[Français] scikit-learn 0.18 Guide de l'utilisateur 1.16. Étalonnage des probabilités
google traduit http://scikit-learn.org/0.18/modules/calibration.html [scikit-learn 0.18 Guide de l'utilisateur 1. Apprentissage supervisé](http://qiita.com/nazoking@github/items/267f2371757516f8c168#1-%E6%95%99%E5%B8%AB%E4%BB%98 À partir de% E3% 81% 8D% E5% AD% A6% E7% BF% 92)
1.16. Étalonnage des probabilités
Lorsque vous effectuez des classifications, nous prédisons souvent non seulement les étiquettes de classe, mais aussi la probabilité de chaque étiquette. Cette probabilité donne une certaine confiance dans la prédiction. Certains modèles ont de mauvaises estimations des probabilités de classe, tandis que d'autres ne prennent pas en charge la prédiction probabiliste. Vous pouvez utiliser le module d'étalonnage pour mieux ajuster les probabilités d'un modèle particulier ou ajouter la prise en charge de la prédiction probabiliste. Un classificateur bien calibré est un classificateur probabiliste qui peut directement interpréter la sortie de la méthode predict_proba comme un niveau de confiance. Par exemple, environ 80% des échantillons ayant une valeur prédire_proba de 0,8 par un classificateur (binaire) bien calibré appartiennent en fait à la classe positive. Le graphique suivant compare dans quelle mesure les prédictions probabilistes des différents classificateurs sont calibrées.
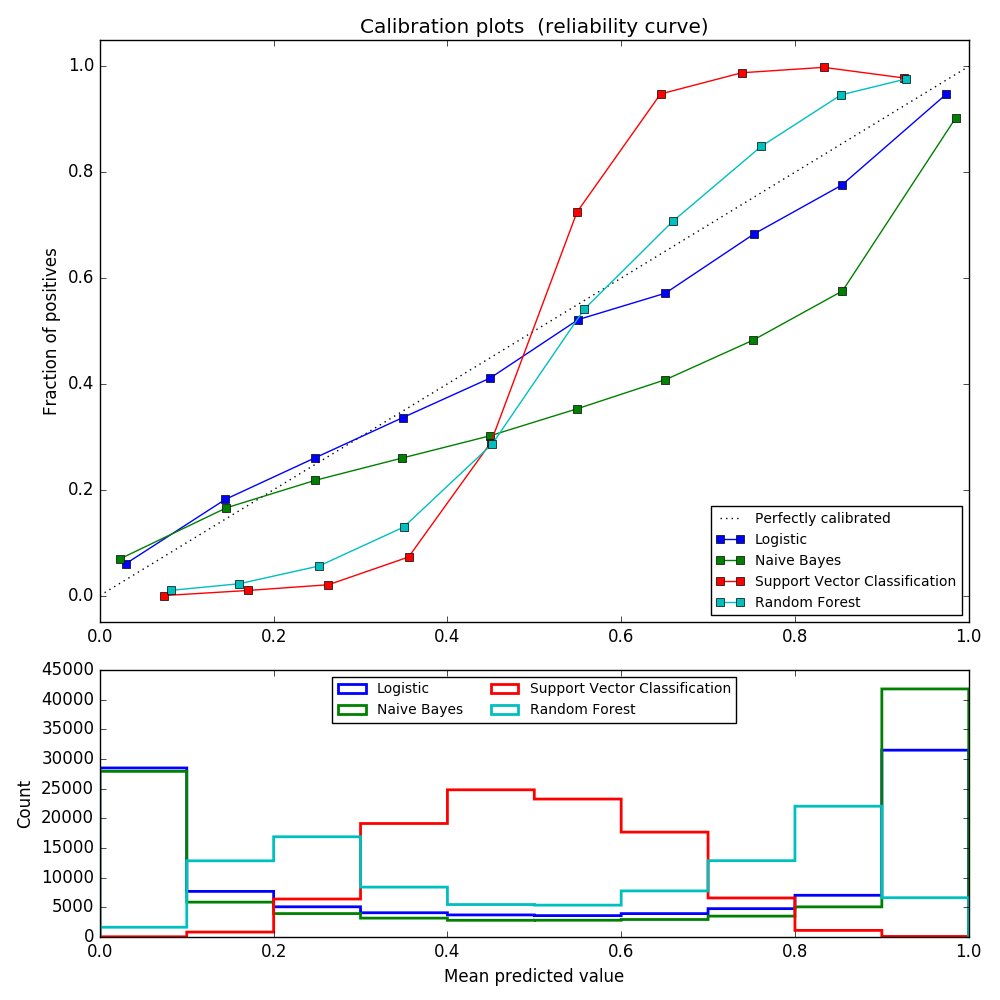
LogisticRegression () renvoie une prédiction correctement calibrée par défaut pour l'optimisation directe de la perte de journal. En revanche, d'autres méthodes renvoient une probabilité biaisée. Chaque méthode a un biais différent:
- GaussianNB a tendance à pousser la probabilité à 0 ou 1 (notez le nombre d'histogrammes). Cela est dû à l'hypothèse que les fonctionnalités sont conditionnellement indépendantes lorsqu'elles sont attribuées à la classe. Ce n'est pas le cas pour cet ensemble de données contenant deux entités redondantes.
- RandomForestClassifier montre le comportement opposé. L'histogramme montre des pics avec une probabilité d'environ 0,2 et 0,9, et la probabilité d'être proche de 0 ou 1 est très rare. Ceci est expliqué par Niculescu-Mizil et Caruana [4]. «Les méthodes de calcul de la moyenne des prédictions à partir de l'ensemble de base de modèles, tels que l'ensachage et les forêts aléatoires, biaisent les prédictions selon lesquelles la variance du modèle de base sous-jacent devrait s'approcher de 0 ou 1 à partir de ces valeurs, donc fixées à 0 et 1. Comme les prédictions sont limitées à l'intervalle [0,1], l'erreur due à la variance a tendance à être d'un côté proche de 0 et 1. Par exemple, le modèle est pour un cas. Si vous avez besoin de prédire p = 0, la seule façon dont l'ensachage peut y parvenir est que tous les arbres buggy prédisent zéro. Ajouter du bruit à un arbre où l'ensachage est en moyenne, Ce bruit produit un arbre qui prédit des valeurs supérieures à 0 dans ce cas, ce qui fait que la prévision moyenne de l'ensemble d'arrière-plan s'éloigne de 0. Les arbres de niveau de base entraînés dans des forêts aléatoires sont des sous-ensembles de caractéristiques. Cet effet est le plus fortement observé dans les forêts aléatoires en raison de sa dispersion relativement importante. " En conséquence, la courbe d'étalonnage montre une forme sigmoïde caractéristique, indiquant que le classificateur peut s'appuyer davantage sur son «intuition» et renvoyer généralement une probabilité proche de 0 ou 1.
- La classification des vecteurs de support linéaire (LinearSVC) fournit une courbe sigmoïde plus grande en tant que RandomForestClassifier. indiquer. Ceci est courant avec la méthode de la marge maximale (par rapport à Niculescu-Mizil et Caruana [4]), qui se concentre sur des échantillons durs proches de la limite de décision.
Deux approches pour effectuer un étalonnage de prédiction probabiliste: une approche paramétrique basée sur le modèle sigmoïde de Pratt et une régression isotonique (sklearn.isotonic) ) Est fourni comme une approche non paramétrique. Vous devez effectuer un étalonnage probabiliste sur de nouvelles données qui ne seront pas utilisées pour l'ajustement du modèle. CalibratedClassifierCV La classe est un modèle sur l'échantillon d'apprentissage à l'aide du générateur de validation croisée. Estimez chaque division des paramètres et l'étalonnage de l'échantillon d'essai. Ensuite, les probabilités attendues pour le pli sont moyennées. Les classificateurs déjà installés peuvent être étalonnés par CalibratedClassifierCV via le paramètre cv =" prefit ". Dans ce cas, l'utilisateur doit noter manuellement que les données d'ajustement et d'étalonnage du modèle sont discontinues.
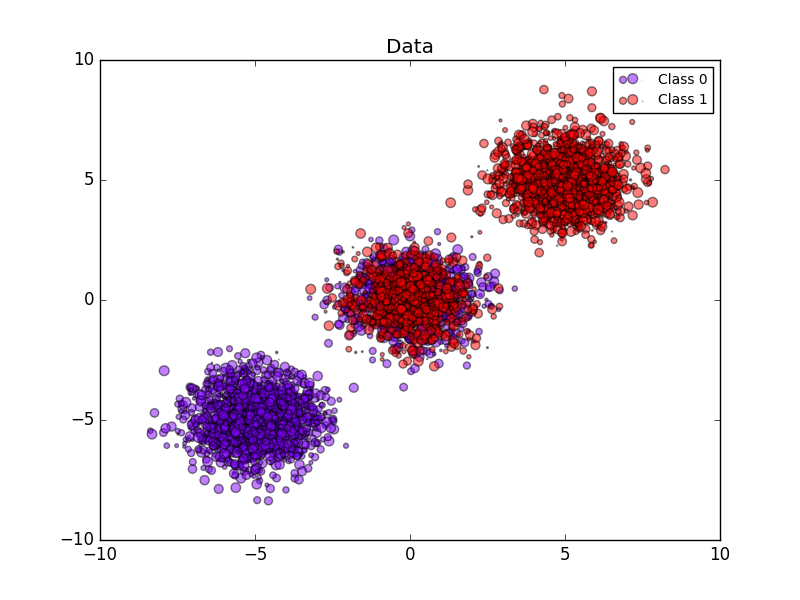
L'image suivante montre les avantages de l'étalonnage stochastique. La première image montre deux classes et trois morceaux de l'ensemble de données. Le bloc central contient un échantillon aléatoire de chaque classe. La probabilité d'un échantillon de cette masse doit être de 0,5.
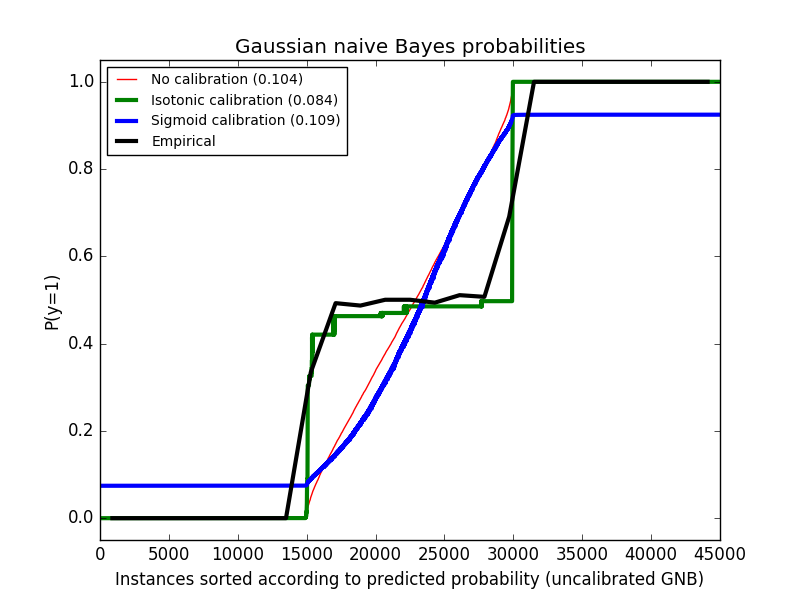
L'image suivante montre des données supérieures à la probabilité estimée à l'aide du classificateur Bayes naïf gaussien non étalonné, de l'étalonnage sigmoïde et de l'étalonnage isotonique non paramétrique. On peut observer que le modèle non paramétrique fournit l'estimation de probabilité la plus précise pour l'échantillon central, 0,5.
L'expérience suivante est réalisée sur un ensemble de données artificielles pour la classification binaire avec 100 000 échantillons avec 20 caractéristiques (1 000 échantillons sont utilisés pour l'ajustement du modèle). Sur les 20 fonctionnalités, seules 2 sont utiles et 10 sont redondantes. Cette figure montre les probabilités estimées obtenues avec un SVC linéaire avec à la fois une régression logistique, un classificateur de vecteur de support linéaire (SVC) et des étalonnages isotoniques et sigmoïdes. Les performances de l'étalonnage sont évaluées par le score de Brier brier_score_loss et rapportées dans la légende ( Plus petit est meilleur).
On voit ici que la régression logistique est calibrée car ses courbes sont presque diagonales. La ligne d'étalonnage SVC linéaire a une courbe sigmoïde, qui est unique aux classificateurs «sûrs». Pour LinearSVC, cela est dû à la propriété margin de la perte de charnière. Cela permet au modèle de se concentrer sur des échantillons durs (vecteurs de support) près de la limite de décision. Les deux types d'étalonnage résolvent ce problème et donnent presque les mêmes résultats. La figure suivante montre une courbe d'étalonnage Gaussian Naive Bayes sur les mêmes données, avec et sans les deux types d'étalonnage.
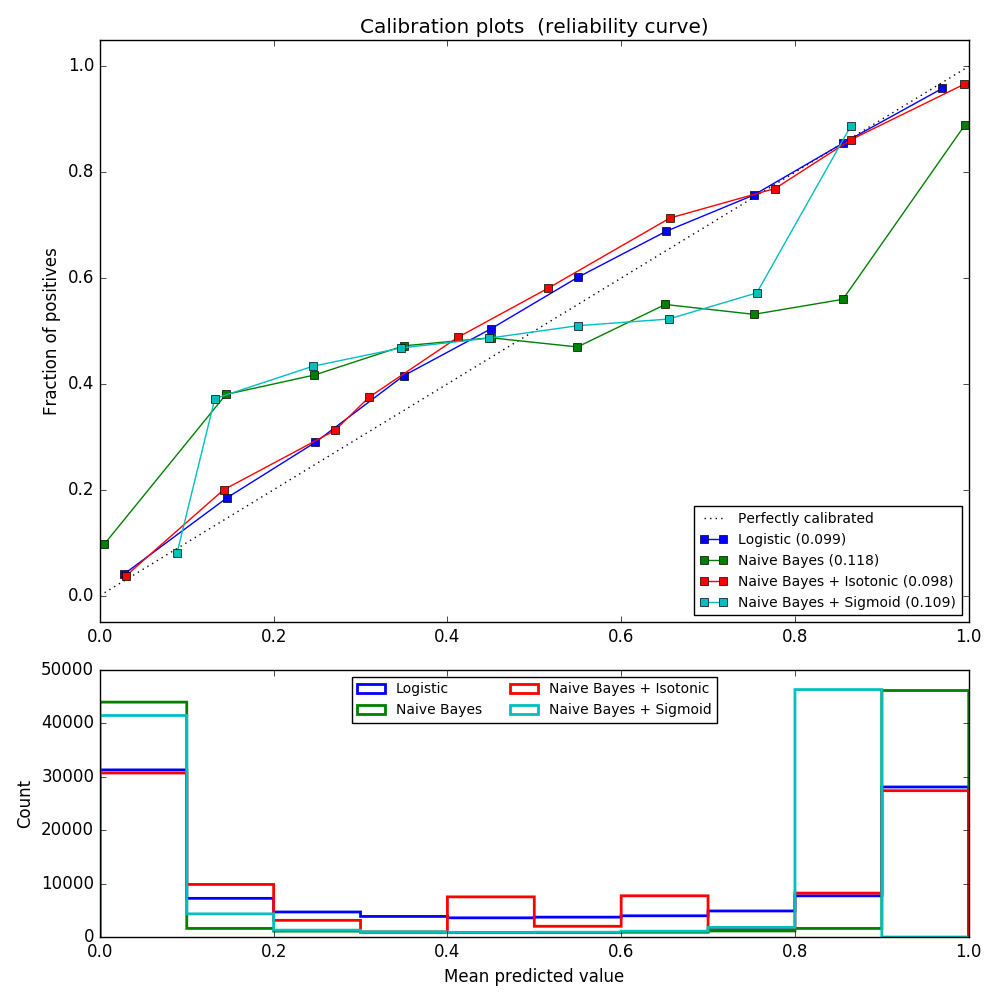
Le Bayes naïf gaussien donne de très mauvais résultats, mais il s'avère que cela se fait autrement que par SVC linéaire. Le SVC linéaire montre une courbe d'étalonnage sigmoïde, tandis que la courbe d'étalonnage de Bayes naïve gaussienne a une forme sigmoïde transposée. Ceci est courant avec les classificateurs trop optimistes. Dans ce cas, l'excès de confiance du classificateur est causé par des fonctionnalités redondantes qui violent l'hypothèse Naive Bayes indépendante de la fonctionnalité. L'étalonnage de probabilité de régression isotonique de Bayes naïf gaussien peut corriger ce problème, comme le montrent les courbes d'étalonnage presque diagonales. L'étalonnage Sigmaid n'est pas aussi puissant que l'étalonnage isotonique non paramétrique, mais il améliore légèrement le score de Brier. C'est une limitation essentielle de l'étalonnage sigmoïde, et sa forme paramétrique suppose des sigmoïdes plutôt que des courbes sigmoïdes transposées. Cependant, le modèle d'étalonnage isotonique non paramétrique ne fait pas des hypothèses aussi solides et peut traiter n'importe quelle forme avec des données d'étalonnage suffisantes. En général, l'étalonnage sigmoïde est préféré lorsque la courbe d'étalonnage est sigmoïde et les données d'étalonnage sont limitées, mais l'étalonnage isotonique est préféré dans les situations où une grande quantité de données est disponible pour les courbes d'étalonnage et l'étalonnage non sigmoïdes. CalibratedClassifierCV est plus d'un si l'estimation de base le peut. Il peut également gérer les tâches de classification qui incluent des classes. Dans ce cas, le classificateur est calibré individuellement d'une manière différente pour chaque classe. Lors de la prédiction de la probabilité de données invisibles, la probabilité calibrée de chaque classe est prédite séparément. Comme leurs probabilités ne correspondent pas toujours à 1, un post-traitement est effectué pour les normaliser. L'image suivante montre comment l'étalonnage sigmoïde modifie la probabilité prédictive d'un problème de classification à trois classes. Un exemple est un simplex standard 2 avec 3 coins correspondant à 3 classes. La flèche pointe du vecteur de probabilité prédit par le classifieur non étalonné au vecteur de probabilité prédit par le même classifieur après l'étalonnage sigmoïde de l'ensemble de validation d'exclusion. La couleur indique la vraie classe de l'instance (rouge: classe 1, vert: classe 2, bleu: classe 3).
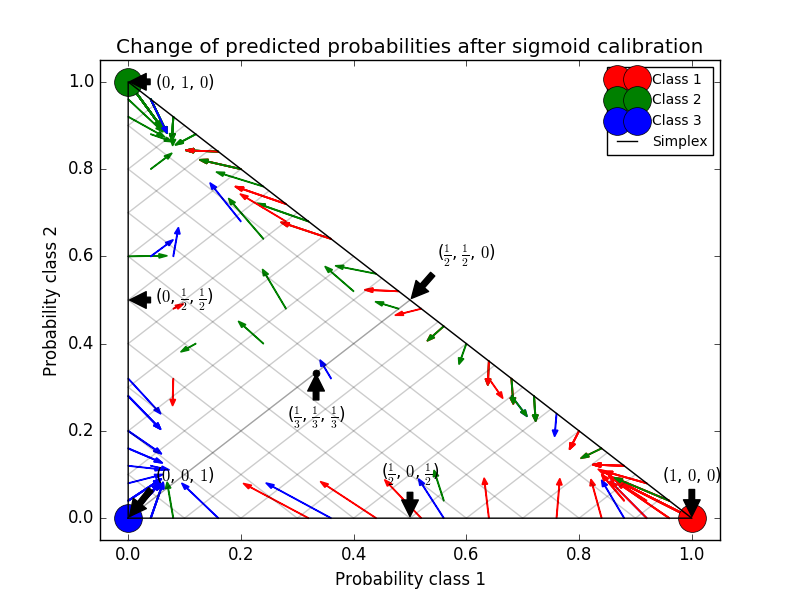
Le classificateur de base est un classificateur de forêt aléatoire avec 25 estimateurs de base (arbres). Si ce classificateur est entraîné sur les 800 points de données d'entraînement, les prédictions sont trop fiables et entraînent des pertes de journaux significatives. Sur les 200 points de données restants, le calibrage du même classificateur entraîné à 600 points de données avec method = 'sigmoid' réduit la fiabilité de la prédiction, c'est-à-dire le bord du simplexe. Déplacez le vecteur de probabilité du centre.
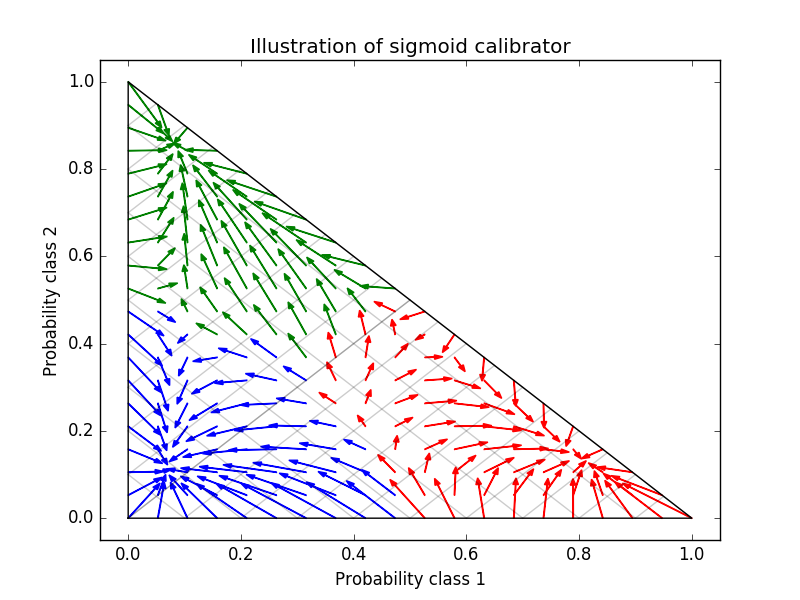
Cet étalonnage entraîne une perte de journal plus faible. À noter que l'alternative était d'augmenter le nombre d'estimations de base qui entraînerait une réduction similaire de la perte logarithmique.
- Les références:
- [1] Obtenir des estimations probabilistes calibrées à partir d'arbres de décision et de classificateurs bayésiens naïfs, B. Zadrozny & C. Elkan, ICML 2001
- [2] Convertir les scores du classificateur en estimations précises de probabilité multiclasse, B. Zadrozny et C. Elkan, (KDD 2002)
- [3] Comparaison de la sortie probabiliste de la machine à vecteurs de support avec la méthode de vraisemblance normalisée, J. Platt, (1999)
- [4] Prédiction de bonne probabilité par apprentissage supervisé, A. Niculescu-Mizil & R. Caruana, ICML 2005
[scikit-learn 0.18 Guide de l'utilisateur 1. Apprentissage supervisé](http://qiita.com/nazoking@github/items/267f2371757516f8c168#1-%E6%95%99%E5%B8%AB%E4%BB%98 À partir de% E3% 81% 8D% E5% AD% A6% E7% BF% 92)
© 2010 --2016, développeurs scikit-learn (licence BSD).
Recommended Posts