100 Language Processing Knock 2020 Chapitre 10: Traduction automatique (90-98)
L'autre jour, 100 Language Processing Knock 2020 a été publié. Je ne travaille moi-même sur le langage naturel que depuis un an, et je ne connais pas les détails, mais je vais résoudre tous les problèmes et les publier afin d'améliorer mes compétences techniques.
Tout doit être exécuté sur le notebook jupyter, et les restrictions de l'énoncé du problème peuvent être facilement rompues.
Le code source est également sur github. Oui.
Le chapitre 9 est ici.
J'ai utilisé Python 3.8.2. J'ai utilisé 4 Tesla V100 pour le GPU.
Chapitre 10: Traduction automatique
Dans ce chapitre, un modèle de traduction automatique neuronale est construit à l'aide du corpus de traduction japonais et anglais Kyoto Free Translation Task (KFTT). Faire. Pour créer un modèle de traduction automatique neuronale, fairseq, Hugging Face Transformers, [OpenNMT-py] Tirez parti des outils existants tels que (https://github.com/OpenNMT/OpenNMT-py).
Utilisez fairseq pour la bibliothèque.
La 99ème question finale est la question de la création d'une application Web. Il est impossible de le faire avec jupyter notebook, je le ferai donc dans un autre article.
90. Préparation des données
Téléchargez le jeu de données de traduction automatique. Formatez les données d'entraînement, les données de développement et les données d'évaluation, et effectuez un prétraitement tel que la tokenisation si nécessaire. Cependant, à ce stade, utilisez la morphologie (japonais) et les mots (anglais) comme unité de jeton.
Téléchargez et décompressez les données KFTT.
tar zxvf kftt-data-1.0.tar.gz
Tokenize les données côté japonais avec GiNZA.
cat kftt-data-1.0/data/orig/kyoto-train.ja | sed 's/\s+/ /g' | ginzame > train.ginza.ja
cat kftt-data-1.0/data/orig/kyoto-dev.ja | sed 's/\s+/ /g' | ginzame > dev.ginza.ja
cat kftt-data-1.0/data/orig/kyoto-test.ja | sed 's/\s+/ /g' | ginzame > test.ginza.ja
for src, dst in [
('train.ginza.ja', 'train.spacy.ja'),
('dev.ginza.ja', 'dev.spacy.ja'),
('test.ginza.ja', 'test.spacy.ja'),
]:
with open(src) as f:
lst = []
tmp = []
for x in f:
x = x.strip()
if x == 'EOS':
lst.append(' '.join(tmp))
tmp = []
elif x != '':
tmp.append(x.split('\t')[0])
with open(dst, 'w') as f:
for line in lst:
print(line, file=f)
C'est une mauvaise attitude de définir le fichier de sortie sur "~ .spacy.ja", mais je pense que ce n'est pas grave parce que je l'ai fait. Vous pouvez créer des données comme celle-ci.
Yukifune (Shushu, 1420 (Oei 27))-1506 (3e année d'Eisho)) est un problème, et il était un peintre à l'encre et un prêtre Zen qui était actif à l'époque Muromachi dans la seconde moitié du 15ème siècle, et est également appelé un saint de la peinture.
Cela a complètement changé la peinture à l'encre japonaise.
諱 s'appelait "Toyo" ou "Sesshu".
Né à Bichu-koku, il a déménagé à Suo-koku après être entré à Kyoto et Sogoku-ji.
Après cela, il a accompagné le messager pour étudier la peinture à l'encre de Chine en Chine (Ming).
Il existe de nombreuses œuvres, non seulement des peintures d'eau de montagne de style chinois, mais aussi des portraits et des peintures de fleurs et d'oiseaux.
La composition audacieuse et les coups de pinceau puissants créent un style de peinture très unique.
Six des œuvres existantes ont été désignées comme trésors nationaux, et on peut dire qu'elles ont reçu une évaluation exceptionnelle parmi les peintres japonais.
Pour cette raison, il existe un grand nombre d'œuvres appelées «Denyukifune Brush» dans le Kacho Zukanfu.
Il existe de nombreux désaccords parmi les experts, qu'ils soient réels ou non.
Tokenize les données côté anglais avec SpaCy.
import re
import spacy
nlp = spacy.load('en')
for src, dst in [
('kftt-data-1.0/data/orig/kyoto-train.en', 'train.spacy.en'),
('kftt-data-1.0/data/orig/kyoto-dev.en', 'dev.spacy.en'),
('kftt-data-1.0/data/orig/kyoto-test.en', 'test.spacy.en'),
]:
with open(src) as f, open(dst, 'w') as g:
for x in f:
x = x.strip()
x = re.sub(r'\s+', ' ', x)
x = nlp.make_doc(x)
x = ' '.join([doc.text for doc in x])
print(x, file=g)
C'est comme ça.
Known as Sesshu ( 1420 - 1506 ) , he was an ink painter and Zen monk active in the Muromachi period in the latter half of the 15th century , and was called a master painter .
He revolutionized the Japanese ink painting .
He was given the posthumous name " Toyo " or " Sesshu (Ma secte) . "
Born in Bicchu Province , he moved to Suo Province after entering SShokoku - ji Temple in Kyoto .
Later he accompanied a mission to Ming Dynasty China and learned Chinese ink painting .
His works were many , including not only Chinese - style landscape paintings , but also portraits and pictures of flowers and birds .
His bold compositions and strong brush strokes constituted an extremely distinctive style .
6 of his extant works are designated national treasures . Indeed , he is considered to be extraordinary among Japanese painters .
For this reason , there are a great many artworks that are attributed to him , such as folding screens with pictures of flowers and that birds are painted on them .
There are many works that even experts can not agree if they are really his work or not .
91. Formation sur le modèle de traduction automatique
Apprenez le modèle de traduction automatique neuronale en utilisant les données préparées en> 90 (le modèle du réseau neuronal peut être sélectionné de manière appropriée, comme Transformer ou LSTM).
Prétraitez avec fairseq-preprocess puis entraînez-vous avec fairseq-train.
fairseq-preprocess -s ja -t en \
--trainpref train.spacy \
--validpref dev.spacy \
--destdir data91 \
--thresholdsrc 5 \
--thresholdtgt 5 \
--workers 20
production
Namespace(align_suffix=None, alignfile=None, bpe=None, cpu=False, criterion='cross_entropy', dataset_impl='mmap', destdir='data91', empty_cache_freq=0, fp16=False, fp16_init_scale=128, fp16_scale_tolerance=0.0, fp16_scale_window=None, joined_dictionary=False, log_format=None, log_interval=1000, lr_scheduler='fixed', memory_efficient_fp16=False, min_loss_scale=0.0001, no_progress_bar=False, nwordssrc=-1, nwordstgt=-1, only_source=False, optimizer='nag', padding_factor=8, seed=1, source_lang='ja', srcdict=None, target_lang='en', task='translation', tensorboard_logdir='', testpref=None, tgtdict=None, threshold_loss_scale=None, thresholdsrc=5, thresholdtgt=5, tokenizer=None, trainpref='train.spacy', user_dir=None, validpref='dev.spacy', workers=20)
| [ja] Dictionary: 60247 types
| [ja] train.spacy.ja: 440288 sents, 11298955 tokens, 1.41% replaced by <unk>
| [ja] Dictionary: 60247 types
| [ja] dev.spacy.ja: 1166 sents, 25550 tokens, 1.54% replaced by <unk>
| [en] Dictionary: 55495 types
| [en] train.spacy.en: 440288 sents, 12319171 tokens, 1.58% replaced by <unk>
| [en] Dictionary: 55495 types
| [en] dev.spacy.en: 1166 sents, 26091 tokens, 2.85% replaced by <unk>
| Wrote preprocessed data to data91
fairseq-train data91 \
--fp16 \
--save-dir save91 \
--max-epoch 10 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \
--update-freq 1 \
--dropout 0.2 --weight-decay 0.0001 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 91.log
Les changements de perte pendant l'apprentissage sont envoyés au journal.
92. Application du modèle de traduction automatique
Implémentez un programme qui traduit une phrase japonaise (arbitraire) en anglais à l'aide du modèle de traduction automatique neuronale appris en> 91.
Appliquez le modèle de traduction aux données de test avec fairseq-interactive.
fairseq-interactive --path save91/checkpoint10.pt data91 < test.spacy.ja | grep '^H' | cut -f3 > 92.out
93. Mesure du score BLEU
Mesurez le score BLEU dans les données d'évaluation pour examiner la qualité du modèle de traduction automatique neuronale appris en> 91.
Utilisez fairseq-score. Il existe différents types de BLEU, il peut donc être préférable de spécifier sacrebleu. Traduction automatique Je ne comprends rien. J'espère que vous avez lu la documentation fairseq.
fairseq-score --sys 92.out --ref test.spacy.en
production
Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='92.out')
BLEU4 = 22.71, 53.4/27.8/16.7/10.7 (BP=1.000, ratio=1.009, syslen=27864, reflen=27625)
94. Recherche par faisceau
Introduisez la recherche par faisceau lors du décodage du texte traduit avec le modèle de traduction automatique neuronale appris en> 91. Tracez le changement du score BLEU sur l'ensemble de développement tout en changeant la largeur du faisceau de 1 à 100 selon le cas.
Modifiez la largeur du faisceau de 1 à 20. N'est-ce pas trop long pour atteindre 100?
for N in `seq 1 20` ; do
fairseq-interactive --path save91/checkpoint10.pt --beam $N data91 < test.spacy.ja | grep '^H' | cut -f3 > 94.$N.out
done
for N in `seq 1 20` ; do
fairseq-score --sys 94.$N.out --ref test.spacy.en > 94.$N.score
done
Lisez la partition et faites un graphique.
import matplotlib.pyplot as plt
def read_score(filename):
with open(filename) as f:
x = f.readlines()[1]
x = re.search(r'(?<=BLEU4 = )\d*\.\d*(?=,)', x)
return float(x.group())
xs = range(1, 21)
ys = [read_score(f'94.{x}.score') for x in xs]
plt.plot(xs, ys)
plt.show()
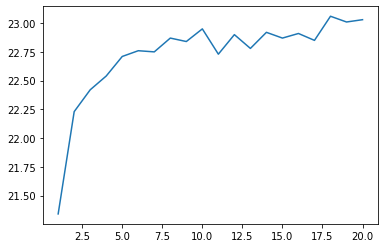
La recherche de faisceau est importante
95. Sous-libellé
Changez l'unité de jeton d'un mot ou d'une morphologie en un sous-mot et répétez l'expérience 91-94.
Le côté japonais a utilisé phrasepiece.
import sentencepiece as spm
spm.SentencePieceTrainer.Train('--input=kftt-data-1.0/data/orig/kyoto-train.ja --model_prefix=kyoto_ja --vocab_size=16000 --character_coverage=1.0')
sp = spm.SentencePieceProcessor()
sp.Load('kyoto_ja.model')
for src, dst in [
('kftt-data-1.0/data/orig/kyoto-train.ja', 'train.sub.ja'),
('kftt-data-1.0/data/orig/kyoto-dev.ja', 'dev.sub.ja'),
('kftt-data-1.0/data/orig/kyoto-test.ja', 'test.sub.ja'),
]:
with open(src) as f, open(dst, 'w') as g:
for x in f:
x = x.strip()
x = re.sub(r'\s+', ' ', x)
x = sp.encode_as_pieces(x)
x = ' '.join(x)
print(x, file=g)
C'est comme ça.
Bateau de neige(14 20 ans(27 années)-150 6 ans(Eisho 3 ans) )Est un peintre à l'encre et un prêtre zen qui était actif à l'époque Muromachi dans la seconde moitié du 15ème siècle, et est également appelé la peinture sacrée.
Cela a changé la peinture à l'encre japonaise.
諱 est "etc. Yang(finalement), Ou "Ma secte(Suite)".
Né en Bi-Chine, a déménagé à Suo-koku après être entré à Kyoto-Sokokuji.
Après cela, il a accompagné le messager en Chine.(Ming)J'ai appris la peinture à l'encre de Chine au fil des ans.
Il y avait de nombreuses œuvres, et non seulement les peintures d'eau de montagne de style chinois, mais aussi les peintures de portrait et les peintures de fleurs et d'oiseaux étaient bonnes.
La composition audacieuse et les coups de pinceau puissants créent un style tout à fait unique.
Six des œuvres existantes ont été désignées comme trésors nationaux, et on peut dire qu'elles ont reçu une évaluation exceptionnelle parmi les peintres japonais.
Pour cette raison, il existe un grand nombre d'œuvres qui ont été "écrites par le bateau des neiges" dans le Kacho Zukanfu.
Il existe de nombreux désaccords parmi les experts, qu'ils soient réels ou non.
La partie anglaise a utilisé subword-nmt.
subword-nmt learn-bpe -s 16000 < kftt-data-1.0/data/orig/kyoto-train.en > kyoto_en.codes
subword-nmt apply-bpe -c kyoto_en.codes < kftt-data-1.0/data/orig/kyoto-train.en > train.sub.en
subword-nmt apply-bpe -c kyoto_en.codes < kftt-data-1.0/data/orig/kyoto-dev.en > dev.sub.en
subword-nmt apply-bpe -c kyoto_en.codes < kftt-data-1.0/data/orig/kyoto-test.en > test.sub.en
comme ça
K@@ n@@ own as Ses@@ shu (14@@ 20 - 150@@ 6@@ ), he was an ink painter and Zen monk active in the Muromachi period in the latter half of the 15th century, and was called a master pain@@ ter.
He revol@@ ut@@ ion@@ ized the Japanese ink paint@@ ing.
He was given the posthumous name "@@ Toyo@@ " or "S@@ es@@ shu (@@je@@Alors@@ )."
Born in Bicchu Province, he moved to Suo Province after entering S@@ Shokoku-ji Temple in Kyoto.
Later he accompanied a mission to Ming Dynasty China and learned Chinese ink paint@@ ing.
His works were man@@ y, including not only Chinese-style landscape paintings, but also portraits and pictures of flowers and bird@@ s.
His b@@ old compos@@ itions and strong brush st@@ rok@@ es const@@ ituted an extremely distinctive style.
6 of his ext@@ ant works are designated national treasu@@ res. In@@ de@@ ed, he is considered to be extraordinary among Japanese pain@@ ters.
For this reason, there are a great many art@@ works that are attributed to him, such as folding scre@@ ens with pictures of flowers and that birds are painted on them.
There are many works that even experts cannot ag@@ ree if they are really his work or not.
Pré-traitement
fairseq-preprocess -s ja -t en \
--trainpref train.sub \
--validpref dev.sub \
--destdir data95 \
--workers 20
Train
fairseq-train data95 \
--fp16 \
--save-dir save95 \
--max-epoch 10 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \
--update-freq 1 \
--dropout 0.2 --weight-decay 0.0001 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 95.log
produire
fairseq-interactive --path save95/checkpoint10.pt data95 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 95.out
Tokenize vers SpaCy
def spacy_tokenize(src, dst):
with open(src) as f, open(dst, 'w') as g:
for x in f:
x = x.strip()
x = ' '.join([doc.text for doc in nlp(x)])
print(x, file=g)
spacy_tokenize('95.out', '95.out.spacy')
Mesurez le score.
fairseq-score --sys 95.out.spacy --ref test.spacy.en
Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='95.out.spacy')
BLEU4 = 20.36, 51.3/25.2/14.7/9.0 (BP=1.000, ratio=1.030, syslen=28463, reflen=27625)
abaissé. Je ne sais pas.
Faites une recherche par faisceau.
for N in `seq 1 10` ; do
fairseq-interactive --path save95/checkpoint10.pt --beam $N data95 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 95.$N.out
done
for i in range(1, 11):
spacy_tokenize(f'95.{i}.out', f'95.{i}.out.spacy')
for N in `seq 1 10` ; do
fairseq-score --sys 95.$N.out.spacy --ref test.spacy.en > 95.$N.score
done
xs = range(1, 11)
ys = [read_score(f'95.{x}.score') for x in xs]
plt.plot(xs, ys)
plt.show()
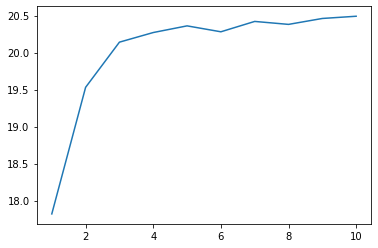
96. Visualisation du processus d'apprentissage
Utilisez des outils tels que Tensorboard pour visualiser le processus par lequel le modèle de traduction automatique neuronale est formé. Utilisez la valeur de la fonction de perte et le score BLEU dans les données d'entraînement, la valeur de la fonction de perte et le score BLEU dans les données de développement, etc. comme éléments à visualiser.
Vous pouvez spécifier --tensorboard-logdir (chemin de sauvegarde) pour fairseq-train.
Vous pouvez le voir en faisant pip install tensorborad tensorboardX, en démarrant tensorboard et en ouvrant localhost: 6666 (etc.).
fairseq-train data95 \
--fp16 \
--tensorboard-logdir log96 \
--save-dir save96 \
--max-epoch 5 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \
--dropout 0.2 --weight-decay 0.0001 \
--update-freq 1 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 96.log
Je pense qu'il sera affiché comme ça.
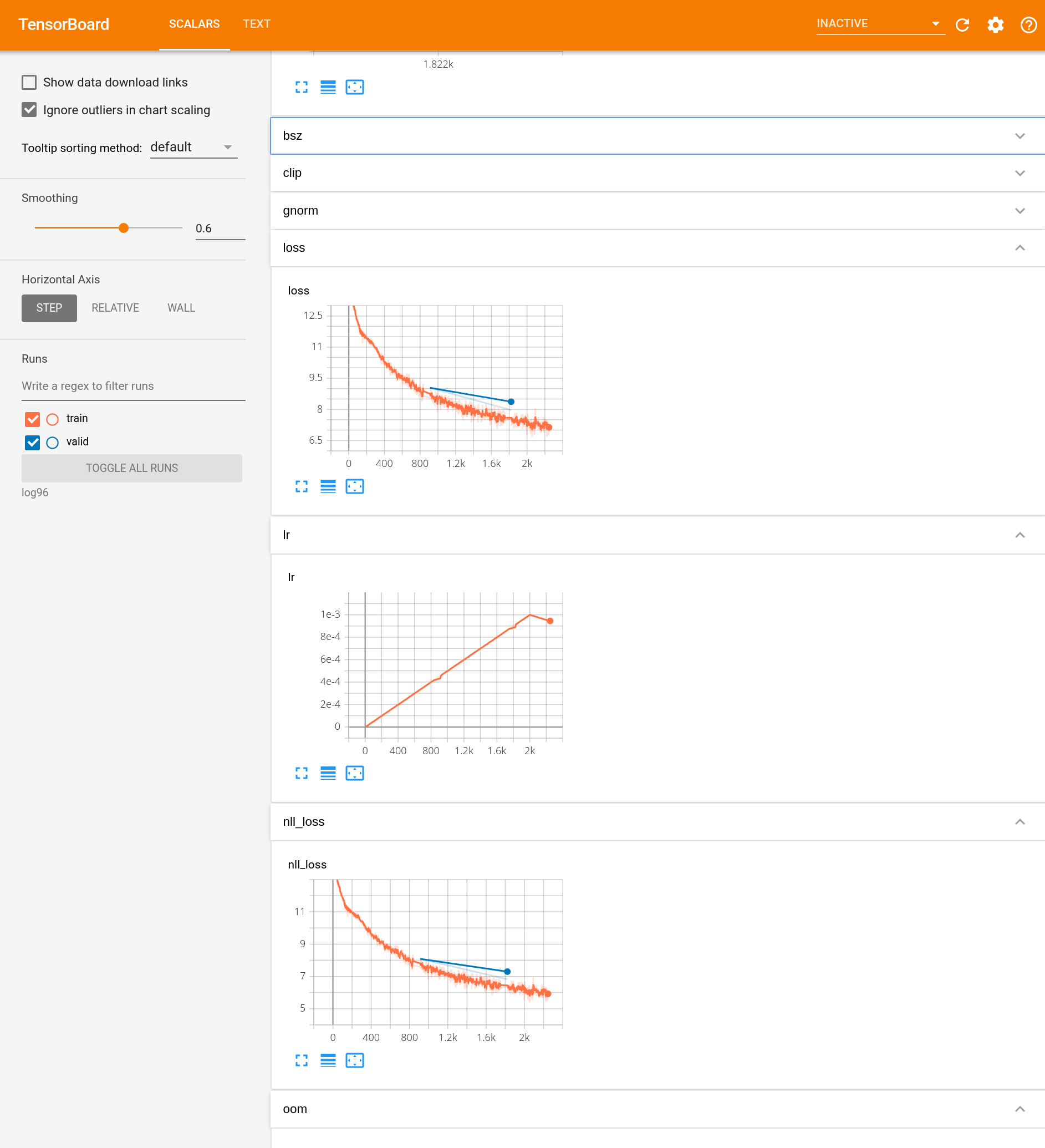
97. Hyper réglage des paramètres
Trouvez le modèle et les hyperparamètres qui maximisent le score BLEU dans les données de développement tout en modifiant le modèle du réseau neuronal et ses hyperparamètres.
Changeons le taux d'abandon et d'apprentissage. Je ne l'ai pas très bien fait. En outre, je regarde BLEU des données de test au lieu des données de développement (pas bon).
fairseq-train data95 \
--fp16 \
--save-dir save97_1 \
--max-epoch 10 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \
--dropout 0.1 --weight-decay 0.0001 \
--update-freq 1 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 97_1.log
fairseq-train data95 \
--fp16 \
--save-dir save97_3 \
--max-epoch 10 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \
--dropout 0.3 --weight-decay 0.0001 \
--update-freq 1 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 97_3.log
fairseq-train data95 \
--fp16 \
--save-dir save97_5 \
--max-epoch 10 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \
--dropout 0.5 --weight-decay 0.0001 \
--update-freq 1 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 97_5.log
fairseq-interactive --path save97_1/checkpoint10.pt data95 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 97_1.out
fairseq-interactive --path save97_3/checkpoint10.pt data95 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 97_3.out
fairseq-interactive --path save97_5/checkpoint10.pt data95 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 97_5.out
spacy_tokenize('97_1.out', '97_1.out.spacy')
spacy_tokenize('97_3.out', '97_3.out.spacy')
spacy_tokenize('97_5.out', '97_5.out.spacy')
fairseq-score --sys 97_1.out.spacy --ref test.spacy.en
fairseq-score --sys 97_3.out.spacy --ref test.spacy.en
fairseq-score --sys 97_5.out.spacy --ref test.spacy.en
Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='97_1.out.spacy')
BLEU4 = 21.42, 51.7/26.3/15.7/9.9 (BP=1.000, ratio=1.055, syslen=29132, reflen=27625)
Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='97_3.out.spacy')
BLEU4 = 12.99, 38.5/16.5/8.8/5.1 (BP=1.000, ratio=1.225, syslen=33832, reflen=27625)
Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='97_5.out.spacy')
BLEU4 = 3.49, 21.8/4.9/1.8/0.8 (BP=1.000, ratio=1.122, syslen=31008, reflen=27625)
Plus le taux d'abandon est élevé, plus le BLEU est bas. Mystère
98. Adaptation du domaine
Corpus de sous-titres japonais-anglais (JESC) et JParaCrawl Essayez d'améliorer les performances des données de test KFTT en utilisant des données de traduction telles que / lilg / jparacrawl /).
Après avoir appris avec JParaCrawl, réapprendrons avec KFTT.
import tarfile
with tarfile.open('en-ja.tar.gz') as tar:
for f in tar.getmembers():
if f.name.endswith('txt'):
text = tar.extractfile(f).read().decode('utf-8')
break
data = text.splitlines()
data = [x.split('\t') for x in data]
data = [x for x in data if len(x) == 4]
data = [[x[3], x[2]] for x in data]
with open('jparacrawl.ja', 'w') as f, open('jparacrawl.en', 'w') as g:
for j, e in data:
print(j, file=f)
print(e, file=g)
Mettez la phrase du côté japonais.
with open('jparacrawl.ja') as f, open('train.jparacrawl.ja', 'w') as g:
for x in f:
x = x.strip()
x = re.sub(r'\s+', ' ', x)
x = sp.encode_as_pieces(x)
x = ' '.join(x)
print(x, file=g)
Multipliez le sous-mot-nmt du côté anglais.
subword-nmt apply-bpe -c kyoto_en.codes < jparacrawl.en > train.jparacrawl.en
Laisse-moi apprendre.
fairseq-preprocess -s ja -t en \
--trainpref train.jparacrawl \
--validpref dev.sub \
--destdir data98 \
--workers 20
fairseq-train data98 \
--fp16 \
--save-dir save98_1 \
--max-epoch 3 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-4 --lr-scheduler inverse_sqrt --warmup-updates 4000 \
--dropout 0.1 --weight-decay 0.0001 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 98_1.log
fairseq-interactive --path save98_1/checkpoint3.pt data98 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 98_1.out
spacy_tokenize('98_1.out', '98_1.out.spacy')
fairseq-score --sys 98_1.out.spacy --ref test.spacy.en
Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='98_1.out.spacy')
BLEU4 = 8.80, 42.9/14.7/6.3/3.2 (BP=0.830, ratio=0.843, syslen=23286, reflen=27625)
Apprenons avec KFTT.
fairseq-preprocess -s ja -t en \
--trainpref train.sub \
--validpref dev.sub \
--tgtdict data98/dict.en.txt \
--srcdict data98/dict.ja.txt \
--destdir data98_2 \
--workers 20
fairseq-train data98_2 \
--fp16 \
--restore-file save98_1/checkpoint3.pt \
--save-dir save98_2 \
--max-epoch 10 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \
--dropout 0.1 --weight-decay 0.0001 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 98_2.log
fairseq-interactive --path save98_2/checkpoint10.pt data98_2 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 98_2.out
spacy_tokenize('98_2.out', '98_2.out.spacy')
fairseq-score --sys 98_2.out.spacy --ref test.spacy.en
Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='98_2.out.spacy')
BLEU4 = 22.85, 54.9/28.0/16.7/10.7 (BP=0.998, ratio=0.998, syslen=27572, reflen=27625)
Votre score s'est un peu amélioré.
Les 90e à 98e questions sautent la recherche des hyper paramètres dans leur ensemble, mais si vous trouvez un meilleur hyper paramètre au chapitre 10 sur 100 coups, veuillez l'écrire dans l'article Qiita.
Vient ensuite "99. Construction du serveur de traduction"
Construisez un système de démonstration dans lequel l'utilisateur saisit la phrase qu'il souhaite traduire et le résultat de la traduction s'affiche sur le navigateur Web.
N ° 99, je le ferai bientôt.
Recommended Posts