[Introduction à minimiser] Analyse des données avec le modèle SEIR ♬
En préparation de l'analyse des données du COVID-19, nous expliquerons comment générer le graphique suivant.
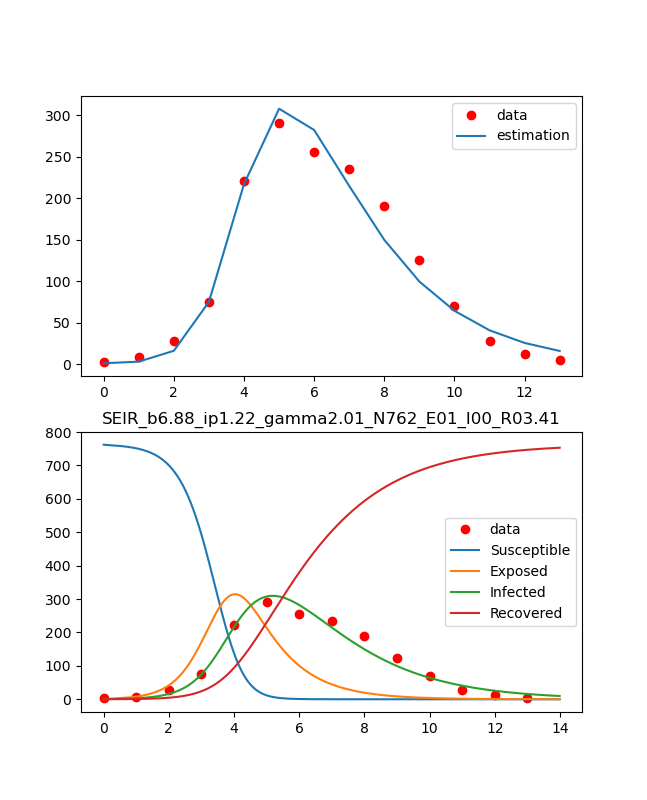
Cette figure est une figure dans laquelle le modèle SEIR de maladie infectieuse est ajusté aux données données en utilisant minimiser @ scipy.
 La méthode est presque comme ci-dessous. Les deux ont été utiles à bien des égards.
【référence】
① Début du modèle mathématique des maladies infectieuses: aperçu du modèle SEIR par Python et introduction à l'estimation des paramètres
② Modèle de prédiction mathématique des maladies infectieuses (modèle SIR): étude de cas (1)
③ J'ai essayé de prédire le comportement du nouveau virus corona avec le modèle SEIR.
La méthode est presque comme ci-dessous. Les deux ont été utiles à bien des égards.
【référence】
① Début du modèle mathématique des maladies infectieuses: aperçu du modèle SEIR par Python et introduction à l'estimation des paramètres
② Modèle de prédiction mathématique des maladies infectieuses (modèle SIR): étude de cas (1)
③ J'ai essayé de prédire le comportement du nouveau virus corona avec le modèle SEIR.
Ce que j'ai fait
・ Explication du code ・ Essayez le montage avec le modèle SIR et le modèle SEIR ・ Autres modèles
・ Explication du code
Le code complet est ci-dessous. ・ Collective_particles / minimiser_params.py Je laisserai l'explication à la référence ci-dessus, et ici je vais expliquer le code utilisé cette fois. Les données ont été utilisées à partir de la référence (2). Aussi, pour le code de minimisation, j'ai fait référence à Reference ①. La Lib à utiliser est la suivante. Cette fois, il est implémenté dans l'environnement keras-gpu de l'environnement conda de Windows 10, mais il est précédemment installé y compris scipy.
#include package
import numpy as np
from scipy.integrate import odeint
from scipy.optimize import minimize
import matplotlib.pyplot as plt
L'équation différentielle du modèle SEIR est définie ci-dessous. Ici, ce qu'il faut faire avec N sera décidé comme il convient, mais dans cette proposition, N = 763 personnes de l'article publié dans Reference (2), qui a été corrigé. L'équation différentielle du modèle SEIR est la suivante Ici, dans la référence (1), N est poussé dans la variable bêta et n'est pas exprimé explicitement, mais la formule suivante est plus facile à comprendre en termes de Wan. Ce qui suit est cité de la référence ③.
{\begin{align}
\frac{dS}{dt} &= -\beta \frac{SI}{N} \\
\frac{dE}{dt} &= \beta \frac{SI}{N} -\epsilon E \\
\frac{dI}{dt} &= \epsilon E -\gamma I \\
\frac{dR}{dt} &= \gamma I \\
\end{align}
}
Si vous regardez ce qui suit tout en regardant ce qui précède, vous pouvez le comprendre car c'est juste.
#define differencial equation of seir model
def seir_eq(v,t,beta,lp,ip):
N=763
a = -beta*v[0]*v[2]/N
b = beta*v[0]*v[2]/N-(1/lp)*v[1]
c = (1/lp)*v[1]-(1/ip)*v[2]
d = (1/ip)*v[2]
return [a,b,c,d]
Tout d'abord, une solution est obtenue sur la base de la valeur initiale sous forme d'équation différentielle ordinaire.
#solve seir model
N,S0,E0,I0=762,0,1,0
ini_state=[N,S0,E0,I0]
beta,lp,ip=6.87636378, 1.21965986, 2.01373496 #2.493913 , 0.95107715, 1.55007883
t_max=14
dt=0.01
t=np.arange(0,t_max,dt)
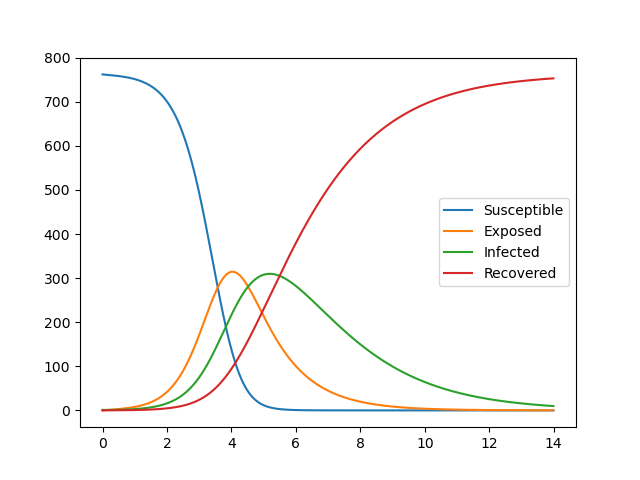
plt.plot(t,odeint(seir_eq,ini_state,t,args=(beta,lp,ip))) #0.0001,1,3
plt.legend(['Susceptible','Exposed','Infected','Recovered'])
plt.pause(1)
plt.close()
Les résultats sont les suivants: Si vous estimez et modifiez les paramètres ici, vous pouvez ajuster approximativement, mais c'est difficile pour les paramètres compliqués.
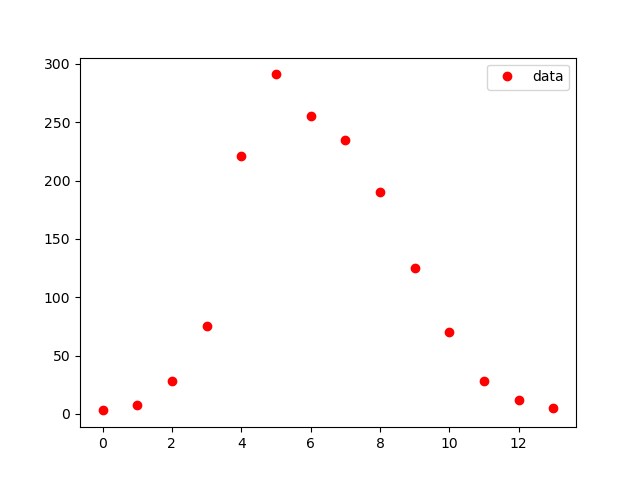
 Comme indiqué dans la référence (2), remplacez les données et affichez-les dans le graphique comme indiqué ci-dessous.
Comme indiqué dans la référence (2), remplacez les données et affichez-les dans le graphique comme indiqué ci-dessous.
#show observed i
#obs_i=np.loadtxt('fitting.csv')
data_influ=[3,8,28,75,221,291,255,235,190,125,70,28,12,5]
data_day = [1,2,3,4,5,6,7,8,9,10,11,12,13,14]
obs_i = data_influ
plt.plot(obs_i,"o", color="red",label = "data")
plt.legend()
plt.pause(1)
plt.close()
Le résultat est le suivant, et comme il s'agit d'une sortie pour confirmation en cours de route, l'en-tête, etc.
 Maintenant, le suivant est la partie estimation. Cette fonction d'évaluation calcule avec une équation différentielle en utilisant la valeur de l'argument et renvoie le résultat de l'évaluation.
Maintenant, le suivant est la partie estimation. Cette fonction d'évaluation calcule avec une équation différentielle en utilisant la valeur de l'argument et renvoie le résultat de l'évaluation.
#function which estimate i from seir model func
def estimate_i(ini_state,beta,lp,ip):
v=odeint(seir_eq,ini_state,t,args=(beta,lp,ip))
est=v[0:int(t_max/dt):int(1/dt)]
return est[:,2]
La fonction de vraisemblance logarithmique est définie comme suit.
- Reportez-vous à la référence ① Fondamentalement, le problème est de changer les paramètres pour trouver la valeur maximale de cette fonction de vraisemblance logarithmique. (En fait, c'est un problème de minimisation en prenant un moins)
- Ici, la valeur absolue est prise pour éviter que l'argument du journal ne devienne négatif.
#define logscale likelihood function
def y(params):
est_i=estimate_i(ini_state,params[0],params[1],params[2])
return np.sum(est_i-obs_i*np.log(np.abs(est_i)))
Utilisez la fonction de réduction de Scipy ci-dessous pour trouver la valeur maximale.
#optimize logscale likelihood function
mnmz=minimize(y,[beta,lp,ip],method="nelder-mead")
print(mnmz)
La sortie est la suivante
>python minimize_params.py
final_simplex: (array([[6.87640764, 1.21966435, 2.01373196],
[6.87636378, 1.21965986, 2.01373496],
[6.87638203, 1.2196629 , 2.01372646],
[6.87631916, 1.21964456, 2.0137297 ]]), array([-6429.40676091, -6429.40676091, -6429.40676091, -6429.4067609 ]))
fun: -6429.406760912483
message: 'Optimization terminated successfully.'
nfev: 91
nit: 49
status: 0
success: True
x: array([6.87640764, 1.21966435, 2.01373196])
Retirez beta_const, lp, gamma_const du résultat du calcul comme suit, et calculez R0 ci-dessous. Il s'agit du nombre de reproductions de base, qui est un guide pour la propagation de l'infection.Si R0 <1, il ne se propage pas, mais si R0> 1, il se propage et est un indice indiquant le degré.
#R0
beta_const,lp,gamma_const = mnmz.x[0],mnmz.x[1],mnmz.x[2] #Taux d'infection, temps d'attente d'infection, taux d'élimination (taux de récupération)
print(beta_const,lp,gamma_const)
R0 = beta_const*(1/gamma_const)
print(R0)
Cette fois, c'est comme suit, et depuis R0 = 3,41, l'infection s'est propagée.
6.876407637532918 1.2196643491443309 2.0137319643699927
3.4147581501415165
Le résultat ainsi obtenu est affiché sur le graphique.
#plot reult with observed data
fig, (ax1,ax2) = plt.subplots(2,1,figsize=(1.6180 * 4, 4*2))
lns1=ax1.plot(obs_i,"o", color="red",label = "data")
lns2=ax1.plot(estimate_i(ini_state,mnmz.x[0],mnmz.x[1],mnmz.x[2]), label = "estimation")
lns_ax1 = lns1+lns2
labs_ax1 = [l.get_label() for l in lns_ax1]
ax1.legend(lns_ax1, labs_ax1, loc=0)
lns3=ax2.plot(obs_i,"o", color="red",label = "data")
lns4=ax2.plot(t,odeint(seir_eq,ini_state,t,args=(mnmz.x[0],mnmz.x[1],mnmz.x[2])))
ax2.legend(['data','Susceptible','Exposed','Infected','Recovered'], loc=0)
ax2.set_title('SEIR_b{:.2f}_ip{:.2f}_gamma{:.2f}_N{:d}_E0{:d}_I0{:d}_R0{:.2f}'.format(beta_const,lp,gamma_const,N,E0,I0,R0))
plt.savefig('./fig/SEIR_b{:.2f}_ip{:.2f}_gamma{:.2f}_N{:d}_E0{:d}_I0{:d}_R0{:.2f}_.png'.format(beta_const,lp,gamma_const,N,E0,I0,R0))
plt.show()
plt.close()
Le résultat est comme ci-dessus.
・ Autres modèles
Lorsque je faisais ce calcul, j'ai trouvé un modèle SIR légèrement plus simple et un modèle légèrement plus compliqué, donc je vais les résumer. Le modèle SIR est le suivant car c'est un modèle qui ignore Exposed de S-E-I-R.
{\begin{align}
\frac{dS}{dt} &= -\beta \frac{SI}{N} \\
\frac{dI}{dt} &= \beta \frac{SI}{N} -\gamma I \\
\frac{dR}{dt} &= \gamma I \\
\end{align}
}
Vous pouvez comprendre la signification de $ R_0 $ en réécrivant comme suit.
{\begin{align}
\frac{dS}{dt} &= -R_0 \frac{S}{N} \frac{dR}{dt} \\
R_0 &= \frac{\beta}{\gamma}\\
\frac{dI}{dt} &= 0 \La personne infectée culmine à\\
R_0 &= \frac{\beta}{\gamma}= \frac{N}{S_0} \\
\end{align}
}
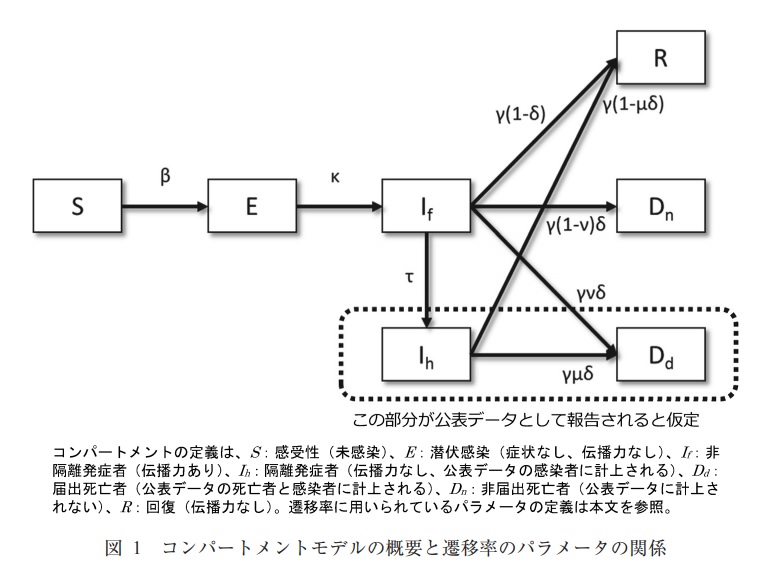
En revanche, dans une situation compliquée telle qu'une transition entre la mort et la mort sans notification, ce sera comme suit. On suppose que les morts ne contribuent pas à l'infection.
- COVID-19 peut ressembler à ceci
La figure est tirée du document suivant dans la référence ①
・ Analyse des épidémies d'infection à virus Ebola à l'aide d'un modèle mathématique

Résumé
-L'adaptation des données peut maintenant être effectuée automatiquement par minimiser @ scipy. ・ J'ai pu ajuster les données réelles avec le modèle SEIR
・ La prochaine fois, j'aimerais analyser les données de chaque pays du COVID-19.
Recommended Posts