Scraping a website using JavaScript in Python
Overview
I scraped a site that makes DOM with JavaScript using Python, so make a note of the procedure.
Roughly, I did a combination of Scrapy and Selenium.
Scrapy
Scrapy is a framework for implementing crawlers.
Implement the crawler as a class that satisfies the interface determined by the framework, such as the crawler as a subclass of * Spider *, the scraped information as a subclass of * Item *, and the processing for scraped information as a subclass of * Pipeline *.
A command called * scrapy * is provided that allows you to see a list of crawlers you've created and launch crawlers.
Selenium
Selenium is a tool for programmatically controlling the browser (is it okay?). It can be used in various languages including Python. Often used in website / app automated testing contexts. You can use it to execute JavaScript and scrape HTML sources, including dynamically generated DOM.
Originally it seemed to control the browser via JavaScript, but now it sends a message directly to the browser to control the browser.
When I tried it in my environment (OSX), I couldn't use it in Safari and Chrome without installing something like an extension. You can use it as it is in Firefox. If you include PhantomJS, you can scrape without a window, so you can use it on the server.
Why use scrapy
You can scrape with Selenium alone without using Scrapy,
--Scraping multiple pages in parallel (multithreading? Process?), ――How many pages were crawled, how many times the error occurred, and the log is nicely summarized. --Avoids duplication of crawled pages, ――It provides various setting options such as crawl interval. --Combine CSS and XPath to get out of the DOM (combination is quite convenient!), --You can spit out the crawl result in JSON or XML, --You can write a crawler with a nice program design (I think it's better than designing it yourself),
The merit of using Scrapy that comes to mind is like this.
At first, studying the framework was a hassle, so I implemented the crawler only with Selenium and PyQuery, but if I wrote logs and error handling , The feeling of reinventing the wheel became stronger and I stopped.
Before implementation, I read the Scrapy documentation from the beginning to the Settings page, as well as * Architecture overview * and * Downloader Middleware *.
Use Scrapy and Selenium in combination
The original story is this stack overflow.
Scrapy's architecture looks like this (from Scrapy documentation).
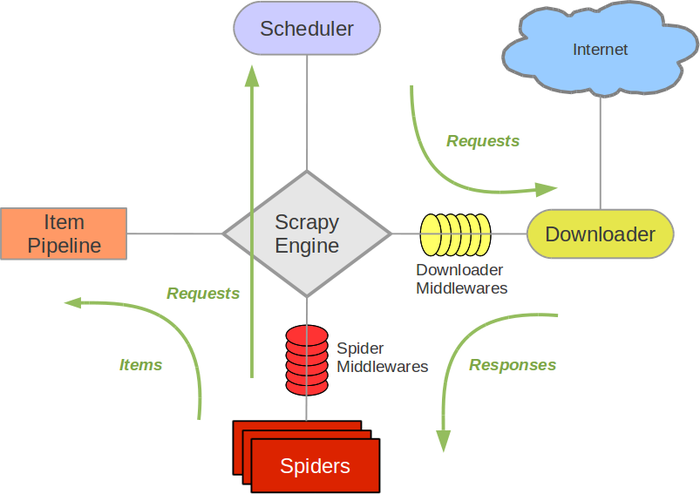
Customize * Downloader Middlewares * to allow Scrapy's Spider to scrape using Selenium.
Downloader Middleware implementation
Downloader Middleware is implemented as an ordinary class that implements * process_request *.
selenium_middleware.py
# -*- coding: utf-8 -*-
import os.path
from urlparse import urlparse
import arrow
from scrapy.http import HtmlResponse
from selenium.webdriver import Firefox
driver = Firefox()
class SeleniumMiddleware(object):
def process_request(self, request, spider):
driver.get(request.url)
return HtmlResponse(driver.current_url,
body = driver.page_source,
encoding = 'utf-8',
request = request)
def close_driver():
driver.close()
If you register this Download Middleware, * Spider * will call * process_request * before scraping the page. For more information, click here (http://doc.scrapy.org/en/1.0/topics/downloader-middleware.html).
Since it is returning an instance of * HtmlResponse *, Download Middleware will not be called after that. Depending on the priority setting, Default Donwload Middleware (such as parsing robots.txt) may be Note that it will not be called.
Above, I'm using Firefox, but if I want to use PhantomJS, rewrite the * driver * variable.
Download Middleware registration
Register * Selenium Middleware * in the * Spider * class you want to use.
some_spider.py
# -*- coding: utf-8 -*-
import scrapy
from ..selenium_middleware import close_driver
class SomeSpider(scrapy.Spider):
name = "some_spider"
allowed_domains = ["somedomain"]
start_urls = (
'http://somedomain/',
)
custom_settings = {
"DOWNLOADER_MIDDLEWARES": {
"some_crawler.selenium_middleware.SeleniumMiddleware": 0,
},
"DOWNLOAD_DELAY": 0.5,
}
def parse(self, response):
#Crawler processing
def closed(self, reason):
close_driver()
- DOWNLOADER_MIDDLEWARES * in * custom_settings * is the setting. In order to close the Firefox window used for scraping, I am writing the processing of the * close * method.
Recommended Posts