100 Language Processing Knock 2020 Chapitre 5: Analyse des dépendances
L'autre jour, 100 Language Processing Knock 2020 a été publié. Je ne travaille moi-même sur le langage naturel que depuis un an, et je ne connais pas les détails, mais je vais résoudre tous les problèmes et les publier afin d'améliorer mes compétences techniques.
Tout doit être exécuté sur le notebook jupyter, et les restrictions de l'énoncé du problème peuvent être brisées de manière pratique. Le code source est également sur github. Oui.
Le chapitre 4 est ici.
L'environnement est Python 3.8.2 et Ubuntu 18.04.
Chapitre 5: Analyse des dépendances
Utilisez CaboCha pour dépendre et analyser le texte (neko.txt) du roman "Je suis un chat" de Natsume Soseki et enregistrer le résultat dans un fichier appelé neko.txt.cabocha. Utilisez ce fichier pour implémenter un programme qui répond aux questions suivantes.
Veuillez télécharger l'ensemble de données requis depuis ici.
Le fichier téléchargé est placé sous «données».
Analyse de dépendance à l'aide de CaboCha
code
cat data/neko.txt | cabocha -f3 > data/neko.txt.cabocha
Vous pouvez produire dans différents formats en spécifiant l'option f, mais cette fois j'ai choisi le format XML.
40. Lecture du résultat de l'analyse des dépendances (morphologie)
Implémentez la classe Morph qui représente la morphologie. Cette classe a une forme de surface (surface), une forme de base (base), une partie du discours (pos) et une sous-classification de partie du discours 1 (pos1) comme variables membres. En outre, lisez le résultat de l'analyse de CaboCha (neko.txt.cabocha), exprimez chaque phrase sous forme d'une liste d'objets Morph et affichez la chaîne d'éléments morphologiques de la troisième phrase.
Une implémentation de la classe «Morph» qui représente la morphologie.
code
class Morph:
def __init__(self, token):
self.surface = token.text
feature = token.attrib['feature'].split(',')
self.base = feature[6]
self.pos = feature[0]
self.pos1 = feature[1]
def __repr__(self):
return self.surface
Lisez XML.
code
import xml.etree.ElementTree as ET
with open("neko.txt.cabocha") as f:
root = ET.fromstring("<sentences>" + f.read() + "</sentences>")
Créez une liste de Morphs pour chaque phrase et stockez-les dans la liste neko.
code
neko = []
for sent in root:
sent = [chunk for chunk in sent]
sent = [Morph(token) for chunk in sent for token in chunk]
neko.append(sent)
La troisième séquence morphologique de l'avant de «neko» est représentée.
code
for x in neko[2]:
print(x)
Lorsque vous imprimez un objet de la classe Morph, __repr__ est appelé et la forme de la surface est affichée.
production
je
Est
Chat
alors
y a-t-il
。
41. Lecture du résultat de l'analyse des dépendances (expression / dépendance)
En plus de> 40, implémentez la classe de clause Chunk. Cette classe contient une liste d'éléments morph (objets Morph) (morphs), une liste de numéros d'index de clause associés (dst) et une liste de numéros d'index de clause d'origine (srcs) associés comme variables membres. De plus, lisez le résultat de l'analyse de CaboCha du texte d'entrée, exprimez une phrase sous forme d'une liste d'objets Chunk et affichez la chaîne de caractères et le contact de la phrase de la huitième phrase. Pour le reste des problèmes du chapitre 5, utilisez le programme créé ici.
Créez une classe de bloc et une classe de phrase. Les contacts de bloc ne sont pas créés lorsque vous créez un objet de bloc, mais sont créés lorsque vous créez un objet d'instruction.
Les blocs et les instructions héritent du type de liste et peuvent être traités comme une liste de morphologie et de blocs, respectivement.
code
import re
class Chunk(list):
def __init__(self, chunk):
self.morphs = [Morph(morph) for morph in chunk]
super().__init__(self.morphs)
self.dst = int(chunk.attrib['link'])
self.srcs = []
def __repr__(self): #Utilisé dans Q42
return re.sub(r'[、。]', '', ''.join(map(str, self)))
Les morceaux sont convertis en une chaîne d'éléments morphologiques concaténés avec «repr». A ce moment, les signes de ponctuation sont supprimés selon la contrainte du problème 42.
code
class Sentence(list):
def __init__(self, sent):
self.chunks = [Chunk(chunk) for chunk in sent]
super().__init__(self.chunks)
for i, chunk in enumerate(self.chunks):
if chunk.dst != -1:
self.chunks[chunk.dst].srcs.append(i)
code
neko = [Sentence(sent) for sent in root]
Vous pouvez maintenant stocker les résultats de l'analyse pour chaque phrase de la liste.
code
from tabulate import tabulate
Utilisez tabulate.tabulate pour l'afficher pour une visualisation facile.
code
table = [
[''.join([morph.surface for morph in chunk]), chunk.dst]
for chunk in neko[7]
]
tabulate(table, tablefmt = 'html', headers = ['nombre', 'Phrase', 'Contact'], showindex = 'always')
production
Clause de nombre
------ ---------- --------
0 J'ai 5 ans
1 ici 2
2 pour la première fois 3
3 humain 4
4 choses 5
5 scie.-1
42. Affichage de la phrase de l'intéressé et de l'intéressé
Extraire tout le texte de la clause originale et de la clause liée au format délimité par des tabulations. Cependant, n'émettez pas de symboles tels que des signes de ponctuation.
code
sent = neko[7]
for chunk in sent:
if chunk.dst != -1:
src = chunk
dst = sent[chunk.dst]
print(f'{src}\t{dst}')
Tout ce que vous avez à faire est d'afficher les blocs et les blocs auxquels ils sont associés sous forme de chaînes pour chaque bloc.
production
j'ai vu
Pour la première fois ici
Pour la première fois appelé humain
Êtres humains
j'ai vu quelque chose
43. Extraire les clauses contenant la nomenclature relative aux clauses contenant des verbes
Lorsque des clauses contenant une nomenclature concernent des clauses contenant des verbes, extrayez-les au format délimité par des tabulations. Cependant, n'émettez pas de symboles tels que des signes de ponctuation.
code
def has_noun(chunk):
return any(morph.pos == 'nom' for morph in chunk)
def has_verb(chunk):
return any(morph.pos == 'verbe' for morph in chunk)
code
sent = neko[7]
for chunk in sent:
if chunk.dst != -1 and has_noun(chunk) and has_verb(sent[chunk.dst]):
src = chunk
dst = sent[chunk.dst]
print(f'{src}\t{dst}')
Créez une fonction pour déterminer si un bloc contient une nomenclature et des verbes, et n'affichez que ceux qui correspondent aux conditions.
production
j'ai vu
Pour la première fois ici
j'ai vu quelque chose
44. Visualisation des arbres dépendants
Visualisez l'arbre de dépendance d'une phrase donnée sous forme de graphe orienté. Pour la visualisation, il est conseillé de convertir l'arborescence de dépendances dans le langage DOT et d'utiliser Graphviz. De plus, pour visualiser des graphiques dirigés directement à partir de Python, utilisez pydot.
code
from pydot import Dot, Edge, Node
from PIL import Image
code
sent = neko[7]
graph = Dot(graph_type = 'digraph')
#Faire un nœud
for i, chunk in enumerate(sent):
node = Node(i, label = chunk)
graph.add_node(node)
#Faire une branche
for i, chunk in enumerate(sent):
if chunk.dst != -1:
edge = Edge(i, chunk.dst)
graph.add_edge(edge)
graph.write_png('sent.png')
Image.open('sent.png')
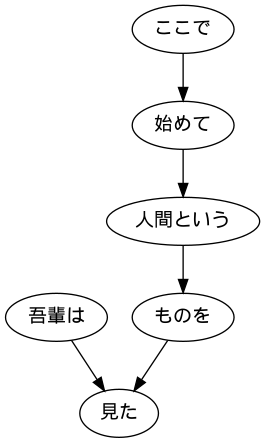
45. Extraction de modèles de cas verbaux
Je voudrais considérer la phrase utilisée cette fois comme un corpus et enquêter sur les cas possibles de prédicats japonais. Considérez le verbe comme un prédicat et le verbe auxiliaire de la phrase liée au verbe comme une casse, et affichez le prédicat et la casse dans un format délimité par des tabulations. Cependant, assurez-vous que la sortie répond aux spécifications suivantes.
・ Dans une phrase contenant un verbe, utilisez la forme de base du verbe le plus à gauche comme prédicat ・ Utilisez les mots auxiliaires liés au prédicat comme cas ・ S'il existe plusieurs mots auxiliaires (phrases) liés au prédicat, arrangez tous les mots auxiliaires dans l'ordre du dictionnaire, séparés par des espaces. Prenons l'exemple de la phrase (8ème phrase de neko.txt.cabocha) que "j'ai vu un être humain pour la première fois ici". Cette phrase contenait deux verbes, "commencer" et "voir", et la phrase liée à "commencer" était analysée comme "ici", et la phrase liée à> "voir" était analysée comme "je suis" et "chose". Dans ce cas, la sortie doit être la suivante.
Démarrer Voir Enregistrez la sortie de ce programme dans un fichier et vérifiez les éléments suivants à l'aide des commandes UNIX.
・ Combinaison de prédicats et de modèles de cas qui apparaissent fréquemment dans le corpus ・ Modèles de casse des verbes "faire", "voir" et "donner" (organiser par ordre de fréquence d'apparition dans le corpus)
code
def get_first_verb(chunk):
for morph in chunk:
if morph.pos == 'verbe':
return morph.base
def get_last_case(chunk):
for morph in chunk[::-1]:
if morph.pos == 'Particule':
return morph.surface
def extract_cases(srcs):
xs = [get_last_case(src) for src in srcs]
xs = [x for x in xs if x]
xs.sort()
return xs
Déterminez si le bloc commence par un verbe et extrayez le verbe du bloc d'origine.
code
with open('result/case_pattern.txt', 'w') as f:
for sent in neko:
for chunk in sent:
if verb := get_first_verb(chunk): #Commencez par un verbe
srcs = [sent[src] for src in chunk.srcs]
if cases := extract_cases(srcs): #Il y a un assistant
line = '{}\t{}'.format(verb, ' '.join(cases))
print(line, file=f)
code
cat result/case_pattern.txt | sort | uniq -c | sort -nr 2> /dev/null | head -n 10
production
2645
1559 Tsukuka
840
553
380 saisir
364 je pense
334 à voir
257
253
Jusqu'à ce qu'il y ait 205
code
cat result/case_pattern.txt | grep 'Faire' | sort | uniq -c | sort -nr 2> /dev/null | head -n 10
production
1239
806
313
140
Jusqu'à 102
84 Qu'est-ce que
59
32
32
24 comme
code
cat result/case_pattern.txt | grep 'à voir' | sort | uniq -c | sort -nr 2> /dev/null | head -n 10
production
334 à voir
121 Voir
40 à voir
25
23 de voir
12 Voir
8 à voir
7 Parce que je vois
3 Juste à la recherche
3 Le regarder
code
cat result/case_pattern.txt | grep 'donner' | sort | uniq -c | sort -nr 2> /dev/null | head -n 10
production
7 pour donner
4 pour donner
3 Que donner
Donnez 1 mais donnez
1 Quant à donner
1 donner
1 donner
46. Extraction d'informations sur le cadre de la casse verbale
Modifiez le programme> 45 et affichez les termes (les clauses liées aux prédicats eux-mêmes) au format délimité par des tabulations en suivant les prédicats et les modèles de cas. En plus des 45 spécifications, répondez aux spécifications suivantes.
・ Le terme est une chaîne de mots de la phrase liée au prédicat (il n'est pas nécessaire de supprimer le mot auxiliaire de fin) ・ S'il existe plusieurs clauses liées au prédicat, disposez-les dans le même standard et dans le même ordre que les mots auxiliaires, séparés par des espaces. Prenons l'exemple de la phrase (8ème phrase de neko.txt.cabocha) que "j'ai vu un être humain pour la première fois ici". Cette phrase contient deux verbes, «commencer» et «voir», et la phrase liée à «commencer» est analysée comme «ici», et la phrase liée à «voir» est analysée comme «je suis» et «chose». Devrait produire la sortie suivante.
Commencez ici Voir ce que je vois
code
def extract_args(srcs):
xs = [src for src in srcs if get_last_case(src)]
xs.sort(key = lambda src : get_last_case(src))
xs = [str(src) for src in xs]
return xs
Modifiez le code de la question 45 pour afficher également le bloc d'origine.
code
for sent in neko[:10]:
for chunk in sent:
if verb := get_first_verb(chunk): #Commence par un verbe
srcs = [sent[src] for src in chunk.srcs]
if cases := extract_cases(srcs): #Il y a un assistant
args = extract_args(srcs)
line = '{}\t{}\t{}'.format(verb, ' '.join(cases), ' '.join(args))
print(line)
production
Où naître
Je ne sais pas s'il est né
Où pleurer
La seule chose que je pleurais
Commencez ici
Regarde ce que je vois
Écoutez plus tard
Attrapez-nous
Faire bouillir et attraper
Manger et bouillir
47. Exploration de la syntaxe des verbes fonctionnels
Je voudrais faire attention uniquement lorsque le verbe wo case contient un nom de connexion sa-variant. Modifiez 46 programmes pour répondre aux spécifications suivantes.
・ Uniquement lorsque la phrase consistant en "Sahen connectant le nom + (auxiliaire)" est liée au verbe ・ Le prédicat est "nom de connexion sahen + est la forme de base du + verbe", et lorsqu'il y a plusieurs verbes dans la phrase, le verbe le plus à gauche est utilisé. ・ S'il y a plusieurs mots auxiliaires (phrases) liés au prédicat, arrangez tous les mots auxiliaires dans l'ordre du dictionnaire, séparés par des espaces. ・ S'il y a plusieurs clauses liées au prédicat, arrangez tous les termes séparés par des espaces (alignez-vous sur l'ordre des mots auxiliaires). ・ Par exemple, la sortie suivante doit être obtenue à partir de la phrase "Le maître répondra à la lettre, même si elle vient à un autre endroit."
En répondant, le propriétaire a dit à la lettre Enregistrez la sortie de ce programme dans un fichier et vérifiez les éléments suivants à l'aide des commandes UNIX.
・ Prédicats qui apparaissent fréquemment dans le corpus ・ Prédicats et modèles d'assistant qui apparaissent fréquemment dans le corpus
code
def is_sahen(chunk):
return len(chunk) == 2 and chunk[0].pos1 == 'Changer de connexion' and chunk[1].surface == 'À'
def split_sahen(srcs):
for i in range(len(srcs)):
if is_sahen(srcs[i]):
return str(srcs[i]), srcs[:i] + srcs[i+1:]
return None, srcs
Avec split_sahen, le bloc sous la forme de" verbe de connexion Sahen + ~ "est extrait du bloc original du bloc contenant le verbe.
code
with open('result/sahen_pattern.txt', 'w') as f:
for sent in neko:
for chunk in sent:
if verb := get_first_verb(chunk):
srcs = [sent[src] for src in chunk.srcs]
sahen, rest = split_sahen(srcs)
if sahen and (cases := extract_cases(rest)):
args = extract_args(rest)
line = '{}\t{}\t{}'.format(sahen + verb, ' '.join(cases), ' '.join(args))
print(line, file=f)
code
cat result/sahen_pattern.txt | cut -f 1 | sort | uniq -c | sort -nr 2> /dev/null | head -n 10
production
25 réponse
19 Dites bonjour
11 parler
9 Poser une question
7 imiter
7 querelle
5 Poser une question
5 Consulter
5 Faites une sieste
4 Donner un discours
code
cat result/sahen_pattern.txt | cut -f 1,2 | sort | uniq -c | sort -nr 2> /dev/null | head -n 10
production
10 Lorsque vous répondez
7 Qu'est-ce qu'une réponse?
7 Dites bonjour
5 Poser une question
5 Dans une querelle
4 Poser une question
4 pour parler
4 Je vais dire bonjour
3 Parce que je vais répondre
3 Écoutez le discours
48. Extraction des chemins de la nomenclature aux racines
Pour une clause contenant toute la nomenclature de la phrase, extrayez le chemin de cette clause jusqu'à la racine de l'arbre de syntaxe. Cependant, le chemin sur l'arbre de syntaxe doit satisfaire aux spécifications suivantes.
・ Chaque clause est représentée par une séquence morphologique (de la couche superficielle) ・ De la clause de début à la clause de fin du chemin, connectez les expressions de chaque clause avec "->" A partir de la phrase "J'ai vu un être humain pour la première fois ici" (8ème phrase de neko.txt.cabocha), le résultat suivant devrait être obtenu.
J'ai vu-> Ici-> pour la première fois-> humain-> j'ai vu quelque chose-> J'ai vu un humain-> chose-> J'ai vu quelque chose->
code
def trace(n, sent):
path = []
while n != -1:
path.append(n)
n = sent[n].dst
return path
code
sent = neko[7]
heads = [n for n in range(len(sent)) if has_noun(sent[n])]
for head in heads:
path = trace(head, sent)
path = ' -> '.join([str(sent[n]) for n in path])
print(path)
Trouvez tous les numéros de bloc avec la nomenclature et obtenez le chemin sous forme de liste de numéros de bloc tout en traçant chaque contact. Enfin, les morceaux doivent être affichés dans l'ordre des chemins.
production
je suis->vu
ici->Commencer avec->Humain->Des choses->vu
Humain->Des choses->vu
Des choses->vu
49. Extraction de chemins de dépendance entre nomenclature
Extraire le chemin de dépendance le plus court qui relie toutes les paires de nomenclatures de la phrase. Cependant, lorsque les numéros de clause de la paire de nomenclatures sont i et j (i <j), le chemin de dépendance doit satisfaire aux spécifications suivantes.
・ Similaire au problème 48, le chemin exprime la représentation de chaque clause de la clause de début à la clause de fin (chaîne d'élément de forme de couche de surface) en les concaténant avec "->". ・ Remplacer la nomenclature contenue dans les clauses i et j par X et Y, respectivement. De plus, la forme du chemin de dépendance peut être considérée des deux manières suivantes.
・ Lorsque la clause j existe sur la route de la clause i à la racine de l'arbre de syntaxe: Afficher le chemin de la clause i à la clause j ・ Autre que ce qui précède, lorsque la clause i et la clause j se croisent à une clause commune k sur le chemin de la clause j à la racine de l'arbre de syntaxe: le chemin immédiatement avant la clause i vers la clause k et le chemin immédiatement avant la clause j vers la clause k, Afficher le contenu de la clause k en les concaténant avec "|" Par exemple, à partir de la phrase "J'ai vu un être humain pour la première fois ici" (8ème phrase de neko.txt.cabocha), la sortie suivante devrait être obtenue.
X est|En Y->Commencer avec->Humain->Des choses|vu X est|Appelé Y->Des choses|vu X est|Oui|vu Avec X-> Pour la première fois-> Y Avec X-> Pour la première fois-> Humain-> Y X-> Y
code
def extract_path(x, y, sent):
xs = []
ys = []
while x != y:
if x < y:
xs.append(x)
x = sent[x].dst
else:
ys.append(y)
y = sent[y].dst
return xs, ys, x
def remove_initial_nouns(chunk):
for i, morph in enumerate(chunk):
if morph.pos != 'nom':
break
return ''.join([str(morph) for morph in chunk[i:]]).strip()
def path_to_str(xs, ys, last, sent):
xs = [sent[x] for x in xs]
ys = [sent[y] for y in ys]
last = sent[last]
if xs and ys:
xs = ['X' + remove_initial_nouns(xs[0])] + [str(x) for x in xs[1:]]
ys = ['Y' + remove_initial_nouns(ys[0])] + [str(y) for y in ys[1:]]
last = str(last)
return ' -> '.join(xs) + ' | ' + ' -> '.join(ys) + ' | ' + last
else:
xs = xs + ys
xs = ['X' + remove_initial_nouns(xs[0])] + [str(x) for x in xs[1:]]
last = 'Y' + remove_initial_nouns(last)
return ' -> '.join(xs + [last])
code
sent = neko[7]
heads = [n for n in range(len(sent)) if has_noun(sent[n])]
print('Le début du chemin:', heads)
pairs = [
(heads[n], second)
for n in range(len(heads))
for second in heads[n + 1:]
]
print('Première paire de chemins: ', pairs)
print('Carte de dépendance:')
for x, y in pairs:
x_path, y_path, last = extract_path(x, y, sent)
path = path_to_str(x_path, y_path, last, sent)
print(path)
Nous obtenons d'abord une liste de nombres de blocs avec nomenclature.
Ensuite, vous obtenez toutes les paires de ce morceau.
Ensuite, pour chaque paire, le chemin est calculé jusqu'à ce que le même morceau soit atteint, et il est spécifié par path_to_str basé sur chaque cheminx_path, y_path et le dernier bloc commun en dernier. Converti au format.
production
Le début du chemin: [0, 1, 3, 4]
Première paire de chemins: [(0, 1), (0, 3), (0, 4), (1, 3), (1, 4), (3, 4)]
Carte de dépendance:
X est|En Y->Commencer avec->Humain->Des choses|vu
X est|Appelé Y->Des choses|vu
X est|Oui|vu
En X->Commencer avec->Appelé Y
En X->Commencer avec->Humain->Oui
Appelé X->Oui
Vient ensuite le chapitre 6
Traitement du langage 100 Knock 2020 Chapitre 6: Apprentissage automatique
Recommended Posts