion du modèle de régression logistique appris en> 52 sur les données d'entraînement et les données d'évaluation.
Vous serez heureux si vous utilisez seaborn. Je pense que c dans la matrice de confusion est la mer de mer née.
code
import seaborn as sns
code
def confusion_matrix(xs, ts):
num_class = np.unique(ts).size
mat = np.zeros((num_class, num_class), dtype=np.int32)
ys = lr.predict(xs)
for y, t in zip(ys, ts):
mat[t, y] += 1
return mat
def show_cm(cm):
sns.heatmap(cm, annot=True, cmap = 'Blues', xticklabels = categories, yticklabels = categories)
code
train_cm = confusion_matrix(train_x, train_t)
print('Données d'entraînement')
print(train_cm)
show_cm(train_cm)
production
Données d'entraînement
[[4451 10 2 0]
[ 25 1192 6 0]
[ 4 1 4271 1]
[ 5 0 3 713]]
code
test_cm = confusion_matrix(test_x, test_t)
print('Données d'évaluation')
print(test_cm)
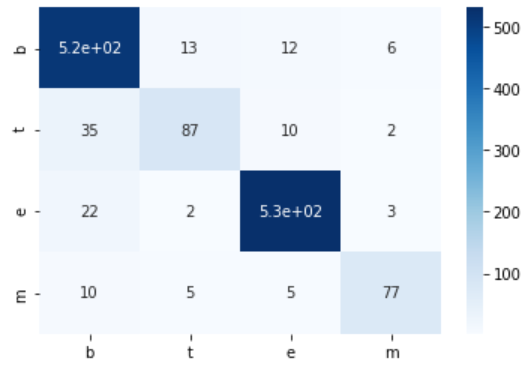
show_cm(test_cm)
production
Données d'évaluation
[[516 13 12 6]
[ 35 87 10 2]
[ 22 2 531 3]
[ 10 5 5 77]]
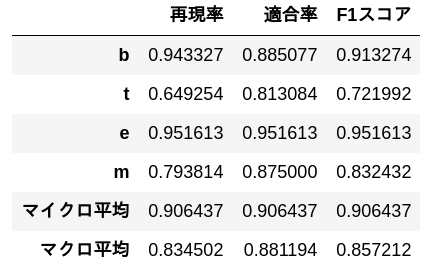
56. Mesure de la précision, du rappel et du score F1
Mesurer la précision, le rappel et le score F1 du modèle de régression logistique appris en> 52 sur les données d'évaluation. Obtenez le taux de précision, le taux de rappel et le score F1 pour chaque catégorie, et intégrez les performances de chaque catégorie avec une micro-moyenne et une macro-moyenne.
Il existe une fonction qui effectue le même traitement dans sklearn, mais je suis en mesure de l'implémenter moi-même. Certaines tâches utilisent la valeur $ F_ {0.5} $, et je pense qu'il vaut mieux l'écrire vous-même.
code
tp = test_cm.diagonal()
tn = test_cm.sum(axis=1) - tp
fp = test_cm.sum(axis=0) - tp
code
p = tp / (tp + tn)
r = tp / (tp + fp)
F = 2 * p * r / (p + r)
code
micro_p = tp.sum() / (tp + tn).sum()
micro_r = tp.sum() / (tp + fp).sum()
micro_F = 2 * micro_p * micro_r / (micro_p + micro_r)
micro_ave = np.array([micro_p, micro_r, micro_F])
code
macro_p = p.mean()
macro_r = r.mean()
macro_F = 2 * macro_p * macro_r / (macro_p + macro_r)
macro_ave = np.array([macro_p, macro_r, macro_F])
code
table = np.array([p, r, F]).T
table = np.vstack([table, micro_ave, macro_ave])
pd.DataFrame(
table,
index = categories + ['Micro moyenne'] + ['Moyenne macro'],
columns = ['Rappel', 'Taux de conformité', 'Score F1'])
57. Confirmation du poids caractéristique
Vérifiez les 10 principales fonctionnalités avec des poids élevés et les 10 principales caractéristiques avec des poids faibles dans le modèle de régression logistique appris en> 52.
code
def show_weight(directional, N):
for i, cat in enumerate(categories):
indices = lr.coef_[i].argsort()[::directional][:N]
best = np.array(features)[indices]
weight = lr.coef_[i][indices]
print(category_names[i])
display(pd.DataFrame([best, weight], index = ['Valeur de la fonctionnalité', 'poids'], columns = np.arange(N) + 1))
Top 10 des fonctionnalités avec un poids important
code
show_weight(-1, 10)

code
show_weight(1, 10)
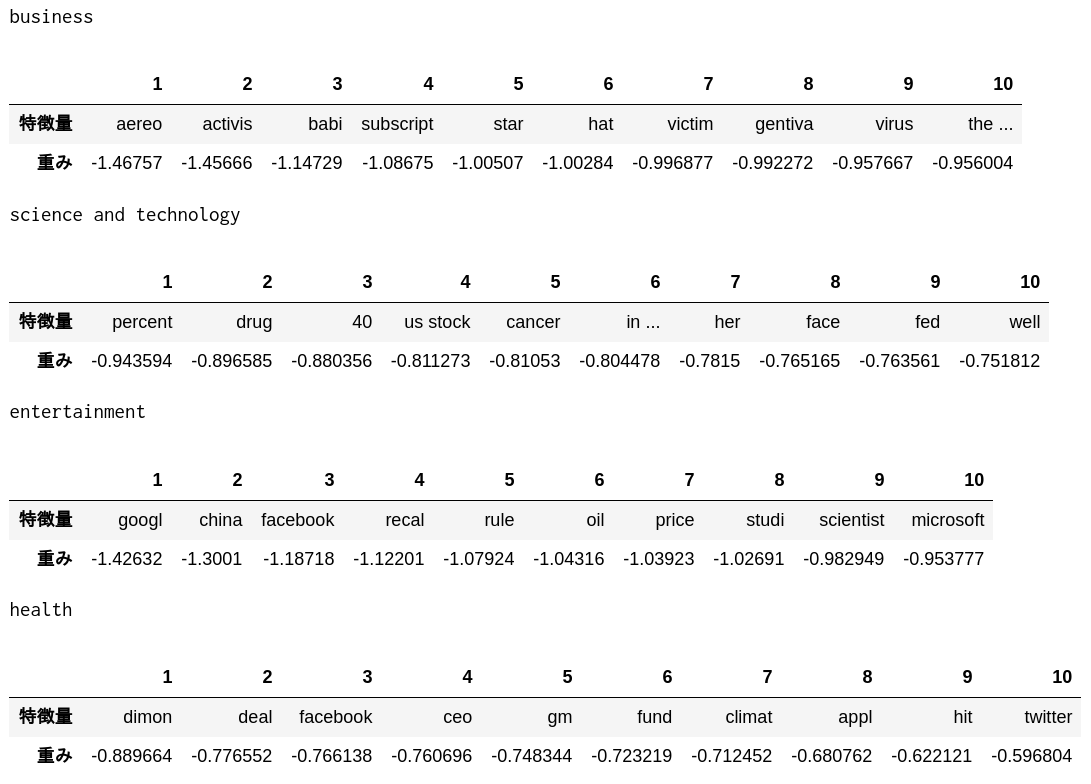
Il semble qu'une telle quantité de caractéristiques ait été extraite.
58. Modifier les paramètres de régularisation
Lors de l'entraînement d'un modèle de régression logistique, le degré de surajustement pendant l'entraînement peut être contrôlé en ajustant les paramètres de régularisation. Apprenez le modèle de régression logistique avec différents paramètres de régularisation et trouvez le taux de réponse correct sur les données d'entraînement, les données de validation et les données d'évaluation. Résumez les résultats de l'expérience dans un graphique avec les paramètres de régularisation sur l'axe horizontal et le taux de précision sur l'axe vertical.
code
import matplotlib.pyplot as plt
import japanize_matplotlib
from tqdm import tqdm
Comme cela prend du temps, surveillez avec tqdm.tqdm.
code
Cs = np.arange(0.1, 5.1, 0.1)
lrs = [LogisticRegression(C=C, max_iter=1000).fit(train_x, train_t) for C in tqdm(Cs)]
code
train_accs = [accuracy(lr, train_x, train_t) for lr in lrs]
valid_accs = [accuracy(lr, valid_x, valid_t) for lr in lrs]
test_accs = [accuracy(lr, test_x, test_t) for lr in lrs]
code
plt.plot(Cs, train_accs, label = 'Apprentissage')
plt.plot(Cs, valid_accs, label = 'Vérification')
plt.plot(Cs, test_accs, label = 'Évaluation')
plt.legend()
plt.show()
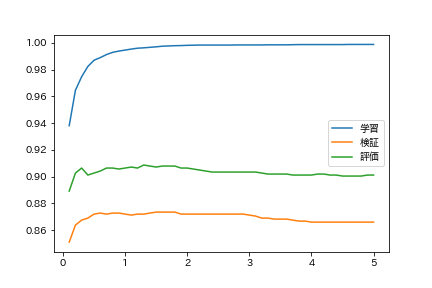
Vous surapprenez que la régularisation est faible.
59. Recherche d'hyper paramètres
Apprenez le modèle de catégorisation tout en modifiant l'algorithme d'apprentissage et les paramètres d'apprentissage. Trouvez le paramètre d'algorithme d'apprentissage qui donne le taux de précision le plus élevé sur les données d'évaluation.
Changeons l'erreur de coupure.
code
tols = np.logspace(0, 2, 50)
lrs = [LogisticRegression(tol=tol, max_iter=1000).fit(train_x, train_t) for tol in tqdm(tols)]
code
train_accs = [accuracy(lr, train_x, train_t) for lr in lrs]
valid_accs = [accuracy(lr, valid_x, valid_t) for lr in lrs]
test_accs = [accuracy(lr, test_x, test_t) for lr in lrs]
code
plt.plot(tols, train_accs, label = 'Apprentissage')
plt.plot(tols, valid_accs, label = 'Vérification')
plt.plot(tols, test_accs, label = 'Évaluation')
plt.xscale('log')
plt.legend()
plt.show()
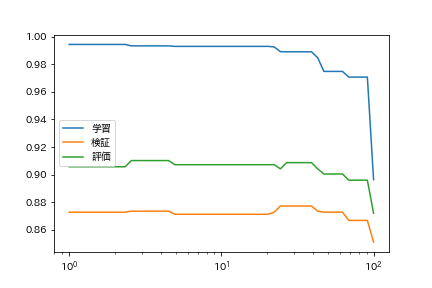
Je voudrais essayer autre chose que la régression logistique.
Donc, en regardant le célèbre organigramme de sklearn, j'ai l'impression que quelque chose ne va pas.

Baies naïves
code
from sklearn.naive_bayes import MultinomialNB
code
nb = MultinomialNB()
nb.fit(train_x, train_t)
production
MultinomialNB(alpha=1.0, class_prior=None, fit_prior=True)
code
accuracy(nb, train_x, train_t)
production
0.9429988768251591
code
accuracy(nb, test_x, test_t)
production
0.8907185628742516
Classification des textes COSPA les plus fortes baies naïves
Machine de vecteur de support linéaire
code
from sklearn.svm import LinearSVC
code
svc = LinearSVC(C=0.1)
svc.fit(train_x,train_t)
production
LinearSVC(C=0.1, class_weight=None, dual=True, fit_intercept=True,
intercept_scaling=1, loss='squared_hinge', max_iter=1000,
multi_class='ovr', penalty='l2', random_state=None, tol=0.0001,
verbose=0)
code
accuracy(svc, train_x, train_t)
production
0.9908274054661176
code
accuracy(svc, test_x, test_t)
production
0.9041916167664671
C'est très bien.
Vient ensuite le chapitre 7
Traitement du langage 100 coups 2020 Chapitre 7: Vecteur Word
Recommended Posts