I used to scrape with VBA, but I don't know how long Internet Explorer can be used.
So I started scraping ** Chrome ** with ** Python **.
The environment is ** Windows **.
It's more content now, but I'll write down the basics that you should keep in mind (probably the content that you will forget in a few months) as a personal reminder.
**
[1. Install selenium](# 1-Install selenium)
[2. Download WebDriver](# 2-Download webdriver)
[3. Source code description](# 3-Source code description)
1. Install selenium
First, install a browser-controlling package called selenium in Python.
You can install it by typing the command py -m pip install selenium from the command prompt as follows:
command prompt
>py -m pip install selenium
Collecting selenium
Downloading selenium-3.141.0-py2.py3-none-any.whl (904 kB)
|████████████████████████████████| 904 kB 1.1 MB/s
Collecting urllib3
Downloading urllib3-1.25.11-py2.py3-none-any.whl (127 kB)
|████████████████████████████████| 127 kB 939 kB/s
Installing collected packages: urllib3, selenium
Successfully installed selenium-3.141.0 urllib3-1.25.11
For details, including how to install Python itself, see here.
2. Download WebDriver
Next, you will need ** WebDriver ** for your browser type.
● Reference books
[Hidekatsu Nakajima "Book that automates Excel, email, and the Web with Python" SB Creative](https://www.amazon.co.jp/Python%E3%81%A7Excel%E3%80%81%E3%83% A1% E3% 83% BC% E3% 83% AB% E3% 80% 81Web% E3% 82% 92% E8% 87% AA% E5% 8B% 95% E5% 8C% 96% E3% 81% 99% E3% 82% 8B% E6% 9C% AC-% E4% B8% AD% E5% B6% 8B% E8% 8B% B1% E5% 8B% 9D / dp / 4815606390)
2-1. Download site
Open the Chrome Driver Downloads page (https://sites.google.com/a/chromium.org/chromedriver/downloads) that looks like this:
 In the red frame above, there are three versions (87, 86, 85) of Chrome Driver.
Of these, you will download the one that matches the version of Chrome you are currently using (see next section).
In the red frame above, there are three versions (87, 86, 85) of Chrome Driver.
Of these, you will download the one that matches the version of Chrome you are currently using (see next section).
You can check the WebDriver link for each browser from the Driver section of" PyPI / selenium ".
2-2. Check Chrome version
You can check the version by opening "About Google Chrome (G)" from "Help (H)" in the Chrome browser menu.
 In my environment, the version of Chrome is
In my environment, the version of Chrome is 86, so from the download site I mentioned earlier, click the corresponding Chrome Driver 86.0.4240.22.
2-3. Acquisition of WebDriver
When you see a screen like the one below, click on the Chrome Driver for Windows to install it.
 If you unzip the downloaded file, you will get a WebDriver called
If you unzip the downloaded file, you will get a WebDriver called chromedriver.exe as follows.
 You will use this Driver in the same folder as the Python source code file (you can put it in a different folder and specify the path in the source code).
You will use this Driver in the same folder as the Python source code file (you can put it in a different folder and specify the path in the source code).
3. Source code description
Here's the code that opens the yahoo site and performs a search:
Test01.py
import time
from selenium import webdriver
driver = webdriver.Chrome() #Create an instance of WebDriver
driver.get('https://www.yahoo.co.jp/') #Open the browser by specifying the URL
time.sleep(2) #Wait 2 seconds
search_box = driver.find_element_by_name('p') #Identify the search box with the name attribute
search_box.send_keys('Scraping') #Enter text in the search box
search_box.submit() #Send search wording (same as pressing the search button)
time.sleep(2) #Wait 2 seconds
driver.quit() #Close browser
This is a minor modification of the code on the ChromeDriver site (http://chromedriver.chromium.org/getting-started).
When executed, the browser (Chrome) will be launched and the word "scraping" will be searched from the yahoo site.
Below, I will leave a brief explanation.
3-1. Importing the library
Sample.py
import time
from selenium import webdriver
Basically, it is described by the correspondence of import [library name].
The first line imports the standard library time.
The second line imports a library called webdriver from the package selenium you just installed.
3-2. Creating an instance of WebDriver
3-2-1. When the driver is saved in the same folder as the source code
If ChromeDriver is saved in the same folder as the source code, you can create an instance of WebDriver by writing as follows.
Sample.py
driver = webdriver.Chrome()
3-2-2. When the driver is saved in a folder different from the source code
If the driver is saved in the directory (folder) below, write as follows.
Sample.py
driver = webdriver.Chrome('Driver/chromedriver')
The above Driver is the directory name (folder name).
3-2-3. About instance variable names
Note that the variable driver can be anything (of course).
It's okay to set the variable to d as follows:
Sample.py
d = webdriver.Chrome()
3-3. Open the browser by specifying the URL
You can open the specified site by writing [instance name] .get ([URL name]) as follows.
Sample.py
driver.get('https://www.yahoo.co.jp/')
3-4. Get the node
3-4-1. Checking HTML
In order to perform the search, you need to read the text box location to enter thesearch wording, such as:  You will get this by looking at the HTML of the web page. To see the HTML in the text box, right-click on it and select Validate. 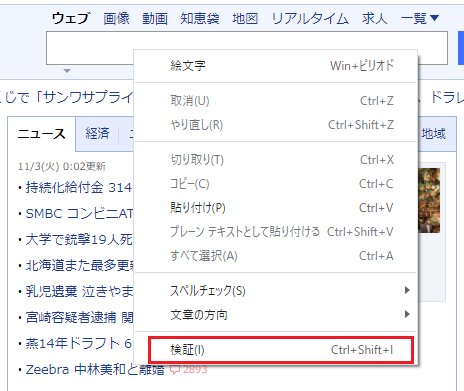 Then the HTML of the site will be displayed on the right side. The part that is blue is the HTML of the relevant part. 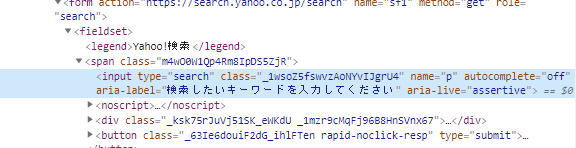 In this HTML, attribute values such astype, class, and name are specified in the tag input`.
Using these tag names and attribute values as clues, you will specify the required parts (nodes).
The same tag name and attribute value may be duplicated, so first find the one that is unique (there is only one on the page).
Upon checking, I found that there is only one of the following class and name in the page.
class="_1wsoZ5fswvzAoNYvIJgrU4"
name="p"
3-4-2. Source code to get the node
Here, using the simpler attribute value of name, get the necessary part (node) with the following code.
Since search_box is a variable, it can be an alias.
Sample.py
search_box = driver.find_element_by_name('p')
If you want to get a node with the attribute value of name, describe it with the arrangement of[instance name] .find_element_by_name ([attribute value]).
If you want to get the attribute value of class, write as follows.
Sample.py
search_box = driver.find_element_by_class_name('_1wsoZ5fswvzAoNYvIJgrU4')
3-4-3. Method for getting node
There are several methods to get the node besides name and class (this site). reference).
3-4-3-1. When acquiring a single node
| Method |
Acquisition target |
| find_element_by_id |
id name (attribute value) |
| find_element_by_name |
name name (attribute value) |
| find_element_by_xpath |
Get with XPath |
| find_element_by_link_text |
Get with link text |
| find_element_by_partial_link_text |
Get as part of the link text |
| find_element_by_tag_name |
Tag name (element) |
| find_element_by_class_name |
class name (attribute value) |
| find_element_by_css_selector |
Get with selector |
When fetching in the singular, only the first node found is retrieved, even if there is one with the same name.
If you are not familiar with XPath like me, please refer to this article "Required for crawler creation! XPATH notation summary". .. I think it will be very convenient if you can master it.
3-4-3-2. When acquiring multiple nodes (list)
| Method |
Acquisition target |
| find_elements_by_name |
id name (attribute value) |
| find_elements_by_xpath |
name name (attribute value) |
| find_elements_by_link_text |
Get with link text |
| find_elements_by_partial_link_text |
Get as part of the link text |
| find_elements_by_tag_name |
Tag name (element) |
| find_elements_by_class_name |
class name (attribute value) |
| find_elements_by_css_selector |
Get with selector |
When fetching in singular, all nodes with the same name are fetched in list format.
In the original HTML description, there is a rule that id name can be one in one page, class name, name name can be multiple, etc., but some sites have multiple id names. Therefore, there are multiple (list) acquisition methods such as find_elements_by_name.
In the case of multiple acquisition, since the nodes are acquired in list format, it is necessary to specify up to the element number as follows.
Sample.py
search_box = driver.find_elements_by_name('p')[0]
3-4-4. [Reference] Get the node (below the child element) of the node
When you get a node, you can easily write the code if you have a unique id name etc., but sometimes it is not so convenient.
In such a case, it is often the case that a node with a large range is specified once and the node of its child element (grandchild element) is specified, such as by performing a refined search.
The method of getting the node of the node can be realized by simply concatenating the methods as follows.
Sample.py
search_box = driver.find_element_by_tag_name('fieldset').find_element_by_tag_name('input')
It is also possible to write variables separately (below).
Sample.py
search_box1 = driver.find_element_by_tag_name('fieldset')
search_box = search_box1.find_element_by_tag_name('input')
In the second refinement, the nodes below the child element are targeted.
3-5. Enter text in the search box
To enter text in the search box, use the send_keys method and write:
Here, the word "scraping" is entered in the text box.
Sample.py
search_box.send_keys('Scraping')
3-6. Perform search
By using the submit method as follows, you can send the text entered in the search form to the website server (that is, execute the search).
Sample.py
search_box.submit()
This means that you are sending HTML form data to the server.
You can get the same result by simply executing the command "click the search button" as shown below.
Sample.py
search_box = driver.find_element_by_class_name('PHOgFibMkQJ6zcDBLbga8').click()
This means that the node is acquired by the class name for the search button, and the search button is clicked by the click method.
3-7. Close your browser
You can close the open browser with the following code.
Sample.py
driver.quit()
finally
Is the above the basic basics?
While writing this, I wondered how to get innerText and outerHTML, but methods were prepared normally in this area as well.
Python scraping is used by many people, so it seems to be fairly easy to use.