Make ASCII art with deep learning
Nice to meet you. The main business is called Oscii Art, an ASCII art (AA) craftsman (not the main business). Watching the game between AlphaGo and Lee Sedol, I thought "** I also want to defeat the God AA craftsman with deep learning! **", so I installed python and wrote the results for just one year.
The code is up here. https://github.com/OsciiArt/DeepAA
What is ASCII art handled here?
What is AA used here?
This is ... ↓
 Not like this ... ↓
Not like this ... ↓
 Not like this ... ↓
Not like this ... ↓
 It ’s a little different, like this …… ↓
It ’s a little different, like this …… ↓
 But of course, it's like this. ↓
But of course, it's like this. ↓

Here, we will deal with a type of AA called "** Trace AA **" that reproduces a line art by making characters. See the "Proportional Fonts" section of the "ASCII Art" page on wikipedia for more information.
[wikipedia: ASCII Art-Proportional Fonts](https://ja.wikipedia.org/wiki/%E3%82%A2%E3%82%B9%E3%82%AD%E3%83%BC%E3%82% A2% E3% 83% BC% E3% 83% 88 # .E3.83.97.E3.83.AD.E3.83.9D.E3.83.BC.E3.82.B7.E3.83.A7.E3. 83.8A.E3.83.AB.E3.83.95.E3.82.A9.E3.83.B3.E3.83.88.E3.81.AE.E3.82.82.E3.81.AE)
The conditions such as fonts are the specifications of 2channel,
--MS Gothic --Size 16 pixels --2 pixels between lines
Is widely adopted.
Good or bad of ASCII art
There are many misunderstandings, but as a premise, AA is basically ** handwritten **. (An example of misunderstanding: Yahoo Answers: I see AA ASCII art in 2channel, how do I make it?)
There are some software that automatically creates AA, but the current situation is that it is far from human handwriting. One thing to keep in mind when deciding whether AA is good or bad is ** size **. If you make it infinitely large, one character can represent one pixel and the original image can be completely reproduced (even with software). Instead, AA that expresses more lines with one character and keeps the size small is a good AA.
In other words, the good or bad of AA
** Reproducibility of original image ÷ Size **
Can be defined as.
Training data
Learning deep learning requires a large number of original image and AA pairs. However, AA is basically not announced as a pair with the original image. Therefore, it is difficult to collect data. In addition, AA often deforms the lines of the original image significantly, and even if a pair is obtained, it is expected that learning will be difficult. Therefore, this time, we generated what seems to be the original image from AA and used it as training data. The approach in this area was based on the research by Simocera Edgar et al. (Automatic line drawing of rough sketches). ..
procedure
- Image AA.
 2. This is far from the actual line art, so use the web service Automatic line art of rough sketches by Simocera Edgar et al. Make it look like a line art.
2. This is far from the actual line art, so use the web service Automatic line art of rough sketches by Simocera Edgar et al. Make it look like a line art.
 3. Cut out the image in 64 x 64 pixels and use the characters corresponding to the central 16 x 16 area as the correct label.
3. Cut out the image in 64 x 64 pixels and use the characters corresponding to the central 16 x 16 area as the correct label.
 4. This process was performed on about 200 AAs and used as training data.
4. This process was performed on about 200 AAs and used as training data.
Learning
The framework used was Keras (backend: TensorFlow). For the network, we used a standard convolutional neural network for classification. The code is shown below.
def DeepAA(num_label=615, drop_out=0.5, weight_decay=0.001, input_shape = [64, 64]):
"""
Build Deep Neural Network.
:param num_label: int, number of classes, equal to candidates of characters
:param drop_out: float
:param weight_decay: float
:return:
"""
reg = l2(weight_decay)
imageInput = Input(shape=input_shape)
x = Reshape([input_shape[0], input_shape[1], 1])(imageInput)
x = GaussianNoise(0.1)(x)
x = Convolution2D(16, 3, 3, border_mode='same', W_regularizer=reg, b_regularizer=reg, init=normal)(x)
x = BatchNormalization(axis=-3)(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2), border_mode='same')(x)
x = Dropout(drop_out)(x)
x = Convolution2D(32, 3, 3, border_mode='same', W_regularizer=reg, b_regularizer=reg, init=normal)(x)
x = BatchNormalization(axis=-3)(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2), border_mode='same')(x)
x = Dropout(drop_out)(x)
x = Convolution2D(64, 3, 3, border_mode='same', W_regularizer=reg, b_regularizer=reg, init=normal)(x)
x = BatchNormalization(axis=-3)(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2), border_mode='same')(x)
x = Dropout(drop_out)(x)
x = Convolution2D(128, 3, 3, border_mode='same', W_regularizer=reg, b_regularizer=reg, init=normal)(x)
x = BatchNormalization(axis=-3)(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2), border_mode='same')(x)
x = Flatten()(x)
x = Dropout(drop_out)(x)
y = Dense(num_label, activation='softmax')(x)
model = Model(input=imageInput, output=y)
return model
Learning conditions
--Number of data: 484654 --Batch size: 128 --Learning count: 20,000 batches --Loss function: cross entropy --Optimization function: Adam
With the above settings, I trained on a machine without GPU for about 2 days.
result
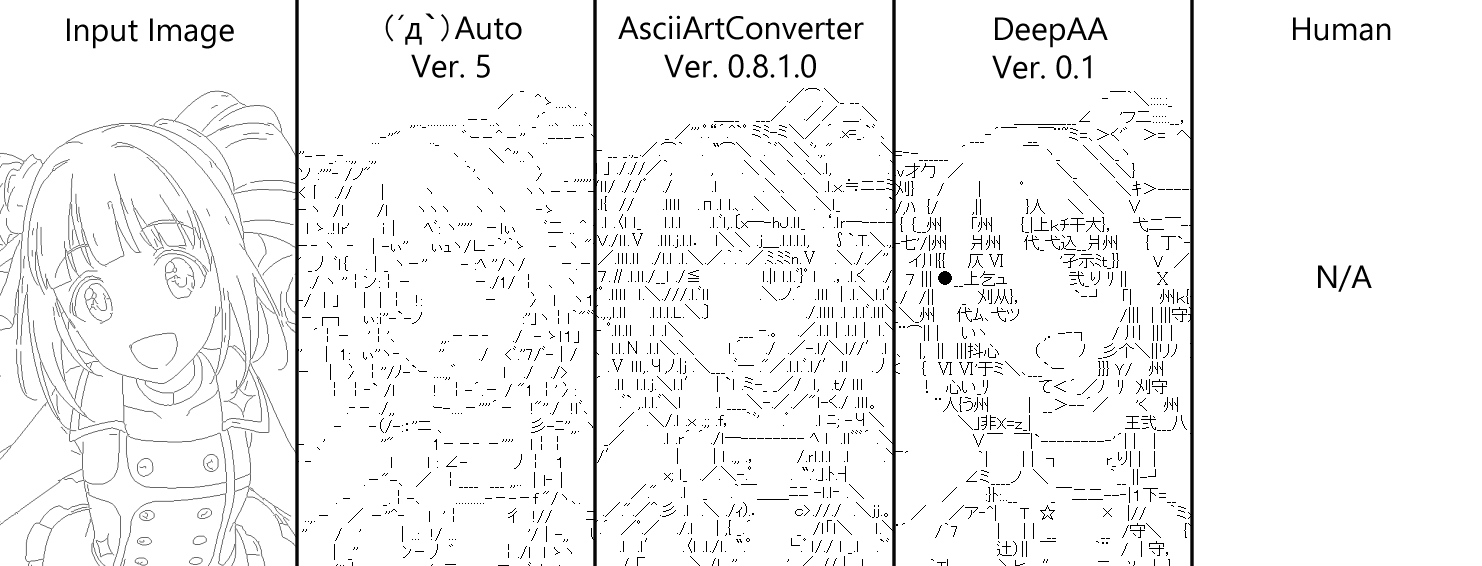
Here is a comparison with some other AA automatic creation software ↓

--Input Image: Original image -(´д `) Auto: Creator --kuronowish, where to get it-(´д `) Edit Saitama Sales Office Evacuation Center --AsciiArtConverter: Creator --Mr. Uryu P, Where to get it-- test --DeepAA: Proposed method of this article (hereinafter referred to as DeepAA) --Human: Handwritten AA
The size settings are the same as those selected during handwriting. Conversion is the default setting for all software. All software is a little side-by-side by default because it is a matter of trial and error to improve the settings. I think that the proposed method is a little superior in the ability to select characters that fit perfectly in the part where the line is complicated.
Another point for comparison ↓
 This is unified with the size that was output well by the proposed method. Therefore, it is a comparison of patronage.
However, DeepAA is particularly good at making eyes, and I think that it is possible to select characters that are as good as humans.
This is unified with the size that was output well by the proposed method. Therefore, it is a comparison of patronage.
However, DeepAA is particularly good at making eyes, and I think that it is possible to select characters that are as good as humans.
I will post some examples below.
 As a rule of thumb, it is easier to get better results if the line art is made thinner.
As a rule of thumb, it is easier to get better results if the line art is made thinner.
 Even if you dare to output the solid as it is without thinning it, you will get interesting results.
Even if you dare to output the solid as it is without thinning it, you will get interesting results.
 What do you think.
What do you think.
Task
I think that the accuracy was higher than that of the existing automatic AA creation software, but the result was still far from the accuracy of handwritten AA. The issues for improvement are described below.
Misalignment
At present, I think the biggest weakness of DeepAA compared to handwriting is the gap. Unlike monospaced fonts, which have a constant character width, we are dealing with proportional fonts in which the character width differs for each character. In the case of monospaced fonts, where the characters fit in the image is uniquely determined, but in proportional fonts, the position can be adjusted by the combination of characters.
For example, in the example of ↓, the DeepAA line is rattling in the part surrounded by blue, but if a person modifies it, it can be aligned as shown on the right. (Adjust by a combination of full-width space (width 11 pixels), half-width space (width 5 pixels), period (width 3 pixels).)
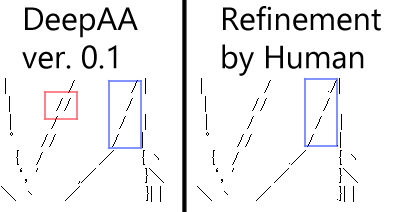 Also, in the area surrounded by red, the "/" is applied twice, but the correct answer is clearly to apply one "/" in the position between the two "/".
The problem is that at the stage of training data, it is decided where to apply the characters to "** where ", and then only the characters to be applied to " what **" are learned. However, I honestly can't think of how to learn "where".
Also, in the area surrounded by red, the "/" is applied twice, but the correct answer is clearly to apply one "/" in the position between the two "/".
The problem is that at the stage of training data, it is decided where to apply the characters to "** where ", and then only the characters to be applied to " what **" are learned. However, I honestly can't think of how to learn "where".
Line art
Since I use a web service to make line art of AA images, it is a bottleneck when I earn a lot of data, so I would like to consider an alternative.
Number of learning
Until now, I used to train only with the CPU, but since I recently prepared the GPU environment, I would like to try training more times with a more complicated model.
Recommended Posts