Recherche de blogs techniques par machine learning en mettant l'accent sur la "facilité de compréhension"
Je veux acquérir de nouvelles technologies! Même si vous le recherchez, il arrive souvent que les articles qui arrivent en tête de la recherche ne soient pas "faciles à comprendre". Le nombre de vues de l'article, le nombre de likes et le nombre de likes de Qiita peuvent être utilisés comme référence, mais cela ne signifie pas qu'il devrait être élevé en tant que sentiment.
Alors, pouvons-nous évaluer non seulement la "réputation" de ces phrases, mais aussi la composition et le style d'écriture des phrases elles-mêmes, et évaluer leur "facilité de compréhension"? Donc, ce que j'ai essayé expérimentalement est le suivant "Elephant Sense".
chakki-works/elephant_sense (Ce sera encourageant si vous me donnez une étoile m (_ _) m)

- Le nom vient de l'histoire selon laquelle la sensation d'un éléphant est en fait incroyable.
Pendant le développement, nous avons suivi la procédure de base de traitement du langage naturel / apprentissage automatique, je voudrais donc présenter le processus dans cet article.
objectif
À l'avance, j'ai essayé de savoir à quel point il est facile de comprendre les articles de Qiita en «cherchant simplement» et en «extrayant ceux qui ont un nombre élevé de likes» (pour le moment). «Facile à comprendre» a été évalué subjectivement. Dans les phases suivantes, je vais expliquer comment gérer ce sentiment). En conséquence, il a été constaté que la situation est la suivante.

Il semblait que la situation était que même si nous extrayions en fonction des likes, cela n'atteindrait pas 50%, nous nous sommes donc fixé comme objectif d'en rendre la moitié facile à comprendre.

Recherche précédente
Il existe des études antérieures sur l'évaluation de la compréhensibilité des phrases. Les deux indicateurs suivants sont connus dans le monde anglophone («Evaluation index for readability (1)) Je connais le blog).
- Flesch Reading Ease
- Calculé en utilisant le nombre de mots par phrase (longueur de phrase) et le nombre de syllabes par mot
- Flesch-Kincaid Grade Level
- Utilise les mêmes fonctionnalités que Flesch Reading Ease, mais une valeur inférieure est pour les notes plus élevées (= difficile)
En d'autres termes, "une longue phrase remplie de nombreux mots est difficile à comprendre". Au contraire, si la longueur de la phrase est appropriée et que le nombre de mots utilisés est globalement petit, le score sera bon. D'ailleurs, MS Word peut calculer cet index. Ce peut être une bonne idée de l'essayer.
Le but de cet index est principalement de mesurer la difficulté des textes, par exemple si une phrase spécifique est destinée aux élèves du primaire ou du secondaire. Il y a les efforts de recherche suivants au Japon.
- Laboratoire de recherche sur la lisibilité technologique de l'Université de Nagaoka
- Mesure de la difficulté des textes japonais au laboratoire Sato / Matsuzaki, Département des systèmes d'information électroniques, École supérieure d'ingénierie, Université de Nagoya
Cependant, puisque rien n'est supposé être une phrase de type manuel, le score est grandement influencé par le rapport entre les kanji éducatifs et les hiragana contenus dans la phrase, et il est écrit en notation standard comme ce blog technique. J'ai l'impression qu'il y a une limite à mesurer et à estimer le niveau de phrase des textes existants (ce point est "[À propos des phrases faciles à lire pour les apprenants japonais](https://www.ninjal.ac.jp/event/specialists] /project-meeting/files/JCLWorkshop_no2_papers/JCLWorkshop2012_2_34.pdf) ”).
En guise d'étude approfondie, une étude a été menée sur la mesure de la compréhensibilité des manuels informatiques suivants.
Méthode d'évaluation quantitative pour la compréhensibilité du manuel informatique
Cette étude présente les deux perspectives suivantes sur la qualité de l'expression dans le manuel.
- Exactitude de l'expression: exactitude du contenu, correction de la notation (erreur grammaticale, etc.)
- Qualité d'expression: Facile à comprendre, facile à lire, facile à utiliser (recherche), graphiques concrets, exemples appropriés, etc.
En termes de blogs techniques, il y a deux points: "Le contenu que vous écrivez est-il correct?" Et "Le style d'écriture est-il approprié?" À l'instar de cette étude, nous nous concentrerons cette fois sur la «qualité de l'expression» (car des connaissances externes sont nécessaires pour déterminer si l'expression est exacte). Comme cela sera décrit plus loin, nous nous sommes également référés à cette recherche pour les quantités de caractéristiques à utiliser.
De plus, je lis brièvement les articles suivants comme une étude sur les caractéristiques des phrases (se référer au dernier NIPS / EMNLP).
- Document Summarization Using Sentence Features
- Extractive Summarization Using Supervised and Semi-supervised Learning
- Recognizing contextual polarity in phrase-level sentiment analysis
- Analyzing Linguistic Knowledge in Sequential Model of Sentence
Préparation des données
J'ai décidé d'utiliser l'apprentissage automatique cette fois-ci, j'ai donc besoin de données de toute façon. Plus précisément, ce sont des données qui ont été annotées telles que "Cet article est facile à comprendre / difficile à comprendre".
Il est généralement important de bien concevoir la tâche avant de l'annoter.
Spécification d'annotation du corpus de texte NAIST
Cette méthode est très bien organisée dans les livres suivants, c'est donc une bonne idée de la lire une fois lors de l'annotation de données texte.
Natural Language Annotation for Machine Learning
Cette fois, nous avons décidé d'utiliser "facile à comprendre" comme norme pour "les juniors peuvent-ils le lire?" Ceci pour éviter de masquer la clarté des connaissances de l'annotateur. Et j'ai décidé de l'évaluer sur 0/1. En effet, il était difficile de définir le stade et seuls trois membres de l'équipe pouvaient être mobilisés pour l'évaluation, il fallait donc le rendre le plus stable possible (je l'ai écrit à la légère, mais cela "facile à comprendre" Il y a eu beaucoup de débats sur la façon d'annoter).
J'ai également décidé de prendre le corpus cible de Qiita. En d'autres termes, cette fois, le but est "d'évaluer si les articles de Qiita peuvent ou non être lus par les juniors sur 0/1" et de prédire le score pour "augmenter le nombre d'articles qui se sentent faciles à comprendre à 50%". (D'après le livre ci-dessus, il était important que le travail d'annotation et la tâche à accomplir au-delà soient correctement liés).
L'annotation a été faite pour 100 articles. Cependant, si vous sélectionnez les articles au hasard, la plupart des articles auront un petit nombre de likes, alors j'ai ajusté cela. Le résultat final de l'annotation est le suivant (3 est MAX (tous ajoutés 1) car cela a été fait par 3 personnes).

Nous allons construire un modèle en utilisant ces données.
Construire un modèle
Si vous êtes accro aux réseaux de neurones, vous avez tendance à y entrer avec Word2Vec et à l'encoder avec RNN, mais cette fois j'ai décidé de créer un modèle qui serait la référence.
Les quantités de caractéristiques sélectionnées comme candidats en référence à des recherches antérieures sont les suivantes.
- Length Feature
- Durée de la peine (moyenne / maximum / minimum)
- Longueur de la tête
- Longueur de section
- Durée de la peine
- Counting Feature
- Nombre de mots
- Mot TF / IDF
- Ratio Hiragana / Katakana / Kanji / Alphabet / Nombre
- Nombre de signes de ponctuation
- Nombre de sauts de ligne
- Nombre de mots mis en évidence (crochet clé / paire de guillemets doubles)
- Nombre / ratio de puces (par rapport au nombre total de phrases)
- Nombre et ratio de titres (par rapport au nombre total de phrases)
- Nombre de chiffres (image) / ratio (par rapport au nombre total de phrases)
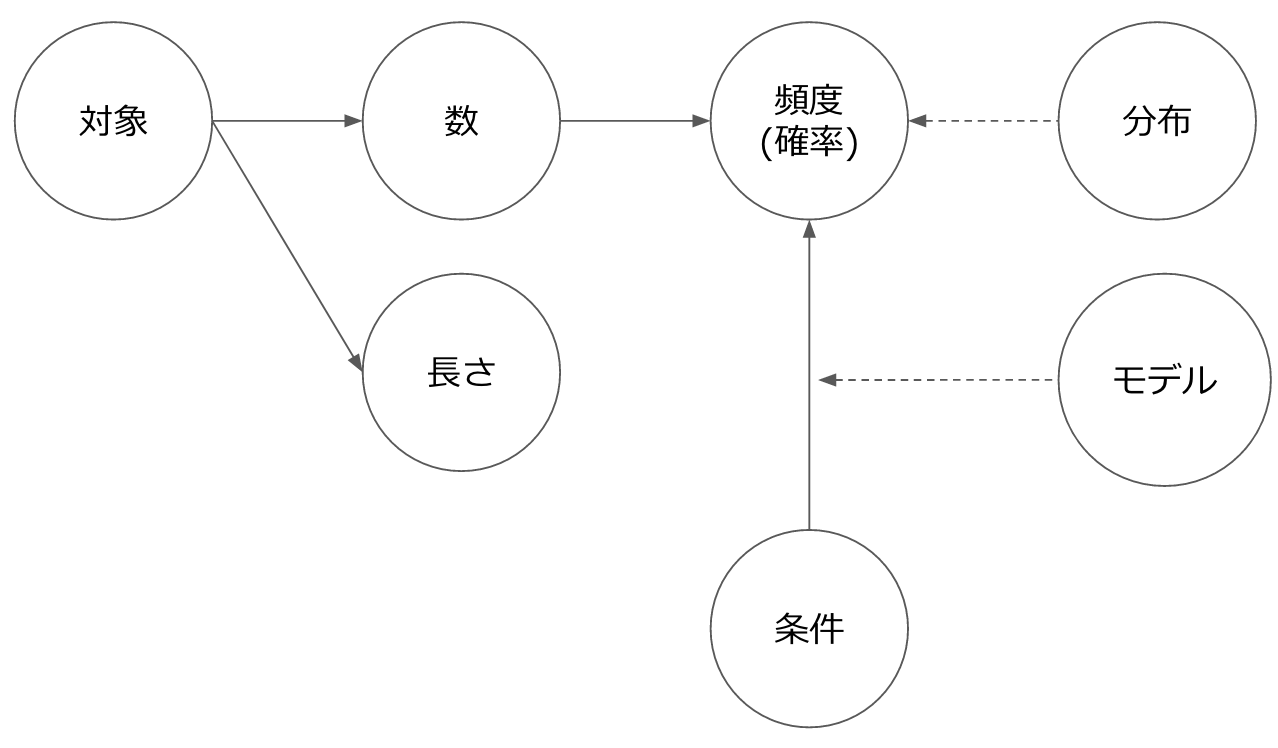
L'image des caractéristiques en langage naturel est essentiellement divisée en «longueur» ou «nombre». «Nombre» peut être dérivé comme «fréquence (probabilité)» en ajoutant une population et «probabilité conditionnelle» en ajoutant des conditions préalables.
En ce qui concerne les mots, j'ai fait le pré-traitement assez soigneusement cette fois (@Hironsan devrait expliquer ce domaine plus tard).
J'ai essayé d'utiliser le simple RandomForest en utilisant les fonctionnalités répertoriées. (RandomForest est également bon car vous pouvez facilement voir la contribution de chaque montant de fonctionnalité).
Voici le résultat de la création du modèle.
elephant_sense/notebooks/feature_test.ipynb

L'ensemble de données est petit, mais beaucoup plus précis. En regardant les fonctionnalités, ce qui suit semble bien fonctionner.
- image_count: nombre de chiffres
- phrase_max_length: Longueur maximale de la phrase
- user_followers_count: Nombre d'abonnés de l'utilisateur
Cela signifie: "Il est écrit par une personne fiable, il est écrit avec une longueur de phrase appropriée et il contient un chiffre." Surtout, la présence ou l'absence de la figure était très efficace. "Le nombre de followers des utilisateurs" est contraire à l'objectif de cette époque, et c'était initialement une politique de ne pas l'inclure en raison des caractéristiques uniques de Qiita, mais de la précision + des informations sur "écrivain" lors de son application à d'autres phrases à l'avenir J'ai décidé de le mettre car il peut être pris sous une forme ou une autre.
De plus, le résultat de la classification uniquement par les likes à comparer cette fois est le suivant.
elephant_sense/notebooks/like_based_classifier.ipynb

Si vous regardez ceci, vous pouvez voir que la phrase "facile à comprendre" (1) ne peut pas être prédite. En ce sens, ce modèle semble être plus utile que prévu.
Incorporation dans l'application
Créons une application qui peut réellement être utilisée en incorporant le modèle construit.
Lors de l'incorporation d'un modèle d'apprentissage automatique dans une application, l'objet de normalisation utilisé dans ce modèle (cette fois StandardScaler Notez que) est également obligatoire. Si vous étiez en train de normaliser lors de la création du modèle, vous devez naturellement normaliser lorsque vous faites des prédictions.
Le frontal est simple et construit avec Vue.js/axios. axios est une bibliothèque d'envoi de requêtes http, qui peut être utilisée côté serveur (Node) et dispose d'un solide support côté client (en particulier le support des cookies XSRF a été apprécié).
L'application terminée a été déployée sur Heroku. Puisque nous utilisons scicit-learn, etc. cette fois, le déploiement normal est difficile, nous déployons donc à l'aide de Docker.
Container Registry and Runtime
Jusqu'à présent, je devais devenir un artisan de buildpack, donc c'est pratique (mais c'est un peu pénible car il ne peut pas être utilisé depuis un environnement proxy).
L'application déployée est la suivante.
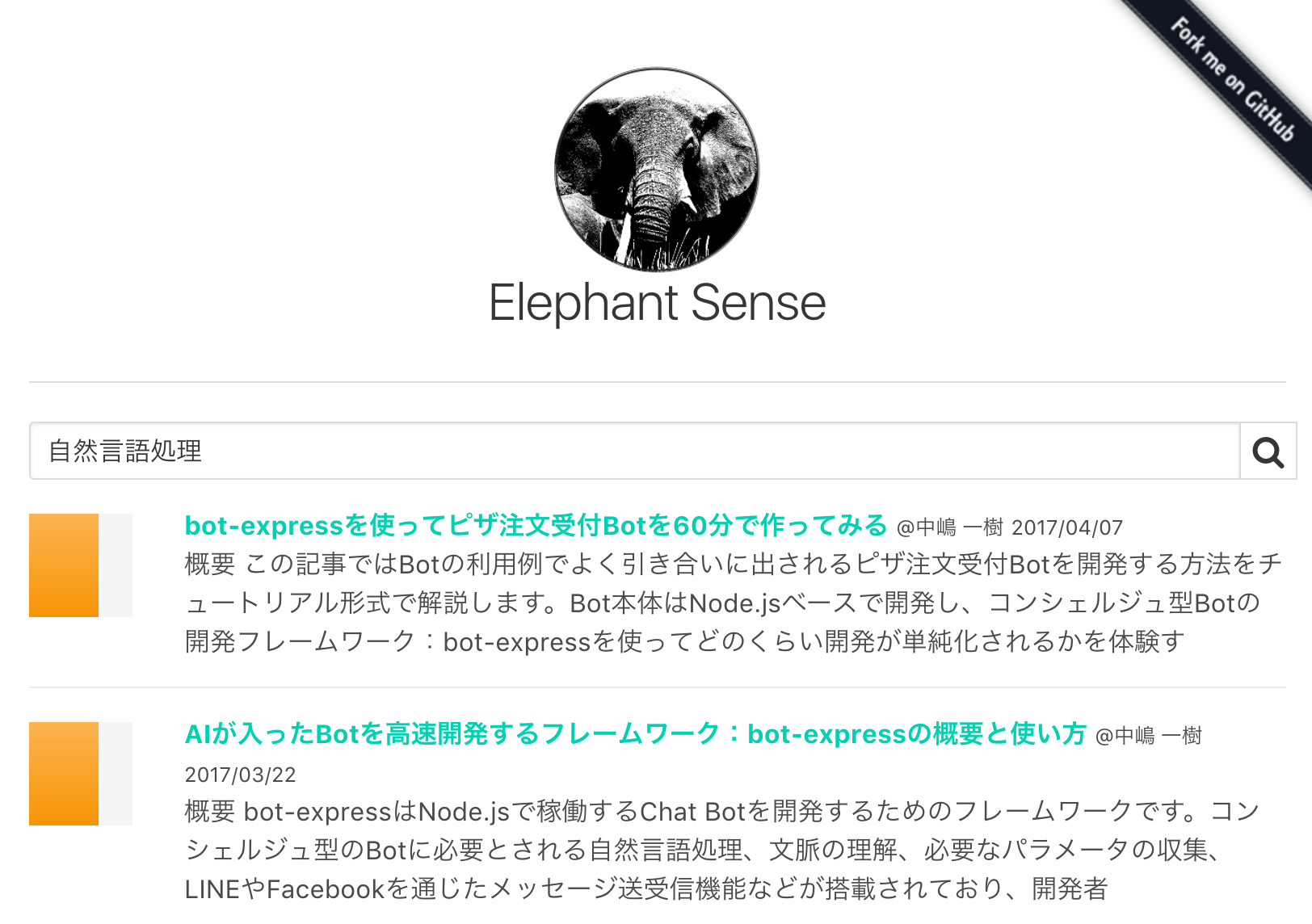
Mais ... lent! J'aimerais vraiment avoir plus de publications à évaluer, mais je le réduis en raison des performances (actuellement, je note et affiche 50 résultats de recherche). Je fais du traitement parallèle pour le moment, mais après tout, je fais l'analyse html de chaque phrase et l'extraction de fonctionnalités ... donc ce sera assez lent. Je pense que des améliorations sont nécessaires ici, y compris l'ingéniosité du côté frontal.
Quant au résultat de l'affichage, j'ai l'impression que tout va bien. Cependant, pour atteindre 50% de la cible, plusieurs phrases doivent être évaluées avant l'affichage, il y a donc deux faces d'une même pièce avec le problème de performance ci-dessus.
La balise metre est utilisée pour afficher le score. J'ai appris l'existence pour la première fois dans ce développement. Comme la balise progress, il y a des balises que je ne connais pas.
à partir de maintenant
J'ai l'impression d'avoir traversé une série de processus tels que la définition de problèmes, la collecte de données, la construction de modèles et l'application. Si cela évolue davantage, je pense que cela peut être appliqué à des documents de conception, des documents API, etc. pour améliorer la qualité des documents, et pour aider les nouveaux entrants à rechercher des phrases «bien organisées». ..
Actuellement, mon équipe chakki travaille sur "une société où chacun peut revenir à l'heure du thé (15h00)" par apprentissage automatique / traitement du langage naturel. Nous essayons de le réaliser. Tout d'abord, nous travaillons actuellement sur des informations en langage naturel (documents, revues, code source, etc.) dans le développement de systèmes.
 [@chakki_works](https://twitter.com/chakki_works)
[@chakki_works](https://twitter.com/chakki_works)
Si vous êtes intéressé, Venez écouter!
Recommended Posts